Dữ liệu trong một DBMS là một tập hợp của các bản ghi, hoặc file, và mỗi file chứa một hoặc nhiều trang. Lớp phần mềm files and access methods (files và các phương thức truy cập) tổ chức dữ liệu cẩn thận để hỗ trợ truy cập nhanh đến tập dữ liệu mong muốn. Việc hiểu các bản ghi được tổ chức như thế nào rất cần thiết để chúng ta có thể sử dụng hệ thống cơ sở dữ liệu một cách hiệu quả, và đó là mục đích chính của chương này.
Tổ chức file là phương pháp sắp xếp các bản ghi trong một file khi file này được lưu trữ trên đĩa. Mỗi tổ chức file làm cho các phép thao tác hiện tại trở nên hiệu quả hơn nhưng có thể làm những phép thao tác khác phải trả chi phí cao hơn.
Xem xét một file chứa các bản ghi về các nhân viên, mỗi bản ghi chứa các trường age, name, và sal, file này sẽ được sử dụng như một ví dụ trong chương này. Nếu chúng ta muốn truy cập đến các các bản ghi theo thứ tự tăng dần của tuổi (age), việc sắp xếp file này theo tuổi là một cách tổ chức file tốt, nhưng duy trì file theo thứ tự sẽ phải trả chi phí đắt nếu file này thường xuyên có sự thay đổi. Thêm nữa, chúng ta thường muốn hỗ trợ nhiều hơn một phép thao tác trên một tập hợp các bản ghi. Trong ví dụ của chúng ta, chúng ta cũng muốn truy cập tất cả các nhân viên có lương lớn hơn $5000. Chúng ta phải quét toàn bộ file để tìm những bản ghi thoả mãn.
Một công nghệ gọi là đánh chỉ mục hoá có thể trợ giúp khi chúng ta phải truy cập đến một tập các bản ghi theo nhiều cách. Phần 2 giới thiệu về đánh chỉ mục, một khía cạnh quan trọng của tổ chức file trong một DBMS. Chúng ta biểu diễn tổng quan về các cấu trúc dữ liệu chỉ mục trong Phần 3; những trình bày chi tiết sẽ có trong Chương 10 và 11.
Chúng ta sẽ minh hoạ sự quan trọng của việc lựa chọn tổ chức file thích hợp trong Phần 4 thông qua một phân tích đơn giản của một vài tổ chức file. Mô hình định giá sử dụng trong phân tích này được trình bày trong Phần 4.1, cũng được sử dụng trong những chương cuối. Phần 5 chúng ta nhấn mạnh một số lựa chọn quan trọng được làm trong quá trình tạo các chỉ mục. Việc lựa chọn tập hợp các chỉ mục để xây dựng thường được cho là nhiệm vụ của người quản trị giúp cải thiện khả năng thực thi của hệ thống.
Dữ liệu trong thiết bị lưu trữ ngoài
Một DBMS lưu trữ một khối lượng khổng lồ dữ liệu, và dữ liệu phải ổn định khi thực thi chương trình. Vì thế, dữ liệu được lưu trong các thiết bị lưu trữ ngoài như đĩa, băng từ, và chỉ được nạp vào trong bộ nhớ chính khi quá trình xử lý cần đến nó. Một đơn vị thông tin đọc hoặc ghi từ đĩa được gọi là một trang. Kích thước của mỗi trang là một tham biến của DBMS, và có giá trị điển hình là 4KB hoặc 8KB.
Chi phí của một trang I/O (input từ đĩa tới bộ nhớ chính và output từ bộ nhớ chính ra đĩa) có ảnh hưởng lớn đến chi phí của các phép toán cơ sở dữ liệu, và các hệ thống cơ sở dữ liệu thường tối ưu hoá rất cẩn thận chi phí này. Những chi tiết về các files chứa các bản ghi được lưu trữ vật lý trên đĩa như thế nào và bộ nhớ chính được sử dụng như thế nào được trình bày trong Chương 9. Những điểm lưu ý sau là quan trọng và phải luôn nhớ:
- Các đĩa là các thiết bị lưu trữ ngoài quan trọng nhất. Nó cho phép chúng ta truy cập bất kỳ trang nào với một chi phí (nhiều hoặc ít hơn) một giá cố định nào đó. Tuy nhiên, nếu chúng ta đọc một vài trang theo thứ tự mà chúng đã được sắp xếp vật lý, thì chi phí này có thể ít hơn nhiều so với việc đọc các trang này theo một thứ tự ngẫu nhiên.
- Băng từ là thiết bị truy cập tuần tự và chúng bắt chúng ta phải đọc dữ liệu từng trang một theo thứ tự, trang này sau trang kia. Chúng hữu dụng cho các dữ liệu không được truy cập thường xuyên.
- Mỗi bản ghi trong một file có một định danh gọi là record id hay ngắn gọn là rid. Rid có thể được sử dụng để xác định địa chỉ của trang chứa bản ghi (chứa rid) này.
Dữ liệu được đọc vào bộ nhớ để xử lý, và viết vào đĩa để lưu trữ lâu dài bằng một phần mềm gọi là quản lý vùng đệm. Khi lớp files and access methods (thường được nhắc tới là lớp file) cần xử lý một trang nào đó, nó yêu cầu hệ thống quản lý vùng đệm nạp trang này, xác định rid của trang. Hệ thống quản lý vùng đệm nạp trang này từ đĩa nếu nó không đang sẵn sàng trong bộ nhớ.
Những khoảng trống trên đĩa được quản lý bởi disk space manager (bộ quản lý không gian đĩa), theo như kiến trúc phần mềm DBMS đã biểu diễn trong Phần 1.8. Khi lớp files and access methods cần thêm các khoảng trống để nhận thêm các bản ghi mới trong một file nào đó, nó yêu cầu disk space manager định vị một trang đĩa bổ sung cho file này: nó cũng thông báo cho disk space manager khi nó không còn cần đến một trang đĩa nào đó của nó. Disk space manager giữ lại dấu vết của các trang đang được lớp file sử dụng; nếu một trang nào không còn cần cho lớp file nữa, space manager sẽ ghi nhớ điều này, và tái sử dụng các vùng trống nếu lớp file yêu cầu một trang mới sau đó.
Trong phần còn lại của chương này, chúng ta sẽ tập trung vào lớp files and access methods.
Tổ chức file và đánh chỉ mục
File của các bản ghi là một khái niệm trừu tượng quan trọng trong DBMS, và được thực thi bằng lớp files and access methods. Một file có thể được tạo, xoá bỏ, và có thể thêm hoặc xoá các bản ghi trong nó. Nó cũng hỗ trợ việc quét file; một thao tác quét cho phép chúng ta duyệt tuần tự tất cả các bản ghi trong file. Một quan hệ được lưu trữ như một file của các bản ghi.
File lưu trữ các bản ghi dưới dạng tập hợp các trang. Nó giữ lại dấu vết của các trang đã định vị cho từng file, và nếu trong file có các bản ghi được thêm vào hay xoá đi, nó cũng lưu lại những vùng trống có thể trong các trang của file này.
Một cấu trúc file đơn giản nhất là file không sắp xếp thứ tự, còn gọi là file đống (heap file). Các bản ghi trong heap file được lưu trữ theo thứ tự ngẫu nhiên trong các trang. Một tổ chức heap file hỗ trợ truy cập tới tất cả các bản ghi, hoặc truy cập tới một bản ghi cụ thể nào đó thông qua rid của nó; bộ quản lý file phải lưu lại vị trí các trang trong file. (Chúng ta sẽ trình bày cách heap file thực thi thế nào trong Chương 9).
Một chỉ mục là một cấu trúc dữ liệu giúp tổ chức các bản ghi dữ liệu trên đĩa để tối ưu các phép toán truy cập. Một chỉ mục cho phép chúng ta truy cập hiệu quả tất cả các bản ghi thoả mãn các điều kiện tìm kiếm trên các trường khoá tìm kiếm của chỉ mục này. Chúng ta có thể cũng tạo ra các chỉ mục trên một tập các bản ghi dữ liệu, mỗi chỉ mục có một khoá tìm kiếm khác nhau, để tăng tốc độ các thao tác tìm kiếm.
Xem xét ví dụ về các bản ghi nhân viên của chúng ta. Chúng ta có thể lưu trữ các bản ghi trong một file nào đó đã được chỉ mục trên trường tuổi của nhân viên. Thêm nữa, chúng ta có thể tạo ra một file chỉ mục bổ trợ trên trường salary, để tăng tốc các truy vấn cần thông tin về lương của nhân viên. File đầu tiên chứa các bản ghi về nhân viên, và file thứ hai chứa các bản ghi cho phép chúng ta định vị được các bản ghi nhân viên thoả mãn điều kiện truy vấn trên lương.
Chúng ta sử dụng khái niệm cổng vào dữ liệu để dẫn đường tới các bản ghi được lưu trữ trong một file chỉ mục. Một cổng vào dữ liệu có giá trị khoá tìm kiếm k, ký hiệu là k*, chứa đầy đủ thông tin để định vị (một hoặc nhiều) các bản ghi dữ liệu có giá trị khoá tìm kiếm k. Chúng ta có thể thực hiện tìm kiếm trên một chỉ mục để tìm ra các cổng vào dữ liệu mong muốn, và sau đó sử dụng nó để lấy ra các bản ghi dữ liệu. Và đây là một cách thực hiện rất hiệu quả.
Có ba Trường hợp (Alternative) chính về những gì được lưu trữ trong một cổng vào dữ liệu của một chỉ mục:
- Cổng vào dữ liệu k* là một bản ghi dữ liệu thực sự (có giá trị khoá tìm kiếm k).
- Cổng vào dữ liệu là một cặp (k, rid ), trong đó rid là record id của một bản ghi dữ liệu có giá trị khoá tìm kiếm k.
- Cổng vào dữ liệu là cặp (k, rid-list ), trong đó rid-list là một danh sách các record ids của các bản ghi dữ liệu có giá trị khoá tìm kiếm k.
Tất nhiên, nếu chỉ mục này được sử dụng để lưu trữ các bản ghi dữ liệu thực, thì trong Alternative (1), mỗi cổng vào dữ liệu k* là một bản ghi dữ liệu với khoá tìm kiếm có giá trị k. Chúng ta có thể xem chỉ mục như một tổ chức file đặc biệt. Vì thế một tổ chức file chỉ mục có thể được sử dụng thay vì một file được sắp hoặc một file mà các bản ghi không được sắp thứ tự lộn xộn.
Alternatives (2) và (3), chứa những cổng vào dữ liệu trỏ đến các bản ghi dữ liệu, độc lập với tổ chức file sử dụng các indexed file (tức là, file chứa các bản ghi dữ liệu). Alternative (3) đề xuất một cách sử dụng không gian đĩa tốt hơn Alternative (2), trong đó các cổng vào dữ liệu có thể thay đổi độ lớn, phụ thuộc vào số lượng các bản ghi dữ liệu và giá trị khoá tìm kiếm được cho.
Nếu chúng ta muốn xây dựng nhiều hơn một chỉ mục trên một tập hợp các bản ghi dữ liệu- ví dụ, chúng ta muốn xây dựng các chỉ mục trên cả hai trường age và sal cho một tập hợp các bản ghi nhân viên- thì tối đa chỉ một trong hai chỉ mục này nên sử dụng Alternative(1) vì chúng ta nên tránh việc lưu trữ các bản ghi dữ liệu nhiều lần.
Các chỉ mục phân cụm
Khi một file nào đó được tổ chức để thứ tự của các bản ghi dữ liệu là giống nhau hoặc gần với thứ tự của các cổng vào dữ liệu trong một vài chỉ mục, thì chúng ta nói rằng chỉ mục này được phân cụm (clustered); ngược lại, nó là chỉ mục không phân cụm (unclustered index). Theo định nghĩa, chỉ mục sử dụng Alternative (1) là chỉ mục được phân cụm. Chỉ mục sử dụng Alternative (2) hoặc (3) có thể là một chỉ mục phân cụm chỉ nếu các bản ghi dữ liệu này được sắp xếp theo trường khoá tìm kiếm. Ngược lại, nếu thứ tự các bản ghi dữ liệu là ngẫu nhiên, hoàn toàn xác định bởi thứ tự vật lý của chúng, thì không có cách nào để sắp xếp những cổng vào dữ liệu này trong một chỉ mục theo cùng một thứ tự.
Thực tế, các file hiếm khi được lưu trữ theo thứ tự vì chi phí để duy trì việc này rất đắt nếu dữ liệu này cần được cập nhật. Vì thế trên thực tế, chỉ mục phân cụm là một chỉ mục sử dụng Alternative (1), và các chỉ mục sử dụng Alternatives (2) hoặc (3) là chỉ mục không phân cụm.
Đôi khi chúng ta coi chỉ mục đang sử dụng Alternative (1) là clustered file, vì các cổng vào dữ liệu là các bản ghi dữ liệu thực sự, và vì thế chỉ mục này là một file chứa các bản ghi dữ liệu. (Như đã quan sát ở trên, việc tìm và quét trên một chỉ mục sẽ trả về chỉ những cổng vào dữ liệu của nó, dù cho là chỉ mục này chứa những thông tin khác dùng để tổ chức các cổng vào dữ liệu.)
