Bài toán tìm đường đi ngắn nhất
Trong các ứng dụng thực tế, vài toán tìm đường đi ngắn nhất giữa hai đỉnh của một đồ thị liên thông có một ý nghĩa to lớn. Có thể dẫn về bài toán như vậy nhiều bài toán thực tế quan trọng. Ví dụ, bài toán chọn một hành trình tiết kiệm nhất (theo tiêu chuẩn hoặc khoảng cách hoặc thời gian hoặc chi phí) trên một mạng giao thông đường bộ, đường thủy hoặc đường không; bài toán chọn một phương pháp tiết kiệm nhất để đưa ra một hệ thống động lực từ trạng thái xuất phát đến trạng một trạng thái đích, bài toán lập lịch thi công các công các công đoạn trong một công trình thi công lớn, bài toán lựa chọn đường truyền tin với chi phí nhỏ nhất trong mạng thông tin, v.v… Hiện nay có rất nhiều phương pháp để giải các bài toán như vậy. Thế nhưng, thông thường, các thuật toán được xây dựng dựa trên cơ sở lý thuyết đồ thị tỏ ra là các thuật toán có hiệu quả cao nhất. Trong chương này chúng ta sẽ xét một số thuật toán như vậy.
Các khái niệm mở đầu
Trong bài này chúng ta chỉ xét đồ thị có hướng G =(V,E), |V|=n, |E|=m với các cung được gán trọng số, nghĩa là, mỗi cung (u,v) ∈ E của nó được đặt tương ứng với một số thực a(u,v) gọi là trọng số của nó. Chúng ta sẽ đặt a(u,v) = ∞ , nếu (u,v) ∉ E. Nếu dãy v0, v1, . . ., vp là một đường đi trên G, thì độ dài của nó được định nghĩa là tổng sau
tức là, độ dài của đường đi chính là tổng của các trọng số trên các cung của nó. (Chú ý rằng nếu chúng ta gán trọng số cho tất cả cung đều bằng 1, thì ta thu được định nghĩa độ dài của đường đi như là số cung của đường đi giống như trong các chương trước đã xét).
Bài toán tìm đường đi ngắn nhất trên đồ thị dưới dạng tổng quát có thể phát biểu như sau: tìm đường đi có độ dài nhỏ nhất từ một đỉnh xuất phát s ∈V đến đỉnh cuối (đích) t ∈ V. Đường đi như vậy ta sẽ gọi là đường đi ngắn nhất từ s đến t còn độ dài của nó ta sẽ ký hiệu là d(s,t) và còn gọi là khoảng cách từ s đến t (khoảng cách định nghĩa như vậy có thể là số âm). Nếu như không tồn tại đường đi từ s đến t thì ta sẽ đặt d(s,t) =∞ . Rõ ràng, nếu như mỗi chu trình trong đồ thị đều có độ dài dương, trong đường đi ngắn nhất không có đỉnh nào bị lặp lại (đường đi không có đỉnh lặp lại sẽ gọi là đường đi cơ bản). Mặt khác nếu trong đồ thị có chu trình với độ dài âm (chu trình như vậy để gọi ngắn gọn ta gọi là chu trình âm) thì khoảng cách giữa một số cặp đỉnh nào đó của đồ thị có thể là không xác định, bởi vì, bằng cách đi vòng theo chu trình này một số đủ lớn lần, ta có thể chỉ ra đường đi giữa các đỉnh này có độ dài nhỏ hơn bất cứ số thực cho trước nào. Trong những trường hợp như vậy, có thể đặt vấn đề tìm đường đi cơ bản ngắn nhất, tuy nhiên bài toán đặt ra sẽ trở nên phức tạp hơn rất nhiều, bởi vì nó chứa bài toán xét sự tồn tại đường đi Hamilton trong đồ thị như là một trường hợp riêng.
Trước hết cần chú ý rằng nếu biết khoảng cách từ s đến t, thì đường đi ngắn nhất từ s đến t, trong trường hợp trọng số không âm, có thể tìm được một cách dễ dàng. Để tìm đường đi, chỉ cần để ý là đối với cặp đỉnh s, t ∈ V tuỳ ý (s <> t) luôn tìm được đỉnh v sao cho
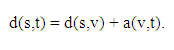
Thực vậy, đỉnh v như vậy chính là đỉnh đi trước đỉnh t trong đường đi ngắn nhất từ s đến t. Tiếp theo ta lại có thể tìm được đỉnh u sao cho d(s,v) = d(s,u) + a(u,v), . . . Từ giả thiết về tính không âm của các trọng số dễ dàng suy ra rằng dãy t, v, u, . . . không chứa đỉnh lặp lại và kết thúc ở đỉnh s. Rõ ràng dãy thu được xác định (nếu lật ngược thứ tự các đỉnh trong nó) đường đi ngắn nhất từ s đến t. Từ đó ta có thuật toán sau đây để tìm đường đi ngắn nhất từ s đến t khi biết độ dài của nó.