Chi phí của việc sử dụng một chỉ mục để đáp lại một truy vấn tìm kiếm miền có thể rất rất lớn tuỳ vào chỉ mục này có được phân cụm không. Nếu chỉ mục này được phân cụm, tức là, chúng ta đang sử dụng khoá tìm kiếm của một clustered file, rids trong các cổng vào dữ liệu trỏ tới một tập hợp các bản ghi kề nhau, và chúng ta chỉ cần truy cập một vài trang dữ liệu. Nếu chỉ mục này là không phân cụm, mỗi cổng vào dữ liệu có thể chứa một rid trỏ tới một trang dữ liệu riêng biệt, dẫn tới số lượng các trang dữ liệu I/Os nhiều bằng số lượng các cổng vào dữ liệu ứng với phép chọn miền, như minh hoạ trong Hình 1. Điểm này được bàn thêm trong Chương 13.

Các chỉ mục chính và chỉ mục phụ
Một chỉ mục trên một tập các trường trong đó có khoá chính (xem Chương 3) được gọi là chỉ mục chính; những chỉ mục khác được gọi là các chỉ mục phụ. (Cụm từ chỉ mục chính và chỉ mục phụ đôi khi được sử dụng với nghĩa khác. Chỉ mục sử dụng Alternative (1) được gọi là chỉ mục chính, và chỉ mục sử dụng Alternatives (2) hoặc (3) được gọi là chỉ mục phụ.)
Hai cổng vào dữ liệu được gọi là trùng nhau nếu chúng có cùng giá trị của trường khoá tìm kiếm liên quan đến chỉ mục này. Chỉ mục chính được đảm bảo là không chứa sự trùng nhau, nhưng chỉ mục trên các trường khác có thể chứa sự trùng nhau. Nói chung, các chỉ mục phụ sẽ chứa sự trùng nhau. Nếu chúng ta biết rằng không tồn tại sự trùng nhau, tức là chúng ta biết rằng khoá tìm kiếm chứa một một vài khoá dự tuyển, chúng ta gọi chỉ mục này là chỉ mục duy nhất.
Một vấn đề quan trọng là các cổng vào dữ liệu trong một chỉ mục được tổ chức như thế nào để hỗ trợ truy cập dữ liệu hiệu quả. Chúng ta sẽ bàn đến trong phần sau.
Các cấu trúc dữ liệu chỉ mục
Một cách để tổ chức cổng vào dữ liệu là băm các cổng vào dữ liệu dựa trên khoá tìm kiếm. Một cách khác để tổ chức các cổng vào dữ liệu là xây dựng một cấu trúc dữ liệu dạng-cây, cấu trúc này dùng để định hướng tìm kiếm các cổng vào dữ liệu. Chúng tôi giới thiệu hai cách tiếp cận cơ bản này trong phần này. Chúng ta sẽ nghiên cứu chi tiết về chỉ mục dựa trên cây trong Chương 10 và chỉ mục dựa trên băm trong Chương 11.
Chúng ta ghi nhớ rằng việc lựa chọn công nghệ chỉ mục dựa trên cây hoặc dựa trên băm có thể được kết hợp với bất kỳ một trong ba Alternative.
Chỉ mục dựa trên băm
Chúng ta có thể tổ chức các bản ghi sử dụng một công nghệ gọi là băm để nhanh chóng tìm được các bản ghi có giá trị khoá tìm kiếm bằng giá trị đưa vào. Ví dụ, nếu file của các bản ghi nhân viên được băm dựa trên trường name, chúng ta có thể truy cập tất cả các bản ghi về Joe.
Trong cách tiếp cận này, các bản ghi trong file được nhóm lại trong một buckets, trong đó một bucket chứa một trang chính và có thể là các trang khác được liên kết trong một chuỗi.
Một bản ghi nào đó thuộc về bucket nào đó có thể được xác định bằng cách thực hiện một hàm đặc biệt trên khoá tìm kiếm, hàm này gọi là hàm băm. Cho một bucket, cấu trúc chỉ mục dựa trên băm cho phép chúng ta truy cập trang chính của bucket này trong một hoặc hai đĩa I/Os.
Đối với việc thêm bản ghi, bản ghi được thêm vào một bucket phù hợp cùng với các trang ‘tràn’ nếu cần thiết. Để tìm kiếm một bản ghi nếu biết giá trị khoá tìm kiếm, chúng ta áp dụng hàm băm này để xác định bucket nào chứa bản ghi và tìm trong tất cả các trang của bucket này. Nếu chúng ta không có giá trị khoá tìm kiếm, ví dụ, chỉ mục này được xây dựng dựa trên sal và chúng ta muốn tìm các bản ghi có giá trị tuổi bằng một tuổi nào đó nhập vào, chúng ta phải quét tất cả các trang trong file này.
Trong chương này, chúng ta giả sử rằng việc áp dụng một hàm băm tới (khoá tìm kiếm của) một bản ghi nào đó cho phép chúng ta xác định và truy cập được trang chứa bản ghi này chỉ bằng một thao tác I/O. Trên thực tế, các cấu trúc chỉ mục dựa trên băm thường thực hiện việc thêm, xoá và cho phép chúng ta truy cập đến trang chứa bản ghi này bằng một hoặc hai thao tác I/Os (xem Chương 11).
Chỉ mục băm được minh hoạ trong Hình 2, nơi mà dữ liệu được lưu trong một file được băm trên trường age; các cổng vào dữ liệu trong file chỉ mục đầu tiên này là các bản ghi dữ liệu thực. Việc áp dụng hàm băm trên trường age xác định được trang chứa bản ghi này. Hàm băm h trong ví dụ này thực sự rất đơn giản; nó chuyển giá trị khoá tìm kiếm thành biểu diễn nhị phân và sử dụng hai bit ít quan trọng nhất để định danh bucket.
Hình 2 cũng chỉ ra chỉ mục với khoá tìm kiếm sal chứa cặp (sal, rid) là các cổng vào dữ liệu. Rid (viết tắt của record id) cấu thành nên cổng vào dữ liệu trong chỉ mục thứ hai này là một con trỏ trỏ tới một bản ghi có giá trị khoá tìm kiếm sal (và được chỉ ra trong hình này là một mũi tên trỏ tới bản ghi dữ liệu này).
Việc sử dụng ký hiệu này được giới thiệu trong Phần 2, Hình 2 minh hoạ Alternatives (1) và (2) cho các cổng vào dữ liệu. File của các bản ghi nhân viên được băm trên trường age, và Alternative (1) được sử dụng cho các cổng vào dữ liệu. Chỉ mục thứ hai trên trường sal cũng sử dụng việc băm để xác định các cổng vào dữ liệu – bây giờ là cặp (sal, rid của bản ghi nhân viên), tức là Alternative (2) được sử dụng cho các cổng vào dữ liệu.

Ghi nhớ rằng khoá tìm kiếm cho một chỉ mục nào đó có thể là một hoặc nhiều trường, và nó không cần định danh duy nhất một bản ghi. Ví dụ, trong chỉ mục salary, hai cổng vào dữ liệu có cùng khoá tìm kiếm giá trị là 6003. (Có sự lạm dụng trong sử dụng khái niệm khoá. Khoá chính hoặc khoá dự tuyển - những trường định danh duy nhất một bản ghi; xem Chương 3- không liên quan đến khái niệm của khoá tìm kiếm.
Chỉ mục dựa trên cây
Ngoài cách sử dụng chỉ mục dựa trên băm, chúng ta còn có thể sử dụng cấu trúc dữ liệu dạng cây để tổ chức các bản gho. Các cổng vào dữ liệu được sắp xếp theo thứ tự của giá trị khoá tìm kiếm, và một cấu trúc dữ liệu tìm kiếm phân cấp được duy trì để định hướng việc tìm kiếm.
Hình 3 chỉ ra các bản ghi nhân viên như Hình 2, nhưng lần này nó được tổ chức trong một chỉ mục cấu trúc cây với khoá tìm kiếm là age. Với mỗi nút trong hình này (ví dụ, các nút có nhãn A, B, Ll, L2) là một trang vật lý, và việc truy cập một nút cần một I/O đĩa.
Mức thấp nhất của cây này gọi là mức lá, chứa các cổng vào dữ liệu; trong ví dụ của chúng ta đó là những bản ghi nhân viên. Để minh hoạ những ý tưởng này tốt hơn, chúng ta vẽ Hình 3 như là ở đó có việc thêm vào các bản ghi nhân viên, một số có tuổi nhỏ hơn 22 và một số có tuổi lớn hơn 50 (giá trị tuổi thấp nhất và cao nhất xuất hiện trong Hình 2.) Những bản ghi nhân viên có tuổi nhỏ hơn 22 sẽ được xuất hiện trong các trang lá (L1), và các bản ghi có tuổi lớn hơn 50 sẽ xuất hiện trong các trang lá (L3).

Cấu trúc này cho phép chúng ta định vị các cổng vào dữ liệu với các giá trị khoá tìm kiếm trong một vùng mong muốn một cách hiệu quả. Tất cả các tìm kiếm bắt đầu ở nút cao nhất, gọi là nút gốc, và nội dung của các trang ở mức không-lá định hướng việc tìm kiếm tới trang lá đúng. Các trang không-lá chứa các nút phân tách nhau bởi giá trị khoá tìm kiếm. Con trỏ bên trái của giá trị khoá k trỏ tới cây con chứa chỉ những cổng vào dữ liệu nhỏ hơn k. Con trỏ bên phải của giá trị khoá k trỏ tới cây con chứa chỉ những cổng vào dữ liệu lớn hơn hoặc bằng k. Trong ví dụ của chúng ta, giả sử rằng chúng ta muốn tìm tất cả cổng vào dữ liệu với 24 < age < 50. Mỗi đường đi từ nút gốc tới một nút con trong Hình 2 có một nhãn giải thích nội dung chứa trong cây con đó. (Mặc dù các nhãn của các đường đi còn lại không được chỉ ra, nhưng chúng ta cũng có thể dễ dàng suy luận ra.) Trong ví dụ tìm kiếm của chúng ta, chúng ta tìm các cổng vào dữ liệu có giá trị khoá tìm kiếm > 24, và nó được định hướng là ở nút con giữa, nút A. Kiểm tra nội dung của nút này, chúng ta lại được định hướng để tìm tiếp trong nút B. Kiểm tra nội dung của nút B, chúng ta lại được định hướng để tìm tiếp trong nút lá L1, nút này chứa các cổng vào dữ liệu chúng ta đang tìm.
Quan sát thấy rằng các nút là L2 và L3 cũng chứa những cổng vào dữ liệu thoả mãn điều kiện của chúng ta. Để thuận lợi cho việc truy cập các cổng vào dữ liệu dữ liệu như vậy trong khi tìm kiếm, tất cả các trang lá được duy trì trong một danh sách liên kết đôi. Vì thế, chúng ta có thể đến trang L2 sử dụng con trỏ next trên trang L1, và sau đó đến trang L3 sử dụng con trỏ next trên L2.
Vì thế, số lượng thao tác I/Os trong quá trình tìm kiếm bằng với chiều dài đường đi từ gốc đến lá cộng với số các trang lá chứa các cổng vào dữ liệu thoả mãn. B+tree là một cấu trúc chỉ mục đảm bảo rằng tất cả các đường đi từ gốc đến lá trong một cây nào đó sẽ có chiều dài tương đương, tức là, cấu trúc này luôn cân bằng về chiều cao. Việc tìm kiếm một trang lá thoả mãn nhanh hơn tìm kiếm nhị phân tất cả các trang trong một file được sắp vì mỗi nút không phải là lá có thể phù hợp với một số lượng lớn các con trỏ, và chiều cao của cây trong thực tế ít khi nhiều hơn ba hoặc bốn. Chiều cao của cây cân bằng là chiều dài của đường đi từ gốc đến lá; trong Hình 3, chiều cao của cây là ba. Số lượng các I/Os để truy cập một trang lá mong muốn nào đó là bốn, bao gồm gốc và các trang lá. (Trong thực tế, gốc thường nằm trong buffer pool vì nó thường xuyên được truy cập, và chúng ta cần ba thao tác I/Os cho một cây có chiều cao bằng ba.)
Số lượng trung bình các con của một nút không phải là lá được gọi là fan-out của cây. Nếu tất cả các nút không phải là lá có n con, một cây chiều cao h sẽ có nh trang lá. Trong thực tế, các nút không có cùng số lượng các con, nhưng khi sử dụng F là giá trị trung bình của n, chúng ta vẫn có được số lượng các trang lá xấp xỉ là Fh. Trong thực tế, F ít nhất là 100, có nghĩa là cây có chiều cao bằng bốn sẽ chứa 100 triệu trang lá. Vì thế, chúng ta có thể phải tìm kiếm trong một file có 100 triệu trang lá và tìm ra trang chúng ta muốn mà chỉ cần sử dụng bốn thao tác I/Os; trong khi đó, tìm kiếm nhị phân của file tương đương sẽ mất log2100.000.000 (over 25) I/Os.
So sánh các tổ chức file
Bây giờ chúng ta sẽ so sánh chi phí của một số các thao tác đơn giản trên các tổ chức file cơ bản được thực hiện trên một tập các bản ghi nhân viên. Chúng tôi giả sử rằng các file các các chỉ mục được tổ chức theo khoá tìm kiếm tổ hợp là (age,sal), và tất cả các thao tác được xác định trên những trường này. Các tổ chức file chúng ta đề cập như sau:
- File chứa các bản ghi nhân viên có thứ tự ngẫu nhiên, hoặc heap file.
- File chứa các bản ghi nhân viên được sắp xếp trên hai trường (age, sal).
- Clustered B+tree file với khoá tìm kiếm là (age, sal).
- Heap file với một unclustered B+ tree index trên (age, sal).
- Heap file với một unclustered hash index trên (age. sal).
Mục đích của chúng ta là nhấn mạnh sự quan trọng của việc lựa chọn một tổ chức file phù hợp, và danh sách trên bao gồm các lựa chọn khác nhau được xem xét trong thực tế. Rõ ràng, chúng ta có thể lưu các bản ghi theo thứ tự được sắp hoặc không. Chúng ta cũng có thể xây dựng một chỉ mục trên file dữ liệu.
Các thao tác chúng ta xem xét bao gồm:
- Quét: Truy cập tất cả các bản ghi trong file này. Các trang trong file này phải được đưa vào buffer pool từ đĩa. Ở đây cũng có một CPU overhead cho từng bản ghi phục vụ việc định vị bản ghi này trên trang (trong buffer pool này).
- Tìm kiếm với điều kiện bằng: Truy cập tất cả các bản ghi thoả mãn điều kiện chọn bằng; ví dụ, “Tìm các bản ghi nhân viên có age 23 và sal 50.” Các trang chứa các bản ghi thoả mãn điều kiện bằng này phải được nạp vào từ đĩa, và các bản ghi thỏa mãn phải được đặt vào trong các trang được truy cập.
- Tìm kiếm với điều kiện miền: Truy cập tất cả các bản ghi thoả mãn điều kiện chọn miền; ví dụ, “Tìm tất cả các bản ghi nhân viên có age lớn hơn 35”.
- Thêm một bản ghi: Khi thêm một bản ghi vào trong file, chúng ta phải xác định trang nào trong file sẽ chứa bản ghi này, nạp trang này từ đĩa vào bộ nhớ, sửa nó để có bản ghi mới, và sau đó viết trang này trở lại ra đĩa.
- Xoá một bản ghi: Khi xoá một bản ghi được định danh bởi rid của nó, chúng ta phải xác định trang nào đang chứa bản ghi này, đưa nó vào bộ nhớ từ đĩa, sửa nó, và viết nó trở lại đĩa. Tuỳ vào cách tổ chức file, chúng ta có thể phải nạp, sửa và viết trở lại những trang liên quan nếu cần.
Mô hình định giá
Trong so sánh về các tổ chức file của chúng ta, và trong cuối chương này, chúng ta sử dụng một mô hình định giá đơn giản để cho phép ước lượng chi phí (theo thời gian thực thi) của các thao tác cơ sở dữ liệu khác nhau. Chúng ta sử dụng B để ký hiệu cho số lượng các trang dữ liệu khi các bản ghi được dồn đầy vào trong trang mà không còn không gian lãng phí nào, và R để ký hiệu cho số lượng các bản ghi trong mỗi trang. Thời gian trung bình để đọc hoặc ghi một trang đĩa là D, và thời gian trung bình để xử lý một bản ghi (ví dụ, so sánh một giá trị của trường với một hằng số nào đó) là C. Trong tổ chức file băm, chúng ta sử dụng một hàm gọi là hàm băm để ánh xạ một bản ghi vào một dải của các số; thời gian yêu cầu để áp hàm băm này cho một bản ghi nào đó là H. Với các chỉ mục cây, chúng ta sẽ sử dùng F để ký hiệu cho fan-out, như đề cập trong Phần 3.3, fan-out có giá trị ít nhất là 100.
Ngày nay giá trị của D bằng khoảng 15milli giây, C và H = 100nano giây; vì thế chúng ta hy vọng là chi phí cho I/O là chủ yếu. I/O thường chiếm phần lớn hơn rất nhiều so với giá của các thao tác khác, và vì thế việc tính được chi phí I/O sẽ cung cấp cho chúng ta chi phí xấp xỉ khá đúng. Thêm nữa, tốc độ CPU hiện nay tăng lên đáng kể, ngược lại tốc độ xử lý trên đĩa không tăng lên tương ứng. (Mặt khác, khi kích thước bộ nhớ chính tăng lên, số lượng các trang được đưa vào bộ nhớ chính cùng tăng lên, dẫn đến số lượng các yêu cầu I/O ít đi!) Chúng ta tập trung vào các thành phần I/O trong mô hình định giá, và chúng ta giả sử hằng số C là chi phí xử lý mỗi bản ghi trong bộ nhớ trong. Bạn hãy luôn lưu ý đến những quan sát sau:
Những hệ thống thực phải đề cập đến những ảnh hưởng khác đến chi phí, như giá CPU (và chi phí truyền dữ liệu qua mạng trong các cơ sở dữ liệu phân tán).
Mặc dù chúng ta chỉ tập trung vào chi phí I/O, mô hình chính xác xem xét tất cả khía cạnh cũng sẽ rất phức tạp. Vì thế, chúng ta sử dụng một mô hình đơn giản trong đó chúng ta chỉ đếm số lượng các trang đọc hoặc ghi vào đĩa và dùng nó làm thước đo I/O. Chúng ta bỏ qua vấn đề quan trọng là truy cập theo khối trong phân tích của chúng ta- thông thường, các hệ thống đĩa cho phép chúng ta đọc một khối các trang bằng chỉ một yêu cầu I/O. Chi phí sẽ bằng thời gian cần để tìn trang đầu tiên trong khối và chuyển tất cả các trang trong khối này vào bộ nhớ. Việc truy cập theo khối như thế này có thể rẻ hơn nhiều so với phát ra một yêu cầu I/O ứng với mỗi trang trong khối, đặc biệt nếu những yêu cầu này không được thực hiện liên tiếp, vì chúng ta sẽ phải cộng thêm chi phí tìm kiếm từng trang trong khối.
Chúng ta bàn đến những thành phần liên quan đến mô hình định giá bất cứ khi nào những giả định đơn giản này ảnh hưởng đến những kết luận quan trọng của chúng ta.
Heap file
Quét: Chi phí là B(D+RC) vì chúng ta phải truy cập B trang, mỗi trang mất một thời gian là D, và với mỗi trang, cần phải xử lý R bản ghi và mỗi bản ghi mất thời gian C.
Tìm kiếm với phép chọn bằng: Giả sử chúng ta biết rằng có chính xác một bản ghi thoả mãn điều kiện bằng, tức là, việc chọn lọc được xác định dựa trên một khoá dự tuyển. Trung bình, chúng ta phải quét một nửa file, giả sử rằng bản ghi này tồn tại và việc phân bố giá trị trong trường tìm kiếm là đồng đều. Với mỗi trang dữ liệu được truy cập, chúng ta phải kiểm tra tất cả các bản ghi trên trang này để xem nó có phải là bản ghi cần tìm. Chi phí là 0.5B(D + RC). Tuy nhiên, nếu không có bản ghi nào thoả mãn điều kiện chọn, chúng ta phải quét toàn bộ file để chắc chắn điều này. Nếu phép chọn không dựa trên trường khoá dự tuyển (ví dụ, “Tìm các nhân viên có age=18”, chúng ta luôn luôn phải quét toàn bộ file vì các bản ghi có age = 18 có thể xuất hiện nhiều lần trong toàn bộ file, và chúng ta không biết có bao nhiêu bản ghi thoả mãn đang tồn tại.
Tìm kiếm với phép chọn miền: Toàn bộ file phải được quét vì các bản ghi thoả mãn phải có thể xuất hiện ở bất kỳ đâu trong file này, và chúng ta không biết có bao nhiêu bản ghi thoả mãn đang tồn tại. Chi phí là B(D + RC).
Thêm: Chúng ta giả sử rằng các bản ghi luôn được thêm vào cuối của file. Chúng ta phải nạp trang cuối cùng trong file này vào bộ nhớ trong, thêm bản ghi, và viết trang này trở lại đĩa. Chi phí là 2D + C.
Xoá: Chúng ta phải tìm bản ghi cần xoá, loại bỏ bản ghi này ra khỏi trang, và viết trang đã sửa này trở về đĩa. Để đơn giản, chúng ta giả sử rằng không có một sự cố gắng nén file nào được thực hiện để tiết kiệm không gian trống sinh ra sau khi xoá bản ghi.
Chúng ta giả sử rằng bản ghi bị xoá được xác định sử dụng record id. Vì chúng ta có thể dễ dàng xác định được page id thông qua record id, nên chúng ta có thể đọc trực tiếp trang này. Vì thế, chi phí tìm kiếm là D.
Nếu bản ghi bị xoá được xác định bằng cách sử dụng điều kiện bằng hoặc điều kiện miền trên một số trường, chi phí tìm kiếm được trình bày trong phần thảo luận về các phép chọn bằng và phép chọn miền. Chi phí của việc xoá cũng bị ảnh hưởng bởi số lượng các bản ghi thoả mãn, vì tất cả các trang chứa những bản ghi này cũng phải được sửa đổi theo.
Sorted Files
Quét: Chi phí là B(D + RC) bởi vì tất cả các trang phải được kiểm tra. Ghi nhớ rằng trường hợp này không tốt hay xấu hơn trường hợp các file không được sắp xếp. Tuy nhiên, thứ tự các bản ghi được quét tương ứng với thứ tự được sắp, tức là, tất các các bản ghi được quét theo thứ tự của age, và sau đó nếu age bằng nhau thì chúng quét theo thứ tự của sal.
Tìm kiếm với phép chọn bằng: Chúng ta giả sử rằng phép chọn bằng này được so sánh theo cặp hai trường là (age, sal), và lưu ý là các bản ghi được sắp xếp theo hai trường này. Mặt khác, chúng ta giả sử rằng điều kiện chọn được xác định trên ít nhất một trường đầu tiên trong khoá tổ hợp (ví dụ, age = 30). Nếu không (ví dụ, điều kiện là sal = 50 hoặc department = “Toy”), thứ tự được xếp này không giúp được chúng ta và chi phí giống hệt như trường hợp của heap file.
Chúng ta có thể định vị trang đầu tiên chứa bản ghi cần tìm bằng tìm kiếm nhị phân trong log2B bước. (Phân tích này giả sử rằng các trang trong file được sắp này được lưu trữ tuần tự, và chúng ta có thể truy cập trang thứ i trên file này một cách trực tiếp). Mỗi bước yêu cầu một thao tác I/O đĩa và hai phép so sánh. Khi trang được biết, bản ghi thoả mãn đầu tiên có thể được định vị lại bằng tìm kiếm nhị phân trên trang này với chi phí là Clog2R. Như vậy, tổng chi phí là Dlog2B + Clog2R, nó được cải thiện đáng kể so với tìm kiếm trên heap file.
Nếu có một số bản ghi thoả mãn (ví dụ, “Tìm tất cả các bản ghi có age=18”), chúng được bảo đảm là liền kề nhau do các bản ghi được sắp xếp trên trường age, và vì thế chi phí truy cập tất cả các bản ghi này bằng chi phí xác định bản ghi đầu tiên (Dlog2B + Clog2R) cộng với chi phí đọc tất cả các bản ghi thoả mãn một cách tuần tự. Lý tưởng thì tất cả các bản ghi thoả mãn được đặt vừa trong một trang đơn. Nếu không có bản ghi nào thoả mãn, chi phí này được xác định bằng chi phí tìm kiếm bản ghi thoả mãn đầu tiên, đó là tìm trang chứa bản ghi thoả mãn và thực hiện tìm kiếm trên trang này.
Tìm kiếm với phép chọn miền: Một lần nữa giả sử rằng phép chọn miền được so sánh trên khoá tổ hợp này, bản ghi đầu tiên thoả mãn điều kiện chọn được xác định giống như trong tìm kiếm với điều kiện bằng. Sau đó, các trang dữ liệu được truy cập một cách tuần tự để tìm ra tất cả các bản ghi thoả mãn điều kiện; điều này tương tự như trong tìm kiếm bằng với rất nhiều bản ghi thoả mãn.
Chi phí là chi phí tìm kiếm cộng với chi phí truy cập tập các bản ghi thoả mãn điều kiện tìm kiếm. Với các phép chọn có miền nhỏ, tất cả các bản ghi thoả mãn có thể xuất hiện trong trang này. Với các miền tìm kiếm lớn hơn, chúng ta phải nạp thêm các trang để chứa các bản ghi thoả mãn.
Thêm: Để thêm một bản ghi nào đó mà vẫn duy trì được thứ tự sắp xếp, đầu tiên chúng ta phải tìm vị trí có thể thêm được trong file này, thêm bản ghi vào và sau đó viết lại các trang này lên đĩa (giả sử rằng file này không có khe rỗng nên tất cả các bản ghi cũ phải dịch chuyển một slot). Để lấy trung bình, chúng ta có thể giả sử rằng các bản ghi được thêm sẽ ở giữa của file. Vì thế, chúng ta phải đọc nửa cuối của file này và sau đó viết nó quay trở lại đĩa sau khi thêm bản ghi mới. Chi phí bằng chi phí của việc tìm vị trí đặt bản ghi mới cộng với 2•(0.5B(D + RC)), tức là bằng chi phí tìm kiếm cộng B(D+RC).
Xoá: Chúng ta phải tìm bản ghi cần xoá, loại bản ghi này khỏi trang và viết trang được sửa này quay lại đĩa. Chúng ta cũng phải đọc và ghi tất cả các trang phía sau vì tất cả bản ghi theo sau bản ghi được xoá phải được dồn lại phía trước để không bị lãng phí vùng trống trên đĩa.
Nếu các bản ghi cần xoá được xác định bằng điều kiện bằng hoặc miền, chi phí của việc xoá này phục thuộc vào số lượng các bản ghi thoả mãn điều kiện. Nếu điều kiện này được xác định trên trường được sắp, các bản ghi thoả mãn được đảm bảo là liền kề nhau, và bản ghi đầu tiên thoả mãn có thể được xác định bằng tìm kiếm nhị phân.