Procedure Find_Path;
(* Đầu vào:
D[v] - khoảng cách từ đỉnh s đến tất cả các đỉnh còn lại v ∈ V;
- đỉnh đích;
a[u,v], u, v ∈ V – ma trận trọng số trên các cung.
Đầu ra:
Mảng Stack chứa dãy đỉnh xác định đường đi ngắn nhất từ s đến t
*)
begin
stack:= ∅ ; stack ⇐ t; v:=t;
while v <> s do
begin
u:=đỉnh thoả mãn d[v]=d[u]+a[u,v];
stack ⇐ u;
v:=u;
end;
end;
Chú ý rằng độ phức tạp tính toán của thuật toán là O(n2), do để tìm đỉnh u ta phải xét qua tất cả các đỉnh của đồ thị. Tất nhiên, ta cũng có thể sử dụng kỹ thuật ghi nhận đường đi đã trình bày trong chương 3: dùng biến mảng Truoc[v], v∈ V, để ghi nhớ đỉnh đi trước v trong đường đi tìm kiếm.
Cũng cần lưu ý thêm là trong trường hợp trọng số trên các cạnh là không âm, bài toán tìm đường đi ngắn nhất trên đồ thị vô hướng có thể dẫn về bài toán trên đồ thị có hướng, bằng cách thay đổi mỗi cạnh của nó bởi nó bởi hai cung có hướng ngược chiều nhau với cùng trọng số là trọng số của các cạnh tương ứng. Tuy nhiên, trong trường hợp có trọng số âm, việc thay như vậy có thể dẫn đến chu trình âm.
Đường đi ngắn nhất xuất phát từ một đỉnh. Thuật toán ford-bellman
Phần lớn các thuật toán tìm khoảng cách giữa hai đỉnh s và t được xây dựng nhờ kỹ thuật tính toán mà ta có thể mô tả đại thể như sau: từ ma trận trọng số a[u,v], u,v ∈ V, ta tính cận trên d[v] của khoảng cách từ s đến tất cả các đỉnh v ∈ V. Mỗi khi phát hiện
d[u] + a[u,v] < d[v] (1)
cận trên d[v] sẽ được làm tốt lên: d[v] + a[u,v].
Quá trình đó sẽ kết thúc khi nào chúng ta không làm tốt thêm được bất kỳ cận trên nào. Khi đó, rõ ràng giá trị của mỗi d[v] sẽ cho khoảng cách từ đỉnh s đến đỉnh v. Khi thể hiện kỹ thuật tính toán này trên máy tính, cận trên d[v] sẽ được gọi là nhãn của đỉnh v, còn việc tính lại các cận này sẽ được gọi là thủ tục gán. Nhận thấy rằng để tính khoảng cách từ s đến t, ở đây, ta phải tính khoảng cách từ s đến tất cả các đỉnh còn lại của đồ thị. Hiện nay vẫn chưa biết thuật toán nào cho phép tìm đường đi ngắn nhất giữa hai đỉnh làm việc thực sự hiệu quả hơn những thuật toán tìm đường đi ngắn nhất từ một đỉnh đến tất cả các đỉnh còn lại.
Sơ đồ tính toán mà ta vừa mô tả còn chưa xác định, bởi vì còn phải chỉ ra thứ tự các đỉnh u và v để kiểm tra điều kiện (1). Thứ tự chọn này có ảnh hưởng rất lớn đến hiệu quả của thuật toán.
Bây giờ ta sẽ mô tả thuât toán Ford-Bellman tìm đường đi ngắn nhất từ đỉnh s đến tất cả các đỉnh còn lại của đồ thị. Thuật toán làm việc trong trường hợp trọng số của các cung là tuỳ ý, nhưng giả thiết rằng trong đồ thị không có chu trình âm.
Procedure Ford_Bellman
(* Đầu vào:
Đồ thị có hướng G=(V,E) với n đỉnh,
s ∈ V là đỉnh xuất phát, A[u,v], u, v ∈ V, ma trận trọng số;
Giả thiết: Đồ thị không có chu trình âm.
Đầu ra:
Khoảng cách từ đỉnh s đến tất cả các đỉnh còn lại d[v], v ∈ V.