Clustered Files
Trong clustered file, kết quả nghiên cứu trên phạm vi rộng đã chỉ ra rằng các trang thường được sử dụng khoảng 67%. Vì thế, số lượng các trang dữ liệu vật lý khoảng 1.5B, và chúng ta sử dụng quan sát này trong phân tích sau.
Quét: Chi phí của việc quét bằng khoảng 1.5B(D + RC) bởi vì tất cả các trang phải được kiểm tra; chi phí này tương đương với trường hợp các file được sắp, cùng với những điều chỉnh hiển nhiên khi số lượng các trang dữ liệu tăng lên. Ghi nhớ rằng mô hình chi phí của chúng ta không cân nhắc đến sự khác nhau trong chi phí khi I/O tuần tự. Chúng ta hy vọng là các file được sắp làm việc tốt hơn trong trường hợp này, dù cho clustered file sử dụng ISAM.
Tìm kiếm với phép chọn bằng: Chúng ta giả sử rằng phép chọn bằng được so sánh trên khoá tìm kiếm (age, sal). Chúng ta có thể xác định được trang đầu tiên chứa bản ghi cần tìm trong logf1.5B bước, tức là bằng với việc tìm ra tất cả các trang từ gốc đến lá phù hợp. Trong thực tế, trang gốc dường như luôn ở buffer pool và chúng ta tiết kiệm được một I/O, nhưng chúng ta bỏ quan điều này trong khi phân tích. Mỗi bước yêu cầu một I/O đĩa và hai phép so sánh. Đối với mỗi trang, bản ghi thoả mãn đầu tiên có thể được định vị lại bằng một tìm kiếm nhị phân trên trang này với chi phí bằng Clog2R. Tổng chi phí là DlogF1.5B + Clog2R, nó được cải thiện đáng kể so với tìm kiếm thậm chí trên các sorted files.
Nếu có một số bản ghi thoả mãn (ví dụ, “Tìm tất cả các bản ghi có age=18”), chúng được bảo đảm là liền kề nhau do các bản ghi được sắp xếp trên trường age, và vì thế chi phí truy cập tất cả các bản ghi này bằng chi phí xác định bản ghi đầu tiên (Dlog2B + Clog2R) cộng với chi phí đọc tất cả các bản ghi thoả mãn một cách tuần tự.
Tìm kiếm với phép chọn miền: Một lần nữa giả sử rằng phép chọn miền được so sánh với trên khoá tổ hợp này, bản ghi đầu tiên thoả mãn điều kiện chọn được xác định giống như trong tìm kiếm với điều kiện bằng. Sau đó, các trang dữ liệu được truy cập một cách tuần tự (sử dụng các liên kết phía trước và phía sau ở mức lá) để tìm ra tất cả các bản ghi thoả mãn điều kiện; điều này tương tự như trong tìm kiếm bằng với rất nhiều bản ghi thoả mãn.
Thêm: Để thêm một bản ghi nào đó, đầu tiên chúng ta phải tìm trang lá để thêm bản ghi này trong chỉ mục, đọc tất cả các trang từ gốc đến lá. Sau đó chúng ta phải thêm bản ghi mới. Hầu hết thời gian, trang lá có những vùng trống đủ để thêm bản ghi mới, và tất cả chúng ta cần phải làm là viết ra ngoài những trang lá sau khi sửa. Đôi khi, trang lá đầy và chúng ta cần truy cập và sửa những trang khác, nhưng điều này là hiếm khi xảy ra và chúng ta có thể bỏ qua nó. Vì thế, tổng chi phí bằng chi phí tìm kiếm cộng với một thao tác viết DlogF1.5B + Clog2R + D.
Xoá: Chúng ta phải tìm bản ghi cần xoá, loại bỏ nó khỏi trang, và viết trang được sửa này ra đĩa. Những trình bày và phân tích chi phí cho trường hợp thêm được áp dụng tốt ở đây.
Heap File với Unclustered Tree Index
Số lượng các trang lá trong một chỉ mục phụ thuộc vào kích thước của cổng vào dữ liệu. Chúng ta giả sử rằng mỗi cổng vào dữ liệu trong chỉ mục này có kích thước bằng một phần mười kích thước một bản ghi dữ liệu nhân viên. Số lượng các trang lá trong chỉ mục này là 0.1(1.5B) = 0.15B nếu chúng ta biết các trang chỉ mục thường sử dụng khoảng 67% khả năng lưu trữ của nó. Tương tự, số lượng các cổng vào dữ liệu trên một trang là 10(0.67R) = 6.7R.
Quét: Xem Hình 1 minh hoạ về một chỉ mục không phân cụm. Để quét toàn bộ file chứa các bản ghi nhân viên, chúng ta có thể quét mức lá của chỉ mục này và với mỗi cổng vào dữ liệu quét bản ghi dữ liệu tương ứng nằm trong file để thu được các bản ghi dữ liệu được sắp theo (age, sal).
Chúng ta có thể đọc tất cả các cổng vào dữ liệu với chi phí 0.15B(D+6.7RC) I/Os. Bây giờ chúng ta đi đến một phần quan trọng: Chúng ta phải tìm các bản ghi dữ liệu với mỗi cổng vào dữ liệu trong chỉ mục này. Chi phí của việc tìm các bản ghi nhân viên là một I/O ứng với mỗi bản ghi, vì chỉ mục này không phân cụm và mỗi cổng vào dữ liệu trên một trang lá của chỉ mục này có thể trỏ đến một trang khác trong file nhân viên. Chi phí của bước này là BR(D+C). Nếu chúng ta muốn các bản ghi nhân viên được sắp theo thứ tự, sẽ là tốt hơn nếu chúng ta bỏ qua chỉ mục này và quét file nhân viên một cách trực tiếp và sau đó sắp xếp nó. Một quy tắc đơn giản là file có thể được sắp bằng thuật toán hai-đường trong đó mỗi đường yêu cầu đọc và ghi toàn bộ file. Vì thế, chi phí I/O của việc sắp xếp file có B trang là AB, chi phí này ít hơn nhiều so với chi phí sử dụng chỉ mục không phân cụm.
Tìm kiếm với phép chọn bằng: Chúng ta giả sử rằng phép chọn bằng được so sánh trên khoá tìm kiếm (age, sal). Chúng ta có thể xác định được trang đầu tiên chứa cổng vào dữ liệu cần tìm trong logf0.15B bước, tức là bằng với việc tìm ra tất cả các trang từ gốc đến lá phù hợp. Mỗi bước yêu cầu một I/O đĩa và hai phép so sánh. Đối với mỗi trang, cổng vào dữ liệu thoả mãn đầu tiên có thể được định vị lại bằng một tìm kiếm nhị phân trên trang này với chi phí bằng Clog26.7R. Bản ghi dữ liệu thoả mãn đầu tiên có thể được tìm trong file nhân viên bằng một thao tác I/O khác. Tổng chi phí là DlogF0.15B + Clog26.7R + D, nó được cải thiện đáng kể so với tìm kiếm trên các sorted files.
Nếu có một số bản ghi thoả mãn (ví dụ, “Tìm tất cả các bản ghi có age=18”), chúng không được bảo đảm là liền kề nhau. Chi phí truy cập tất cả các bản ghi này là chi phí định vị cổng vào dữ liệu thoả mãn đầu tiên DlogF0.15B + Clog26.7R cộng với một thao tác I/O ứng bvới một bản ghi thoả mãn. Vì thế chi phí sử dụng một chỉ mục không phân cụm phụ thuộc nhiều vào số lượng các bản ghi thoả mãn.
Tìm kiếm với phép chọn miền: Một lần nữa giả sử rằng phép chọn miền được so sánh với trên khoá tổ hợp này, bản ghi đầu tiên thoả mãn điều kiện chọn được xác định giống như trong tìm kiếm với điều kiện bằng. Sau đó, các cổng vào dữ liệu được truy cập một cách tuần tự (sử dụng các liên kết phía trước và phía sau ở mức lá của chỉ mục này) để tìm ra tất cả các bản ghi thoả mãn điều kiện. Với mỗi cổng vào dữ liệu thoả mãn, chúng ta phải mất thêm một thao tác I/O để truy cập các bản ghi nhân viên tương ứng. Chi phí có thể trở nên quá lớn một cách nhanh chóng khi số lượng các bản ghi thỏa mãn điều kiện chọn miền tăng lên. Như một quy tắc ngón tay cái, nếu 10% bản ghi dữ liệu thoả mãn điều kiện chọn, sẽ tốt hơn nếu chúng ta truy cập tất cả các bản ghi nhân viên, sắp xếp chúng và sau đó giữ lại những bản ghi thoả mãn điều kiện chọn.
Thêm: Đầu tiên chúng ta phải thêm bản ghi này vào heap file nhân viên, chi phí là 2D+C. Thêm nữa, chúng ta phải thêm cổng vào dữ liệu tương ứng trong chỉ mục này. Việc tìm một trang lá chính xác có cho phí DlogF0.5B + Clog26.7R, và viết nó ra ngoài sau khi thêm cổng vào dữ liệu mới mất chi phí là D.
Xoá: Chúng ta cần định vị bản ghi dữ liệu cần xoá trong file nhân viên và cổng vào dữ liệu trong file chỉ mục, và bước tìm kiếm này có chi phí Dlogf0.15B+ Clog26.7R + D. Sau đó chúng ta cần viết ra ngoài những trang đã bị thay đổi trong file chỉ mục và file dữ liệu, chi phí là 2D.
Heap File với Unclustered Hash Index
Giống như đối với unclustered tree indexes, chúng ta giả sử rằng mỗi cổng vào dữ liệu có kích thước bằng một phần mười kích thước một bản ghi dữ liệu. Chúng ta chỉ đề cập đến băm tĩnh trong phân tích của chúng ta, và để đơn giản chúng ta giả sử rằng không có các chuỗi tràn.
Trong một file được băm tĩnh, các trang thường sử dụng khoảng 80% khả năng lưu trữ của nó (để có vùng trống phục vụ thao tác thêm và tối thiểu hoá khả năng overflows khi file được mở rộng). Đạt được điều này bằng cách thêm một trang mới vào bucket khi các bản ghi được nạp vào hashed file nếu mỗi trang đang tồn tại đều đã sử dụng 80% khả năng của nó. Vì thế số lượng các trang cần để lưu các cổng vào dữ liệu sẽ bằng 1.25 lần số lượng các trang trong trường hợp các cổng vào dữ liệu đã đầy, tức là bằng 1.25(0.105) = 0.125B. Số lượng các cổng vào dữ liệu đặt vừa khít trong một trang là 10(0.80R) = 8R.
Quét: Như đối với unclustered tree index, tất cả các cổng vào dữ liệu có thể được truy cập với chi phí thấp, ở mức 0.125B(D + 8RC) I/Os. Tuy nhiên, với mỗi cổng vào dữ liệu, chúng ta phải chịu thêm một thao tác I/O để truy cập bản ghi dữ liệu tương ứng, chi phí của bước này là R(D + C). Chi phí này là quá lớn và thêm nữa, kết quả lại không được sắp xếp. Vì thế không có các thao tác quét trên chỉ mục băm.
Tìm kiếm với phép chọn bằng: Thao tác này được hỗ trợ rất hiệu quả bởi các phép chọn so sánh, tức là các điều kiện bằng được xác định với mỗi trường trong khoá tìm kiếm tổ hợp (age, sal). Chi phí của việc xác định một trang chứa các cổng vào dữ liệu thoả mãn là H. Giả sử rằng bucket này gồm chỉ một trang (tức là, không có các trang tràn), việc truy cập nó mất chi phí là D. Nếu chúng ta giả sử rằng chúng ta tìm các cổng vào dữ liệu sau khi quét một nửa số bản ghi trên trang này, chi phí của việc quét trang này là 0.5(8R)C = 4RC. Cuối cùng, chúng ta phải truy cập các cổng vào dữ liệu từ file nhân viên, chi phí là D. Vì thế, tổng chi phí là H + 2D + 4RC, chi phí này thậm chí còn thấp hơn chi phí đối với tree index.
Nếu một vài bản ghi thoả mãn, chúng không được đảm bảo là được đặt liền kề nhau. Chi phí truy cập tất cả các bản ghi như vậy bằng chi phí của việc xác định cổng vào dữ liệu đầu tiên thoả mãn (H + D + 4RC) cộng với một I /O ứng với một bản ghi thoả mãn. Vì thế, chi phí sử dụng chỉ mục không phân cụm phụ thuộc rất nhiều vào số lượng các bản ghi thoả mãn.
Tìm kiếm với phép chọn miền: Toàn bộ heap file chứa các bản ghi nhân viên phải được quét với chi phí là B(D + RC).
Thêm: Đầu tiên chúng ta phải thêm bản ghi này vào heap file, chi phí là 2D + C. Thêm nữa, trang tương ứng trong chỉ mục này phải được xác định, thay đổi để thêm một cổng vào dữ liệu mới, và sau đó viết nó trở lại đĩa. Chi phí là H + 2D + C.
Xoá: Chúng ta cần định vị bản ghi dữ liệu cần xoá trong file nhân viên và cổng vào dữ liệu trong file chỉ mục; bước tìm kiếm này có chi phí là H + 2D + 4RC. Bây giờ, chúng ta cần viết ra ngoài những trang được thay đổi trong chỉ mục và file dữ liệu, chi phí là 2D.