Trước[v], v ∈ V, ghi nhận đỉnh đi trước v trong đường đi ngắn nhất từ s đến v.*)
begin
(* Khởi tạo *)
for v ∈ V do
begin
d[v]:=a[s,v];
Truoc[v]:=s;
end;
d[s]:=0;
for k:=1 to n-2 do
for v ∈ V\{ s} do
for u ∈ V do
if d[v] > d[u] +a[u,v] then
begin
d[v]:=d[u]+a[u,v];
Truoc[v]:=u;
end;
end;
Tính đúng đắn của thuật toán có thể chứng minh trên cơ sở trên nguyên lý tối ưu của quy hoạch động. Rõ ràng là độ phức tạp tính toán của thuật toán là O(n3). Lưu ý rằng chúng ta có thể chấm dứt vòng lặp theo k khi phát hiện trong quá trình thực hiện hai vòng lặp trong không có biến d[v] nào bị đổi giá trị. Việc này có thể xảy ra đối với k<n-2, và điều đó làm tăng hiệu quả của thuật toán trong việc giải các bài toán thực tế. Tuy nhiên, cải tiến đó không thực sự cải thiện được đánh giá độ phức tạp của bản thân thuật toán. Đối với đồ thị thưa tốt hơn là sử dụng danh sách kề Ke(v), v∈ V, để biểu diễn đồ thị, khi đó vòng lặp theo u cần viết lại dưới dạng
For u ∈ Ke(v) do
If d[v] > d[u] + a[u,v] thenBegin
D[v]:=d[u]+a[u,v];Truoc[v]:=u;
End;
Trong trường hợp này ta thu được thuật toán với độ phức tạp O(n,m).

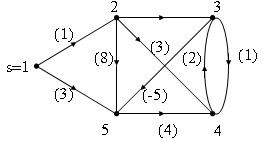
Hình 1. Minh họa thuật toán Ford_Bellman.
| k | d[1] Truoc[1] | d[2] Truoc[2] | d[3] Truoc[3] | d[4] Truoc[4] | d[5] Truoc[5] |
| 0, 1 | 1, 1 | ∞, 1 | ∞, 1 | 3, 1 | |
| 1 | 0, 1 | 1, 1 | 4, 2 | 4, 2 | -1, 3 |
| 2 | 0, 1 | 1, 1 | 4, 2 | 3, 5 | -1, 3 |
| 3 | 0, 1 | 1, 1 | 4, 2 | 3, 5 | -1, 3 |
Bảng kết quả tính toán theo thuật toán Ford_Bellman
Trong các mục tiếp theo chúng ta sẽ xét một số trường hợp riêng của bài toán tìm đường đi ngắn nhất mà để giải chúng có thể xây dựng những thuật toán hiệu quả hơn thuật toán Ford_Bellman. Đó là khi trọng số của tất cả các cung là các số không âm hoặc là khi đồ thị không có chu trình.
Trường hợp ma trận trọng số không âm. Thuật toán dijkstra
Trong trường hợp trọng số trên các cung là không âm thuật toán do Dijkstra đề nghị làm việc hữu hiệu hơn rất nhiều so với thuật toán trình bày trong mục trước. Thuật toán được xây dựng dựa trên cơ sở gán cho các đỉnh các nhãn tạm thời. Nhãn của mỗi đỉnh cho biết cận của độ dài đường đi ngắn nhất từ s đến nó. Các nhãn này sẽ được biến đổi theo một thủ tục lặp, mà ở mỗi bước lặp có một nhãn tạm thời trở thành nhãn cố định. Nếu nhãn của một đỉnh nào đó trở thành một nhãn cố định thì nó sẽ cho ta không phải là cận trên mà là độ dài của đường đi ngắn nhất từ đỉnh s đến nó. Thuật toán được mô tả cụ thể như sau.
Procedure Dijstra;
(* Đầu vào:
Đồ thị có hướng G=(v,E) với n đỉnh,
s ∈ V là đỉnh xuất phát, a[u,v], u,v ∈ V, ma trận trọng số;
Giả thiết: a[u,v]≥0, u,v ∈ V.
Đầu ra:
Khoảng cách từ đỉnh s đến tất cả các đỉnh còn lại d[v], v ∈ V.
Truoc[v], v ∈ V, ghi nhận đỉnh đi trước v trong đường đi ngắn nhất từ s đến v *)
Begin
(* Khởi tạo *)
for v ∈ V do
begin
d[v]:=a[s,v];
Truoc[v]:=s;
end;
d[s]:=0; T:=V\{ s} ; (* T là tập các đỉnh cá nhãn tạm thời *)
(* Bước lặp *)
while T <> ∅ do
begin
tìm đỉnh u ∈ T thoả mãn d[u]=min{ d[z]:z ∈ T} ;
T:=T\{u} ; (* Cố định nhãn của đỉnh u*)
For v ∈ T do
If d[v]>d[u]+a[u,v] then
Begin
d[v]:=d[u]+a[u,v];
Truoc[v]:=u;
End;
end;
End;
Định lý 1 Thuật toán Dijkstra tìm được đường đi ngắn nhất trên đồ thị sau thời gian cỡ O(n2).