So sánh chi phí I/O
Hình 4 so sánh chi phí I/O với các cấu trúc file khác nhau chúng ta đã trình bày ở trên. Heap file có cách lưu trữ hiệu quả và hỗ trợ thao tác quét và thêm các bản ghi một cách nhanh chóng. Tuy nhiên, nó lại chậm trong các thao tác tìm kiếm và xoá.
Sort file cũng có cách lưu trữ hiệu quả, nhưng lại chậm trong các thao tác thêm và xoá bản ghi. Việc tìm kiếm thực hiện nhanh hơn trong heap files. Bạn nên ghi nhớ rằng trong một DBMS thực, một file dường như không bao giờ được sắp xếp hoàn toàn.

Clustered file có tất cả các ưu điểm của sorted file và nó hỗ trợ việc thêm và xoá một cách hiệu quả. Tìm kiếm thậm chí còn nhanh hơn cả sorted files, mặc dù sorted file có thể nhanh hơn khi có một số lượng lớn các bản ghi dữ liệu được truy cập một cách tuần tự, vì I/O theo khối được thực hiện hiệu quả.
Unclustered tree và hash indexes thực hiện tìm kiếm, thêm và xoá nhanh hơn nhưng quét và tìm kiếm miền lại chậm. Hash indexes thực hiện nhanh hơn một chút trên các tìm kiếm bằng, nhưng chúng không hỗ trợ tìm kiếm miền.
Tóm lại, Hình 4 chỉ ra rằng không có tổ chức file nào hiệu quả hơn hẳn trong tất cả các trường hợp.
Chỉ mục và điều chỉnh hiệu xuất
Trong phần này, chúng ta trình bày tổng quan về những lựa chọn khi sử dụng các chỉ mục để cải thiện thực thi trong một hệ thống cơ sở dữ liệu. Việc lựa chọn chỉ mục có ảnh hưởng rất lớn đến quá trình thực thi hệ thống, và phải được thực hiện trong ngữ cảnh một lưu lượng công việc nào đó, hoặc các thao tác truy vấn và cập nhật.
Khi nghiên cứu về các chỉ mục và thực thi yêu cầu chúng ta phải hiểu về cách đánh giá truy vấn và điều khiển tương tranh. Vì thế chúng ta quay trở lại chủ đề này trong Chương 20, chương này chúng ta sẽ bàn luận về phần này. Cụ thể, chúng ta sẽ nghiên cứu các ví dụ bao gồm nhiều bảng trong Chương 20 vì nó yêu cầu có những hiểu biết nhất dịnh về các thuật toán kết nối và các kế hoạch đánh giá truy vấn.
Tác động của Lưu lượng công việc
Điều đầu tiên được xem xét là lưu lượng công việc nào cần thực thi và những thao tác phổ biến. Các tổ chức file và các chỉ mục khác nhau tạo ra sự khác nhau trong thực thi các phép toán, phần này chúng ta đã nghiên cứu ở trên.
Nói chung, chỉ mục giúp truy cập các cổng vào dữ liệu thoả mãn điều kiện chọn nào đó một cách hiệu quả. Nhớ lại trong phần trước chúng ta có hai kiểu phép chọn quan trọng: phép chọn bằng và phép chọn miền. Công nghệ chỉ mục hoá dựa trên băm được tối ưu chỉ cho những phép chọn bằng và thực sự không tốt trong các phép chọn miền, nó còn không tốt bằng cách quét toàn bộ các bản ghi. Công nghệ chỉ mục hoá dựa trên cây hỗ trợ cả hai loại phép chọn này một cách hiệu quả đã giải thích vì sao chúng được sử dụng rộng rãi. Cả chỉ mục cây và băm đều hỗ trợ các phép thêm, xoá và sửa thực sự hiệu quả. Đặc biệt, chỉ mục dựa trên cây yêu cầu file chứa các bản ghi đã được sắp xếp. Những bàn luận của chúng ta về các chỉ mục có cấu trúc cây (B+tree) trong Phần 3.2 nhấn mạnh hai ưu điểm quan trọng của các files được sắp:
- Chúng ta có thể quản lý việc thêm và xoá các cổng vào dữ liệu một cách hiệu quả.
- Việc tìm ra trang lá chứa một bản ghi cần tìm theo giá trị khoá tìm kiếm nhanh hơn nhiều so với tìm kiếm nhị phân trên các trang trong một file được sắp.
Một nhược điểm là các trang trong file được sắp có thể được đặt trên đĩa theo thứ tự vật lý, làm nó nhanh hơn nhiều so với truy cập một vài trang theo thứ tự tuần tự. Tất nhiên, việc thêm và xoá trên một file được sắp phải trả một chi phí rất lớn. Một biến thể của B+trees được gọi là Indexed Sequential Access Method (ISAM) đưa ra những lợi ích của việc định vị các trang lá một cách tuần tự. Các thao tác thêm và xoá không được quản lý tốt trong các B-|- trees, nhưng lại tốt hơn trong một file được sắp xếp. Chúng ta sẽ nghiên cứu về các chỉ mục cấu trúc cây chi tiết trong Chương 10.
Tổ chức Chỉ mục phân cụm
Như chúng ta đã nhìn thấy trong Phần 2.1, một chỉ mục phân cụm là một tổ chức file chứa các bản ghi dữ liệu bên dưới. Các bản ghi dữ liệu có thể lớn, và chúng ta nên tránh tái tạo chúng; vì thế chỉ có nhiều nhất một chỉ mục phân cụm ứng với một tập các bản ghi. Mặt khác, chúng ta có thể xây dựng một vài chỉ mục không phân cụm trên một file dữ liệu. Giả sử rằng các bản ghi nhân viên được sắp xếp theo age, hoặc sắp xếp trong clustered file với khoá tìm kiếm là age. Thêm nữa, nếu chúng ta có một chỉ mục trên trường sal. Chúng ta cũng có thể xây dựng một chỉ mục không phân cụm trên department, nếu ở đó có một trường như vậy.
Duy trì một Chỉ mục phân cụm đắt hơn so với duy trì một file được sắp xếp hoàn toán. Khi một bản ghi mới được thêm vào một trang lá đã đầy, trang lá mới phải được định vị và một vài bản ghi đang tồn tại phải được chuyển đến trang mới này. Nếu các bản ghi được xác định bằng page id kết hợp với slot(khe) như trong các hệ cơ sở dữ liệu hiện tại, thì tất cả các vùng trong cơ sở dữ liệu trỏ tới bản ghi được di chuyển này phải được cập nhật lại để nó trỏ tới vùng mới. Việc định vị tất cả các vùng như vậy và thực hiện những cập nhật này có thể cần một vài thao tác I/O đĩa. Việc phân cụm (Clustering) phải được sử dụng rất thận trọng, chỉ cần khi những truy vấn có tần suất sử dụng thường xuyên được hưởng lợi nhiều từ việc phân cụm này. Đặc biệt, không có lý do xác đáng nào để xây dựng một clustered file sử dụng băm vì các truy vấn miền không thể được trả lời bằng cách sử dụng các chỉ mục băm.
Để đối mặt với giới hạn là chỉ có duy nhất một chỉ mục có thể được phân cụm, chúng ta nên xem xét xem khoá tìm kiếm của chỉ mục có thể trả lời truy vấn hiệu quả không. Nếu như vậy, các hệ thống cơ sở dữ liệu hiện đại đủ thông minh để tránh việc truy cập các bản ghi dữ liệu thực sự. Ví dụ, nếu chúng ta có một chỉ mục trên age, và chúng ta muốn tính tuổi tung bình của các nhân viên, DBMS có thể làm điều này bằng một kiểm tra đơn giản trên toàn bộ chỉ mục này. Đây là một ví dụ của đánh giá chỉ-chỉ-số. Trong đánh giá chỉ-chỉ-số của một truy vấn nào đó, chúng ta không cần quét toàn bộ các bản ghi dữ liệu trong các file chứa các quan hệ liên quan trong truy vấn này; chúng ta có thể đánh giá truy vấn này hoàn toàn dựa vào các chỉ mục trên các files. Một lợi ích quan trọng của đánh giá chỉ-chỉ-số là nó làm việc hiệu quả với các chỉ mục không phân cụm, và chỉ những cổng vào dữ liệu của chỉ mục này được sử dụng trong các truy vấn. Vì thế, chỉ mục không phân cụm có thể được sử dụng để tăng tốc các truy vấn hiện tại nếu chúng ta nhận ra rằng DBMS này sẽ khai thác đánh giá chỉ-chỉ-số.
Thiết kế các ví dụ minh hoạ Chỉ mục phân cụm
Để minh hoạ việc sử dụng chỉ mục phân cụm trên một truy vấn miền, xem xét một ví dụ sau:
SELECT E.dno
FROM Employees E
WHERE E.age > 40
Nếu chúng ta có một chỉ mục B+tree trên age, chúng ta có thể sử dụng nó để truy cập chỉ những bộ giá trị thoả mãn điều kiện chọn E.age> 40. Tỷ lệ nhân viên có tuổi lớn hơn 40 là bao nhiêu? Nếu gần như tất cả mọi người đều có tuổi lớn hơn 40, chúng ta sẽ hưởng lợi từ việc sử dụng một chỉ mục trên age; việc quét tuần tự của quan hệ này cũng sẽ có hiệu quả tương tự. Tuy nhiên, giả sử rằng chỉ có 10% nhân viên có tuổi lớn hơn 40, thì sử dụng chỉ mục nào sẽ hữu ích? Câu trả lời phụ thuộc vào việc có hay không một chỉ mục được phân cụm. Nếu chỉ mục này không phân cụm, chúng ta có thể có một trang I/O với mỗi nhân viên, và thực hiện như vậy sẽ phải trả chi phí cao hơn việc thực hiện quét tuần tự, thậm chí chỉ 10% nhân viên thoả mãn yêu cầu! Mặt khác, một chỉ mục B+tree phân cụm trên age yêu cầu chỉ 10% của I/Os đối với quét tuần tự (bỏ qua một vài I/Os cần để duyệt từ gốc đến trang lá được truy cập đầu tiên và I/Os cho các lá của chỉ mục liên quan).
Ví dụ khác, xem xét sự tinh chỉnh sau của truy vấn phía trên:
SELECT E.dno, COUNT(*)
FROM Employees E
WHERE E.age > 10
GROUP BY E.dno
Nếu B+tree index đang sẵn sàng trên trường age, chúng ta có thể truy cập các bộ giá trị sử dụng nó, sắp xếp các bộ giá trị được truy cập trên dno, và vì thế trả lời được truy vấn này. Tuy nhiê, đây có lẽ không phải là kế hoạch tốt nếu hầu như tất cả các nhân viên có tuổi lớn hơn 10. Kế hoạch này đặc biệt không hiệu quả nếu chỉ mục này không phải là chỉ mục phân cụm.
Hãy cùng chúng tôi xem xét xem liệu chỉ mục trên dno có thể phù hợp với mục đích của chúng ta hơn không. Chúng tôi có thể sử dụng chỉ mục này để truy cập tất cả các bộ giá trị, nhóm theo dno, và đếm số lượng các bộ giá trị có age>10 với mỗi dno. (Chiến lược này có thể được sử dụng với cả các chỉ mục băm và B+tree; chúng ta chỉ yêu cầu các bộ giá trị được nhóm, không cần thiết được sắp xếp theo dno.) Thêm nữa, hiệu quả phụ thuộc chủ yếu vào việc có hay không một chỉ mục được phân cụm. Nếu là có, kế hoạch này dường như là kế hoạch tốt nhất nếu điều kiện trên age không qua khắt khe. (Dù là chúng ta có một chỉ mục không phân cụm trên age, nếu điều kiện trên age không quá khắt khe, chi phí của việc sắp xếp các bộ giá trị trên dno sẽ khá cao.) Nếu chỉ mục này không được phân cụm, chúng ta có thể thực hiện một trang I/O trên mỗi bộ giá trị trong Employees, và kế hoạch này sẽ phải trả một giá đắt ‘khủng khiếp’. Thực vậy, nếu chỉ mục này không được phân cụm, bộ tối ưu hoá sẽ lựa chọn kế hoạch dựa trên việc sắp xếp trên dno. Vì thế, truy vấn này đề nghi rằng chúng ta xây dựng một chỉ mục phân cụm trên dno nếu điều kiện trên age không quá khắt khe. Nếu điều này quá khắt khe, chúng ta sẽ xem xét việc xây dựng một chỉ mục (không cần thiết phải phân cụm) trên age thay vào đó.
Việc phân cụm cũng quan trọng cho một chỉ mục được xây dựng dựa trên khoá tìm kiếm mà khoá tìm kiếm này không chứa khoá dự tuyển, tức là, một chỉ mục trong đó có một một vài cổng vào dữ liệu có thể có cùng một giá trị khoá. Để minh hoạ điểm này, chúng tôi trình bày về truy vấn sau:
SELECT E.dno
FROM Employees E
WHERE E.hobby='Stamps'
Nếu rất nhiều người sưu tập tem (stamps), việc truy cập các bộ giá trị thông qua một chỉ mục không phân cụm trên hobby có thể rất không hiệu quả. Nó có lẽ rẻ hơn nếu chỉ quét quan hệ này để truy cập tất cả các bộ giá trị và áp đặt việc chọn on-the-fly tới các bộ giá trị được truy cập.