Chứng minh.
Trước hết ta chứng minh là thuật toán tìm được đường đi ngắn nhất từ đỉnh s đến các đỉnh còn lại của đồ thị. Giả sử ở một bước lặp nào đó các nhãn cố định cho ta độ dài các đường đi ngắn nhất từ s đến các đỉnh có nhãn cố định, ta sẽ chứng minh rằng ở lần gặp tiếp theo nếu đỉnh u* thu được nhãn cố định d(u*) chính là độ dài đường đi ngẵn nhất từ s đến u*.
Ký hiệu S1 là tập hợp các đỉnh có nhãn cố định còn S2 là tập các đỉnh có nhãn tạm thời ở bước lặp đang xét. Kết thúc mỗi bước lặp nhãn tạm thời d(u*) cho ta độ dài của đường đi ngắn nhất từ s đến u* không nằm trọng trong tập S1, tức là nó đi qua ít nhất một đỉnh của tập S2. Gọi z ∈ S2 là đỉnh đầu tiên như vậy trên đường đi này. Do trọng số trên các cung là không âm, nên đoạn đường từ z đến u* có độ dài L > 0 và
d(z) < d(u*) – L < d(u*).
Bất đẳng thức này là mâu thuẫn với cách xác định đỉnh u* là đỉnh có nhãn tạm thời nhỏ nhất. Vậy đường đi ngắn nhất từ s đến u* phải nằm trọn trong S1, và vì thế, d[u*] là độ dài của nó. Do ở lần lặp đầu tiên S1 = {s} và sau mỗi lần lặp ta chỉ thêm vào một đỉnh u* nên giả thiết là d(v) cho độ dài đường đi ngắn nhất từ s đến v với mọi v ∈ S1 là đúng với bước lặp đầu tiên. Theo qui nạp suy ra thuật toán cho ta đường đi ngắn nhất từ s đến mọi đỉnh của đồ thị.
Bây giờ ta sẽ đánh giá số phép toán cần thực hiện theo thuật toán. Ơû mỗi bước lặp để tìm ra đỉnh u cần phải thực hiện O(n) phép toán, và để gán nhãn lại cũng cần thực hiện một số lượng phép toán cũng là O(n). thuật toán phải thực hiện n-1 bước lặp, vì vậy thời gian tính toán của thuận toán cỡ O(n2).
Định lý được chứng minh.
Khi tìm được độ dài của đường đi ngắn nhất d[v] thì đường đi này có thể tìm dựa vào nhãn Truoc[v], v∈ V, theo qui tắc giống như chúng ta đã xét.
Ví dụ 2 Tìm đường đi ngắn nhất từ 1 đến các đỉnh còn lại của đồ thị ở hình 2.
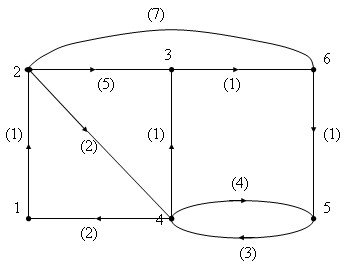
Hình 2 Minh họa thuật toán Dijkstra.
Kết quả tính toán theo thuật toán được trình bày theo bảng dưới đây. Qui ước viết hai thành phần của nhãn theo thứ tự: d[v]. Đỉnh được đánh dấu * là đỉnh được chọn để cố định nhãn ở bước lặp đang xét, nhãn của nó không biến đổi ở các bước tiếp theo, vì thế ta đánh dấu -.
| Bước lặp | Đỉnh 1 | Đỉnh 2 | Đỉnh 3 | Đỉnh 4 | Đỉnh 5 | Đỉnh 6 |
| Khởi tạo | 0,1 | 1,1* | ∞ ,1 | ∞ ,1 | ∞ ,1 | ∞ ,1 |
| 1 | - | - | 6,2 | 3,2* | ∞ ,1 | 8,2 |
| 2 | - | - | 4,4* | - | 7,4 | 8,2 |
| 3 | - | - | - | 7,4 | 5,3* | |
| 4 | - | - | - | 6,6* | - |
Chú ý:
1) Nếu chỉ cần tìm đường đi ngắn nhất từ s đến một đỉnh t nào đó thì có thể kết thúc thuật toán khi đỉnh t trở thành có nhãn cố định.
2) Tương tự như trong mục 2, dễ dàng mô tả thuật toán trong trường hợp đồ thị cho bởi danh sách kề. Để có thể giảm bớt khối lượng tính toán trong việc xác định đỉnh u ở mỗi bước lặp, có thể sử dụng thuật toán Heasort (tương tự như trong bài 5 khi thể hiện thuật toán Kruskal). Khi đó có thể thu được thuật toán với độ phức tạp tính toán là O(m log n).