Vì thế, nếu một truy vấn nào đó quá quan trọng, chúng ta nên xem xét việc xây dựng một chỉ mục trên trường hobby là chỉ mục phân cụm. Mặt khác, nếu chúng ta giả sử rằng eid là khoá của Employees, và thay thế điều kiện E.hobby ='Stamps' bằng E.eid=552, chúng ta biết rằng có nhiều nhất một bộ giá trị của Employees sẽ thoả mãn điều kiện chọn này. Trong trường hợp này, sẽ không có ích lợi nào của việc xây dựng một chỉ mục phân cụm.
Truy vấn tiếp theo chỉ ra các hàm nhóm ảnh hưởng như thế nào đến việc lựa chọn các chỉ mục:
SELECT E.dno, C0UNT(*)
FROM Employees E
GROUP BY E.dno
Một kế hoạch rõ ràng cho truy vấn này là sắp xếp Employees trên dno để tính toán số lượng các nhân viên ứng với mỗi dno. Tuy nhiên, nếu một chỉ mục nào đó- băm hoặc B+tree trên dno đang sẵn sàng, chúng ta có thể thực hiện truy vấn này chỉ bằng cách quét trên chỉ mục. Với mỗi giá trị dno, chúng ta chỉ đơn giản là đếm số lượng các cổng vào dữ liệu trong chỉ mục này. Ghi nhớ rằng sẽ không có vấn đề gì về việc chỉ mục này được phân cụm hay không vì chúng ta không bao giờ truy cập những bộ giá trị của Employees.
Khoá tìm kiếm tổ hợp
Khoá tìm kiếm của một chỉ mục có thể chứa một vài trường; những khoá như vậy được gọi là khoá tìm kiếm tổ hợp hoặc các khoá móc nối. Ví dụ, xem xét tập hợp các bản ghi nhân viên, với các trường name, age, và sal, được lưu trữ theo thứ tự sắp xếp của name. Hình 5 minh hoạ sự khác nhau giữa chỉ mục tổ hợp có khoá là (age, sat), chỉ mục tổ hợp có khoá là (sal, age), một chỉ mục có khoá là age, và một chỉ mục có khoá là sal. Tất cả các chỉ mục được minh hoạ trong hình này đều sử dụng Alternative(2) cho các cổng vào dữ liệu.
Nếu một khóa tìm kiếm là tổ hợp, một truy vấn bằng là một truy vấn mà mỗi trường trong đó được gán bằng một hằng số cụ thể. Ví dụ, chúng ta có thể yêu cầu để truy cập tất các cổng vào dữ liệu với age = 20 và sal = 10. Tổ chức file băm hỗ trợ chỉ những truy vấn bằng, vì sử dụng một hàm băm sẽ xác định được bucket chứa các bản ghi cần tìm chỉ khi có một giá trị được xác định ứng với mỗi trường trong khoá tìm kiếm.
Đối với một chỉ mục khoá tổ hợp, trong truy vấn miền không phải tất cả các trường trong khoá tìm kiếm này được gán với giá trị hằng số. Ví dụ, chúng ta có thể yêu cầu truy cập tất cả các cổng vào dữ liệu có age=20; truy vấn này ngụ ý trường sal có thể nhận giá trị bất kỳ. Ví dụ khác của truy vấn miền, chúng ta có thể yêu cầu truy cập các bộ giá trị thoả mãn điều kiện age < 30 và sal > 40.

Ghi nhớ rằng chỉ mục này không thể giúp đỡ truy vấn sal > 40, vì như quan sát, chỉ mục này tổ chức các bản ghi theo trường age đầu tiên, sau đó đến trường sal. Nếu age không được xác định ở bên trái, các bản ghi thoả mãn có thể nằm trải rộng trên toàn bộ chỉ mục. Chúng ta nói rằng một chỉ mục nào đó phù hợp với một điều kiện chọn nào đó nếu chỉ mục này có thể được sử dụng để truy cập chỉ những bộ giá trị thoả mãn điều kiện này. Với các điều kiện chọn có dạng condition ∧…∧ condition, chúng ta có thể định nghĩa khi nào một chỉ mục phù hợp với điều kiện chọn như sau:
Sự cân bằng trong việc lựa chọn khoá tổ hợp
Một chỉ mục khoá tổ hợp có thể hỗ trợ một miền rộng lớn của các truy vấn vì nó phù hợp với nhiều điều kiện chọn. Thêm nữa, vì các cổng vào dữ liệu trong một chỉ mục tổ hợp chứa nhiều thông tin về bản ghi dữ liệu (tức là, nhiều trường hơn so với chỉ mục một-thuộc-tính), có nhiều cơ hội hơn cho các chiến lược đánh giá chỉ chỉ mục. (Nhớ lại trong phần 5.2 rằng một đánh giá chỉ chỉ mục không cần truy cập tới các bản ghi dữ liệu, nhưng cần tìm tất cả các giá trị của trường được yêu cầu trong cổng vào dữ liệu của các chỉ mục.)
Mặt tiêu cực là, một chỉ mục tổ hợp phải được cập nhật khi có bất kỳ thao tác (thêm, sửa, xoá) nào thực hiện trên bất kỳ trường nào trong khoá tìm kiếm này. Một chỉ mục tổ hợp dường như cũng lớn hơn một khoá tìm kiếm một-thuộc-tính vì kích thước của các cổng vào dữ liệu lớn hơn. Với một chỉ mục B+tree tổ hợp, điều này cũng có nghĩa là tiềm năng tăng lên theo số lượng các mức, mặc dù khả năng nén khoá có thể được sử dụng để giảm nhẹ vấn đề này (xem Phần 10.8.1)
Các ví dụ của khoá tổ hợp
Xem xét truy vấn sau đây, truy vấn này trả về tất cả các nhân viên có 20 < age < 30 và 3000 < sal < 5000:
SELECT E.eid
FROM Employees E
WHERE E.age BETWEEN 20 AND 30
AND E.sal BETWEEN 3000 AND 5000
Chỉ mục tổ hợp trên (age, sal) có thể giúp đỡ thực thi truy vấn này nếu các điều kiện trong mệnh đề WHERE là các phép chọn rõ ràng. Hiển nhiên, một chỉ mục băm sẽ không giúp đỡ thực thi truy vấn này; một chỉ mục B+ tree (hoặc ISAM) được yêu cầu. Rõ ràng rằng một chỉ mục phân cụm dường như hiệu quả hơn một chỉ mục không phân cụm. Với truy vấn này, các điều kiện trên age và sal là các phép chọn bằng, một chỉ mục B+tree trên (age, sal) sẽ hiệu quả như sử dụng chỉ mục phân cụm B+tree trên (sal, age). Tuy nhiên, thứ thự của các thuộc tính trong khoá tìm kiếm có thể gây ra vấn đề lớn, như minh hoạ trong truy vấn tiếp theo:
SELECT E.eid
FROM Employees E
WHERE E.age = 25
AND E.sal BETWEEN 3000 AND 5000
Trong ví dụ của truy vấn này, chỉ mục phân cụm B+tree trên (age, sal) sẽ mang đến một thực thi tốt vì các bản ghi được sắp xếp theo age đầu tiên (nếu hai bản ghi có cùng giá trị age) sau đó mới đến sal. Vì thế, tất cả các bản ghi có age=25 sẽ được phân cụm cùng nhau. Mặt khác, chỉ mục phân cụm B+tree trên (sal, age) sẽ không thực thi tốt bằng. Trong trường hợp này, các bản ghi đầu tiên được sắp xếp theo sal, và vì thế hai bản ghi có cùng giá trị age (cụ thể, age=25) có thể thực sự ở cách xa nhau. Thực tế mà nó, chỉ mục này cho phép chúng ta sử dụng các truy vấn miền trên sal, nhưng không phải là các truy vấn bằng trên age để truy cập các bộ giá trị. (Thực thi tốt trên cả hai biến thể của truy vấn này có thể đạt được bằng cách sử dụng một chỉ mục không gian đơn. Chúng ta sẽ bàn về các loại chỉ mục này trong Chương 28)
Các chỉ mục tổ hợp sẽ hữu ích trong việc đối mặt với rất nhiều các truy vấn có hàm nhóm. Xem xét:
SELECT AVG (E.sal)
FROM Employees E
WHERE E.age = 25
AND E.sal BETWEEN 3000 AND 5000
Một chỉ mục tổ hợp B+tree trên (age, sal) cho phép chúng trả lời truy vấn này bằng việc quét chỉ-chỉ-số. Một chỉ mục tổ hợp B+tree trên (sal, age) cũng cho phép chúng ta trả lời truy vấn này bằng việc quét chỉ-chỉ-số, mặc dù trong trường hợp này có nhiều các cổng vào dữ liệu chỉ mục được truy cập hơn là trong trường hợp sử dụng chỉ mục trên (age, sal).
Đây là một biến thể của ví dụ phía trên:
SELECT E.dno, COUNT(*)
FROM Employees E
WHERE E.sal= 10,000
GROUP BY E.dno
Một chỉ mục nào đó trên chỉ dno không cho phép chúng ta định giá truy vấn này cùng với việc quét chỉ-chỉ-số, vì chúng ta cần tìm trường sal của mỗi bộ giá trị để xác định điều kiện sal = 10,000. Tuy nhiên, chúng ta có thể sử dụng kế hoạch chỉ-chỉ-số nếu chúng ta có một chỉ mục tổ hợp B+tree trên (sal, dno) hoặc (dno, sal). Trong một chỉ mục với khoá là (sal, dno), tất cả các cổng vào dữ liệu có sal = 10,000 được đặt sát nhau. (dù chỉ mục này được phân cụm hay không). Thêm nữa, các cổng vào dữ liệu được sắp xếp theo dno, nên nó dễ dàng để đếm được số lượng các bản ghi trong mỗi nhóm dno. Ghi nhớ rằng chúng ta cần truy cập chỉ những cổng vào dữ liệu có sal = 10,000.
Một quan sát đáng giá là chiến lược này không làm việc nếu mệnh đề WHERE được thay đổi để sử dụng sal > 10,000. Mặc dù nó thoả mãn để truy cập chỉ những cổng vào dữ liệu chỉ mục- tức là, một chiến lược chỉ-chỉ-số vẫn được áp dụng- các cổng vào dữ liệu này bây giờ phải được sắp xếp theo dno để định danh các nhóm (vì hai cổng vào dữ liệu có cùng một dno nhưng khác nhau giá trị của sal vẫn không được đặt gần nhau.) Một chỉ mục cùng với khoá (dno, sal) sẽ tốt hơn cho truy vấn này: Các cổng vào dữ liệu cùng với một giá trị dno cung cấp được sắp xếp cùng nhau, và mỗi nhóm các cổng vào dữ liệu như vậy tự bản thân nó được sắp xếp theo sal. Với mỗi nhóm dno, chúng ta có thể loại bỏ các cổng vào dữ liệu cùng với sal không lớn hơn 10,000 và đếm phần còn lại. (Sử dụng chỉ mục này ít hiệu quả hơn là quét chỉ-chỉ-số với khoá (sal, dno) cho truy vấn với sal = 10,000, vì chúng ta phải đọc tất cả các cổng vào dữ liệu.)
Ví dụ, giả sử chúng ta muốn tìm lương nhỏ nhất ứng với mỗi dno.
SELECT E.dno, MIN(E.sal)
FROM Employees E
GROUP BY E.dno
Một chỉ mục nào đó chỉ trên dno không cho phép chúng ta đánh giá truy vấn này bằng cách thực hiện quét chỉ-chỉ-số. Tuy nhiên, chúng ta có thể sử dụng kế hoạch chỉ-chỉ-số nếu chúng ta có một chỉ mục tổ hợp B+tree trên (dno, sal). Ghi nhớ rằng tất cả các cổng vào dữ liệu trong chỉ mục này cùng với một giá trị dno cung cấp được lưu trữ cùng nhau (dù chỉ mục này có được phân cụm hay không). Thêm nữa, nhóm của các cổng vào dữ liệu này tự bản thân nó được sắp xếp theo sal. Một chỉ mục trên (sal, dno) cho phép chúng ta tránh truy cập các bản ghi dữ liệu, nhưng các cổng vào dữ liệu chỉ mục phải được lưu trữ trên dno.
Thực thi chỉ mục trong SQL: 1999
Một câu hỏi tự nhiên đến trong lúc này là chúng ta có thể tạo các chỉ mục trong SQL như thế nào. Chuẩn SQL: 1999 không chứa bất cứ câu lệnh tạo hay xoá các cấu trúc chỉ mục. Thực tế, chuẩn này thậm chí không yêu cầu SQL hỗ trợ thực thi chỉ mục! Nhưng trong thực tiễn, tất nhiên tất cả các phần mềm DBMS quan hệ đều hỗ trợ một hoặc nhiều loại chỉ mục. Câu lệnh sau tạo một chỉ mục B+tree như sau – chúng ta bàn về các chỉ mục B+tree trong Chương 10.
CREATE INDEX IndAgeRating ON Students
WITH STRUCTURE = BTREE,
KEY = (age, gpa)
Điều này chỉ ra rằng chỉ mục B+trê được tạo trên bảng Students sử dụng hai cột age và gpa như là khoá. Vì thế, các giá trị khoá được cặp đôi dưới dạng (age, gpa) và có một cổng vào phân biện cho mỗi cặp như vậy. Ngay khi được tạo, chỉ mục này được DBMS duy trì một cách tự động bằng cách thêm hoặc loại bỏ các cổng vào dữ liệu tương ứng với việc thêm và xoá các bản ghi trên quan hệ Students.
Câu hỏi ôn tập
Trả lời những câu hỏi tổng kết sau, câu trả lời có thể tìm thấy trong các phần được liệt kê bên cạnh.
- DBMS lưu trữ các dữ liệu ổn định ở đâu? Nó mang dữ liệu vào bộ nhớ chính để xử lý như thế nào? Thành phần DBMS nào đọc và ghi dữ liệu từ bộ nhớ chính, và đơn vị I/O là gì? (Phần 1)
- Tổ chức file là gì? Chỉ mục là gì? Mối quan hệ giữa các file và các chỉ mục? Chúng ta có thể có một vài chỉ mục trên một file chứa các bản ghi được không? Một chỉ mục bản thân nó có thể lưu trữ các bản ghi dữ liệu được không (tức là, làm việc như file)? (Phần 2)
- Khoá tìm kiếm cho một chỉ mục là gì? Cổng vào dữ liệu trong một chỉ mục là gì? (Phần 2)
- Chỉ mục phân cụm là gì? Chỉ mục chính là gì? Có bao nhiêu chỉ mục phân cụm được xây dựng trên một file? Có bao nhiêu chỉ mục không được phân cụm có thể được xây dựng trên một file? (Phần 2.1)
- Dữ liệu được tổ chức như thế nào trong hash-based index? Khi nào bạn sẽ sử dụng hash-based index? (Phần 3.1)
- Dữ liệu được tổ chức như thế nào trong tree-based index? Khi nào bạn sẽ sử dụng tree-based index? (Phần 3.2)
- Xem xét các phép thực thi sau: quét, phép chọn bằng và chọn miền, thêm, xoá, và các tổ chức file sau: heap files,sorted files, clustered files, heap files cùng với một unclustered tree index trên khoá tìm kiếm, và heap files cùng với một unclustered hash index. Tổ chức file nào là phù hợp nhất đối với mỗi phép toán (Phần 4)
- Cái gì đóng góp chính đối vào chi phí của các phép toán cơ sở dữ liệu? Bàn về mô hình chi phí đơn giản để phản ánh điều này. (Phần 4.1)
- Lưu lượng công việc ảnh hưởng như thế nào đến thiết kế cơ sở dữ liệu vật lý để có những quyết định như là những chỉ mục nào sẽ được xây dựng? Vì sao việc lựa chọn chỉ mục ảnh hưởng quan trọng đến thiết kế cơ sở dữ liệu vật lý? (Phần 5)
- Những vấn đề nào được xem xét trong việc sử dụng các chỉ mục phân cụm? Phương pháp đánh giá chỉ-chỉ-số là gì? Lợi ích chính của nó là gì? (Phần 5.2)
- Khoá tìm kiếm tổ hợp là gì? Những ưu và nhược điểm của khoá tìm kiếm tổ hợp là gì? (Phần 5.3)
- Các câu lệnh SQL nào hỗ trợ việc tạo chỉ mục? (Phần 5.4)
Bài tập
Trả lời những câu hỏi sau về dữ liệu trên bộ nhớ ngoài trong một DBMS:
- Vì sao DBMS lưu trữ dữ liệu trên bộ nhớ ngoài?
- Vì sau chi phí I/O đóng vai trò quan trọng trong DBMS?
- Record id là gì? Cho một record id, có bao nhiêu thao tác I/O cần thiết để đưa được bản ghi này vào bộ nhớ chính.
Vai trò của bộ quản lý vùng đệm trong một DBMS? Vai trò của bộ quản lý khoảng không đĩa? Các lớp này tương tác với lớp phương thức truy cập và file (file and access methods layer) như thế nào?
Câu trả lời với mỗi câu hỏi như sau:
- Một DBMS lưu trữ dữ liệu ở bộ nhớ ngoài vì số lượng dữ liệu vô cùng lớn, và nó vẫn phải duy trì những thực thi của các chương trình.
- Chi phí I/O đặc biệt quan trọng với DBMS vì chi phí của nó chi phối rất lớn đến hầu hết các thao tác cơ sở dữ liệu. Việc tối ưu hóa các thao tác I/O có thể giúp cải thiện đáng kể tốc độ thực thi hệ thống.
- Một record id, gọi tắt là rid, cho phép định danh một bản ghi cụ thể trong một tập các bản ghi. Rid có tính chất là chúng ta có thể xác định được địa chỉ đĩa của trang đang chứa bản ghi này. Số lượng các yêu cầu I/O để đọc một bản ghi được gọi là 1 I/O.
- Trong một DBMS, bộ quản lý vùng đệm đọc dữ liệu từ nơi đang lưu trữ nó vào trong bộ nhớ cũng như viết dữ liệu từ bộ nhớ vào trong vùng lưu trữ. Bộ quản lý đĩa quản lý các cùng lưu trữ vật lý của dữ liệu cho DBMS. Khi file và lớp phương pháp truy cập cần xử lý đĩa, nó yêu cầu bộ quản lý vùng đệm nạp các trang và đặt nó vào bộ nhớ nếu nó đang không sẵn sàng trong bộ nhớ. Khi các file và lớp phương pháp truy cập cần thêm không gian để lưu trữ bản ghi mới vào trong một file nào nó, nó yêu cầu bộ quản lý không gian đĩa chỉ định một trang đĩa bổ sung.
Trả lời những câu hỏi sau về dữ liệu trên bộ nhớ ngoài trong một DBMS:
- Vì sao DBMS lưu trữ dữ liệu trên bộ nhớ ngoài?
- Vì sau chi phí I/O đóng vai trò quan trọng trong DBMS?
- Record id là gì? Cho một record id, có bao nhiêu thao tác I/O cần thiết để đưa được bản ghi này vào bộ nhớ chính.
Vai trò của bộ quản lý vùng đệm trong một DBMS? Vai trò của bộ quản lý khoảng không đĩa? Các lớp này tương tác với lớp phương thức truy cập và file (file and access methods layer) như thế nào?
Câu trả lời với mỗi câu hỏi như sau:
1. Một DBMS lưu trữ dữ liệu ở bộ nhớ ngoài vì số lượng dữ liệu vô cùng lớn, và nó vẫn phải duy trì những thực thi của các chương trình.
2. Chi phí I/O đặc biệt quan trọng với DBMS vì chi phí của nó chi phối rất lớn đến hầu hết các thao tác cơ sở dữ liệu. Việc tối ưu hóa các thao tác I/O có thể giúp cải thiện đáng kể tốc độ thực thi hệ thống.
3. Một record id, gọi tắt là rid, cho phép định danh một bản ghi cụ thể trong một tập các bản ghi. Rid có tính chất là chúng ta có thể xác định được địa chỉ đĩa của trang đang chứa bản ghi này. Số lượng các yêu cầu I/O để đọc một bản ghi được gọi là 1 I/O.
4. Trong một DBMS, bộ quản lý vùng đệm đọc dữ liệu từ nơi đang lưu trữ nó vào trong bộ nhớ cũng như viết dữ liệu từ bộ nhớ vào trong vùng lưu trữ. Bộ quản lý đĩa quản lý các cùng lưu trữ vật lý của dữ liệu cho DBMS. Khi file và lớp phương pháp truy cập cần xử lý đĩa, nó yêu cầu bộ quản lý vùng đệm nạp các trang và đặt nó vào bộ nhớ nếu nó đang không sẵn sàng trong bộ nhớ. Khi các file và lớp phương pháp truy cập cần thêm không gian để lưu trữ bản ghi mới vào trong một file nào nó, nó yêu cầu bộ quản lý không gian đĩa chỉ định một trang đĩa bổ sung.
Trả lời những câu hỏi sau về file và các chỉ mục:
- Các phép toán được hỗ trợ bởi file chứa các bản ghi?
- Chỉ mục trên file chứa các bản ghi là gì? Khoá tìm kiếm trên một chỉ mục là gì? Vì sao chúng ta cần đến các chỉ mục?
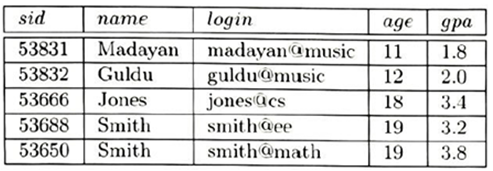
Minh hoạ của quan hệ Students được sắp xếp theo age - Các khả năng có thể của các cổng vào dữ liệu trong một chỉ mục nào đó?
- Sự khác nhau giữa chỉ mục chính và chỉ mục phụ? Cổng vào dữ liệu trùng lặp trong một chỉ mục? Chỉ mục chính có thể chứa sự trùng lặp không?
- Sự khác nhau giữa chỉ mục phân cụm và chỉ mục không phân cụm? Nếu một chỉ mục nào đó chứa các bản ghi dữ liệu giống như các ‘cổng vào dữ liệu’, nó có thể được không phân cụm (unclustered) không?
- Trên một file, bạn có thể tạo bao nhiêu chỉ mục được phân cụm? Bạn sẽ luôn tạo ít nhất một chỉ mục phân cụm cho một file?
- Xem xét Alternatives (1), (2) and (3) cho các 'cổng vào dữ liệu' trong một chỉ mục nào đó, như đã bàn đến trong Phần 8.2. Tất cả chúng đều thích hợp cho các chỉ mục thứ cấp? Giải thích.
Dành cho độc giả
Xem xét một quan hệ được lưu theo thứ tự sắp xếp ngẫu nhiên, trong đó chỉ có một chỉ mục không phân cụm trên trường sal. Nếu bạn muốn truy cập tới tất cả các bản ghi có sal > 20, thì sử dụng chỉ mục này luôn là lựa chọn tốt nhất? Giải thích?
Không. Trong trường hợp này, mỗi cổng vào dữ liệu thỏa mãn có thể chứa một rid, rid này trỏ tới một trang dữ liệu cụ thể, dẫn tới số lượng trang dữ liệu I/O bằng với số lượng các cổng vào dữ liệu thỏa mãn điều kiện của truy vấn. Trong trường hợp này, sử dụng chỉ mục sẽ không tốt như sử dụng phương pháp quét file.
Xem xét minh hoạ của quan hệ Students trong Hình 8.6, nó được sắp xếp theo age: Với những mục đích của câu hỏi này, giả sử rằng những bộ giá trị này được lưu trữ trong một file được sắp theo thứ tự đã chỉ ra; bộ giá trị đầu tiên trên trang 1, bộ giá trị thứ hai cũng ở trên trang 1; và tiếp tục. Mỗi trang có thể lưu trữ được ba bản ghi; vì thế bản ghi thứ 4 sẽ ở trên trang 2. Giải thích mỗi chỉ mục sau đây sẽ chứa những cổng vào dữ liệu nào. Nếu thứ tự của các cổng vào dữ liệu là quan trọng, thì điều gì xảy ra và giải thích vì sao. Nếu một chỉ mục nào đó không xây dựng được, hãy giải thích vì sao.
- Một chỉ mục không phân cụm trên age sử dụng Alternative (1).
- Một chỉ mục không phân cụm trên age sử dụng Alternative (2).
- Một chỉ mục không phân cụm trên age sử dụng Alternative (3).
- Một chỉ mục phân cụm trên age sử dụng Alternative (1).
- Một chỉ mục phân cụm trên age sử dụng Alternative (2).
- Một chỉ mục phân cụm trên age sử dụng Alternative (3).
- Một chỉ mục không phân cụm trên gpa sử dụng Alternative (1).
- Một chỉ mục không phân cụm trên gpa sử dụng Alternative (2).
- Một chỉ mục không phân cụm trên gpa sử dụng Alternative (3).
- Một chỉ mục phân cụm trên gpa sử dụng Alternative (1).
- Một chỉ mục phân cụm trên gpa sử dụng Alternative (2).
- Một chỉ mục phân cụm trên gpa sử dụng Alternative (3).

Dành cho độc giả
Giải thích sự khác nhau giữa các chỉ mục băm và chỉ mục B+tree. Cụ thể, trình bày các truy vấn bằng và truy vấn miền làm việc như thế nào thông qua một ví dụ.
Chỉ mục băm được xây dựng bằng việc sử dụng một hàm băm để ánh xạ nhanh chóng một giá trị khóa tìm kiếm đến một vùng cụ thể trong một mảng nào đó- giống như là một danh sách các phần tử và được gọi là buckets. Những buckets thường được xây dựng để ở đó có nhiều vùng buckets hơn là ở đó có nhiều giá trị khóa tìm kiếm, và hàm băm được lựa chọn để nó không thường xuyên xảy ra trường hợp hai giá trị khóa tìm kiếm có cùng một bucket. Chỉ mục B+tree được xây dựng bằng việc sắp xếp dữ liệu trên khóa tìm kiếm và duy trì cấu trúc dữ liệu tìm kiếm dạng phân cấp, cấu trúc này trực tiếp tìm ra một trang chính xác của các cổng vào dữ liệu. Việc thêm và xóa trong một chỉ mục dựa trên băm rất đơn giản. Nếu hai giá trị khóa tìm kiếm cùng băm tới một bucket, gọi là sự xung đột, thì một danh sách liên kết được hình thành để kết nối nhiều bản ghi trong một bucket đơn nào đó. Trong trường hợp có quá nhiều sự xung đột xảy ra, số lượng các buckets được tăng lên. Ngoài ra, việc duy trì một cấu trúc dữ liệu tìm kiếm phân cấp B+tree được coi là đắt đỏ hơn vì nó phải cập nhật lại khi có bất kỳ thao tác thêm hoặc xóa bản ghi dữ liệu. Nói chung, hầu hết thao tác thêm và xóa sẽ không sửa cấu trúc dữ liệu, nhưng cây sẽ phải cấu trúc lại khi nó trở nên quá-đầy.
Các chỉ mục băm đặc biệt tốt đối với các tìm kiếm bằng vì nó cho phép một bản ghi nào đó được tìm kiếm rất nhạn với chi phí trung bình là 1.2 I/Os. Mặt khác, các chỉ mục B+tree có chi phí từ 3-4 I/Os ứng với mỗi bản ghi. Giả sử rằng chúng ta có một quan hệ nhân viên có khó chính là eid và tổng số 10,000 bản ghi. Việc tìm kiếm tất cả các bản ghi sẽ mất chi phí là 12,000 I/Os đối với các chỉ mục băm, trong khi đó đối với các chỉ mục B+tree thì chi phí này là 30,000-40,000.
Với các truy vấn miền, các chỉ mục băm thực hiện rất không tốt, vì chúng có thể phải đọc một số lượng trang bằng với số lượng các bản ghi do dữ liệu không được sắp xếp theo nhóm hoặc tập hợp nào một cách dễ dàng. Mặt khác, các chỉ mục B+tree có chi phí 3-4 I/Os cộng với số lượng các trang hoặc các bộ giá trị thỏa mãn, tương ứng với chỉ mục B+tree phân cụm hay không phân cụm. Giả sử rằng chúng ta quay lại ví dụ về quan hệ nhân viên có 10,000 bản ghi và 10 bản ghi trên mỗi trang. Cũng như vậy, giả sử rằng ở đó có một chỉ mục trên sal và truy vấn với điều kiện age< 20, như vậy ở đây sẽ có 5,000 bản ghi thỏa mãn. Chỉ mục băm có thể có chi phí 1000,000 I/Os vì tất cả các trang có thể được đọc cho tất cả bản ghi. Một chỉ mục không phân cụm B+tree sẽ có chi phí là 5,004 I/Os trong khi một chỉ mục phân cụm B+tree sẽ có chi phí là 505 I/Os. Trong trường hợp này ta nên sử dụng một chỉ mục phân cụm bất cứ khi nào có thể.
Điền các chi phí I/O tương ứng trong Hình 7.
Dành cho độc giả
Nếu bạn được tạo một chỉ mục nào đó trên một quan hệ, bạn sẽ tuân theo những hướng dẫn nào? Bàn về:
- Lựa chọn chỉ mục chính.
- Các chỉ mục phân cụm khác với các chỉ mục không phân cụm.
- Các chỉ mục băm khác với các chỉ mục cây.
- Sử dụng một file được sắp hơn là sử dụng một chỉ mục dựa trên cây.
- Lựa chọn khoá tìm kiếm cho chỉ mục này. Khóa tìm kiếm tổ hợp là gì, và những hướng dẫn nào được thực hiện trong việc lựa chọn các khoá tìm kiếm tổ hợp. Các kế hoạch chỉ-chỉ-số là gì, và ảnh hưởng của các kế hoạch đánh giá chỉ-chỉ-số đối việc lựa chọn khoá tìm kiếm cho chỉ mục là gì?
Câu trả lời với mỗi câu hỏi như sau:
- Việc lựa chọn khóa chính được làm dựa trên ngữ nghĩa của dữ liệu. Nếu chúng ta cần truy cập các bản ghi dựa trên giá trị của khóa chính, chúng ta nên xây dựng một chỉ mục sử dụng khóa này như là khóa tìm kiếm. Nếu chúng ta cần truy cập các bản ghi dựa trên giá trị của các trường không liên quan đến khóa chính, thì chúng ta xây dựng chỉ mục phụ sử dụng (kết hợp) những trường này như là khóa tìm kiếm.
- Chỉ mục phân cụm cho phép thực hiện truy vấn miền tốt hơn nhiều, nhưng việc thực hiện tìm kiếm bằng cũng như chỉ mục không phân cụm. Thêm nữa, chi phí của việc duy trì chỉ mục phân cụm thông thường cao hơn chỉ mục không phân cụm. Vì thế, chúng ta nên tạo một chỉ mục phân cụm chỉ khi các truy vấn miền là quan trọng trên khóa tìm kiếm của nó. Chỉ có nhiều nhất là một chỉ mục phân cụm trên một quan hệ, và nếu các truy vấn miền mong muốn có nhiều hơn một sự kết hợp của nhiều trường, thì chúng ta phải chọn một sự kết hợp quan trọng nhất và làm nó thành khóa tìm kiếm của chỉ mục phân cụm.
- Nếu các chỉ mục miền được thực hiện thường xuyên, thì chúng ta nên sử dụng một B+tree trên chỉ mục này của quan hệ vì các chỉ mục băm không thể thực hiện được các truy vấn miền. Nếu các truy vấn bằng được thực hiện nhiều hơn thì chỉ mục băm là lựa chọn tốt nhất vì chúng cho phép truy cập nhanh hơn B+tree.
- Đầu tiên là, cả các file được sắp và các chỉ mục dựa-trên-cây đều cho phép tìm kiếm nhanh hơn. Việc thêm và xóa đối với các chỉ mục dựa-trên-cây thực hiện nhanh hơn nhiều so với các file được sắp. Mặc khác việc quét và các tìm kiếm miền cùng với nhiều phép so sánh sẽ thực hiện nhanh hơn nhiều so với các chỉ mục dựa-trên-cây. Vì thế, nếu chúng ta có dữ liệu chỉ-đọc (những dữ liệu không được thay đổi thường xuyên), thì chúng ta nên sử dụng file được sắp, ngược lại, nếu chúng ta có dữ liệu có khả năng được thay đổi thường xuyên, thì chúng ta nên sử dụng chỉ mục dựa-trên-cây.
- Khóa tìm kiếm kết hợp là khóa chứa một vài trường. Khóa tìm kiếm kết hợp có thể hỗ trợ một vùng rộng lớn cũng như tăng khả năng cho một kế hoạch chỉ-chỉ-số nào đó, nhưng nó cần chi phí cao hơn để duy trì và lưu trữ. Một kế hoạch chỉ-chỉ-số là một kế hoạch đánh giá truy vấn nơi chúng ta chỉ cần truy cập các chỉ mục để nhận được các bản ghi dữ liệu, mà không cần trực tiếp tới các bản ghi dữ liệu để trả về kết quả cho truy vấn này. Hiển nhiên, những kế hoạch chỉ-chỉ-số nhanh hơn nhiều những kế hoạch thông thường vì nó không yêu cầu đọc các bản ghi dữ liệu. Nếu chúng ta thường xuyên thực hiện các phép thao tác chỉ yêu cầu truy cập một trường, ví dụ lấy giá trị trung bình của một trường nào đó, thì việc tạo ra một khóa tìm kiếm trên trường này sẽ có lợi vì sau đó chúng ta có thể hoàn thành nó bằng một kế hoạch chỉ-chỉ-số.
Xem xét yêu cầu xoá sử dụng một điều kiện bằng. Với một trong năm cách tổ chức file, chi phí là bao nhiêu nếu không có bản ghi nào thoả mãn? Chi phí là bao nhiêu nếu điều kiện này không dựa trên khoá.
Dành cho độc giả
Những tổng kết chính nào bạn có thể đưa ra sau khi bàn luận về năm cách tổ chức file cơ bản trong Phần 8.4. Bạn sẽ lựa chọn cách tổ chức file nào nếu các thao tác thường xuyên nhất là:
- Tìm các bản ghi theo miền giá trị.
- Thực hiện thêm và quét, trong đó thứ tự của các bản ghi không quan trọng.
- Tìm một bản ghi nào đó theo giá trị của một trường cụ thể.
Tổng kết chính về năm cách tổ chức file là tất cả năm cách chúng ta nêu ra đều có những ưu và nhược điểm. Không có cách tổ chức file nào là hoàn toàn tốt trong tất cả các trường hợp. Việc lựa chọn các cấu trúc thích hợp cho một tập dữ liệu nào đó có thể có ảnh hưởng đáng kể đến việc thực hiện trên. Một file không được sắp xếp là tốt nhất trong trường hợp chúng ta chỉ mong muốn quét toàn bộ file. Một file chỉ mục băm là tốt nhất nếu như thao tác phổ biến nhất là phép chọn bằng. Một file được sắp là tốt nhất nếu chúng ta muốn thực hiện các truy vấn miền và dữ liệu là động. Một chỉ mục không phân cụm B+tree là hữu ích đối với các phép chọn trên các miền nhỏ, tốt nhất là chúng ta phân cụm trên khóa tìm kiếm khác để hỗ trợ một số truy vấn phổ biến.
- 1. Sử dụng những trường này như là khóa tìm kiếm, chúng ta sẽ chọn cách tổ chức file sắp xếp hoặc một B+tree phân cụm phụ thuộc vào việc dữ liệu là tĩnh hoặc không.
- 2. Heap file là lựa chọn tốt nhất trong trường hợp này.
- 3. Sử dụng trường này như là khóa tìm kiếm, sử dụng một file chỉ mục băm sẽ là lựa chọn tốt nhất.
Xem xét quan hệ sau:
Emp(eid: integer, sal: integer, age: real, did: integer)
Ở đây có một chỉ mục phân cụm trên eid và một chỉ mục không phân cụm trên age.
- Bạn sẽ sử dụng các chỉ mục này như thế nào để thiết lập một ràng buộc là: eid là một khoá?
- Cung cấp một ví dụ của lệnh cập nhật mà tốc độ của nó được cải thiện do có các chỉ mục này.
- Cung cấp một ví dụ của lệnh cập nhật mà tốc độ của nó bị chậm xuống do có các chỉ mục này.
- Bạn có thể cung cấp một ví dụ của lệnh cập nhật mà tốc độ của nó không tăng hay giảm do có các chỉ mục này.
Dành cho độc giả
Xem xét các quan hệ sau:
Emp(eid: integer, ename: varchar, sal: integer, age: integer, did: integer)
Dept(did: integer, budget: integer, floor: integer, mgr_eid: integer)
Lương (sal) nằm trong miền từ $10,000 tới $100,000, tuổi (age) nằm trong khoảng từ 20 to 80, mỗi phòng (Dept) có trung bình khoảng năm nhân viên, có 10 tầng, và ngân sách (budgets) của mỗi phòng khoảng từ $10,000 tới $1 million.
Với mỗi truy vấn sau, chỉ mục nào bạn sẽ lựa chọn để tăng tốc độ của truy vấn. Nếu hệ cơ sở dữ liệu của bạn không hỗ trợ các kế hoạch chỉ-chỉ-số (tức là, các bản ghi dữ liệu luôn được truy cập ngay cả khi thông tin có đầy đủ trong các cổng vào dữ liệu chỉ mục), câu trả lời của bạn sẽ thay đổi như thế nào? Giải thích tóm tắt.
- Truy vấn: In ra ename, age, và sal của tất cả nhân viên
- Chỉ mục băm phân cụm trên các trường (ename, age, sat) của Emp.
- Chỉ mục băm không phân cụm trên các trường (ename, age, sal) của Emp.
- Chỉ mục phân cụm B+ tree trên các trường (ename, age, sal) của Emp.
- Chỉ mục băm không phân cụm trên các trường (eid, did) của Emp.
- Không chỉ mục
- Truy vấn: Tìm các dids của các phòng ở trên tầng 10 và ngân sách ít hơn $15,000.
- Chỉ mục băm phân cụm trên trường floodcủa Dept.
- Chỉ mục băm không phân cụm trên trường floodcủa Dept.
- Chỉ mục phân cụm B+ tree trên các trường (floor, budget) của Dept.
- Chỉ mục phân cụm B+ tree trên các trường budget của Dept.
- Không chỉ mục
Câu trả lời với mỗi câu hỏi như sau:
1. Chúng ta nên tạo một chỉ mục băm không phân cụm trên các trường (ename, age, sal) của Emp (b) vì sau đó chúng ta có thể thực hiện quét chỉ-chỉ-số. Nếu hệ thống của chúng ta không bao gồm các kế hoạch chỉ-chỉ-số thì chúng ta không nên tạo chỉ mục cho truy vấn này (e). Vì truy vấn này yêu cầu chúng ta truy cập tất cả các bản ghi Emp, nên chỉ mục này không giúp chúng ta bất cứ điều gì, và vì thế chúng ta nên truy cập các bản ghi sử dụng thao tác quét file.
2. Chúng ta nên tạo một chỉ mục phân cụm ‘rậm rạp’ B+tree (c) trên các trường (floor, budget) của Dept, vì sau đó các bản ghi này sẽ được sắp xếp theo những trường này. Vì thế khi thực hiện truy vấn này, bản ghi đầu tiên có floor=10 phải được truy cập, sau đó các bản ghi khác có floor=10 có thể được đọc theo thứ tự của budget. Ghi nhớ rằng kế hoạch này- không phải là tốt nhất cho truy vấn này- không phải là một kế hoạch chỉ-chỉ-số (phải tìm kiếm dids).
BÀI TẬP LỚN
Trả lời những câu hỏi sau:
- Các công nghệ chỉ mục nào được Minibase hỗ trợ?
- Những Alternatives của các cổng vào dữ liệu được hỗ trợ?
- Những chỉ mục phân cụm được hỗ trợ?
TÀI LIỆU THAM KHẢO
Một vài cuốn sách bàn về các tổ chức file [29, 312, 442, 531, 648, 695, 775].
Những tài liệu tham khảo về các chỉ mục băm và B+tree được nêu trong Chương 10 và 11.