Giới Thiệu
Sự gia tăng của các mạng máy tính, bao gồm cả Internet và ‘intranets’ đã giúp cho người dùng có thể truy cập tới một số lượng lớn các nguồn dữ liệu. Điều này đã làm tăng truy cập tới cơ sở dữ liệu cũng như phát triển những ứng dụng thực tế có tầm ảnh hưởng lớn; dữ liệu và các dịch vụ được cung cấp trực tiếp cho các khách hàng. Ví dụ những ứng dụng thương mại điện tử như mua sách trực tiếp trên website Amazon.com, tham gia đấu giá trực tuyến tại website eBay, và trao đổi thông tin về sản phẩm giữa các công ty. Sự ra đời các chuẩn như XML nhằm biểu diễn nội dung của các tài liệu đã thúc đẩy sự phát triển của thương mại điện tử và các ứng dụng trực tuyến khác.
Trong khi các thế hệ đầu tiên của Internet là tập hợp của những file HTML, thì ngày nay hầu hết các Website đều lưu trữ một phần lớn (nếu không phải tất cả) các dữ liệu trong các hệ thống cơ sở dữ liệu. Họ dựa vào DBMSs để cung cấp một cách nhanh chóng và đáng tin cậy những yêu cầu của người dùng trên Internet. Điều này đặc biệt đúng đối với những website thương mại điện tử và những ứng dụng thương mại.
Trong chương này, chúng tôi trình bày tổng quan về những khái niệm chủ yếu để phát triển ứng dụng Internet. Chúng tôi bắt đầu với câu hỏi Internet làm việc như thế nào trong Phần 2. Chúng tôi giới thiệu HTML và XML, hai định dạng dữ liệu được sử dụng để biểu diễn dữ liệu trên Internet, trong Phần 3 và 4. Trong Phần 5, chúng tôi giới thiệu về kiến trúc ba lớp, một cách để tổ chức các ứng dụng Internet vào các lớp khác nhau theo chức năng của nó. Trong Phần 6 và 7, chúng tôi mô tả các lớp và trình bày chi tiết lớp giữa; DBMSs là lớp thứ ba. Chúng tôi kết luận chương này bằng việc thảo luận trường hợp nghiên cứu B & N trong Phần 8.
Những ví dụ xuất hiện trong chương này có thể tìm thấy trên website:
http://www.cs.wise.edu/~ dbbook
Những khái niệm về INTERNET
Internet đã nổi lên như một kết nối tổng hợp giữa các hệ thống phần mềm phân tán. Để hiểu được nó làm việc như thế nào, chúng ta bắt đầu bằng việc tìm hiểu hai vấn đề cơ bản: Các trang trên Internet được định vị thế nào, và các chương trình trên một trang kết nối với các trang khác như thế nào. Đầu tiên, chúng ta giới thiệu về Uniform Resource Identifiers (URI), một sơ đồ tên của các nguồn tài nguyên trên Internet trong Phần 2.1. Sau đó, chúng tôi nói về giao thức phổ dụng nhất cho phép truy cập đến các nguồn tài nguyên trên Web đó là HyperText Transfer Protocol (HTTP) trong Phần 2.2.
Uniform Resource Identifiers
Uniform Resource Identifiers (URIs) là những xâu ký tự giúp định danh duy nhất cho những nguồn tài nguyên trên Internet. Một nguồn tài nguyên là bất kỳ loại thông tin nào có thể được xác định bởi một URI, ví dụ các trang web, hình ảnh, những file có thể tải về, các dịch vụ có thể được điều khiển từ xa, hộp thư, vv… Loại tài nguyên phổ biến nhất là các tập tin tĩnh (tài liệu HTML), nhưng cũng có thể là các tệp tin HTML động được xuất ra từ cơ sở dữ liệu, hay là một bộ phim, hoặc dữ liệu đầu ra của một chương trình, vv…
Một URI có ba phần:
- (Tên của) giao thức được sử dụng để truy cập nguồn tài nguyên.
- Các máy vi tính lưu trữ các nguồn tài nguyên.
- Tên đường dẫn đến nguồn tài nguyên chính trên máy tính.
Xem xét một ví dụ URI: http://www.bookstore.com/index.html.
URI này có thể được giải thích như sau. Sử dụng giao thức HTTP (giải thích trong phần kế tiếp), để lấy tài liệu index.html nằm trên máy tính www.bookstore.com. Một ví dụ khác, đoạn HTML sau đây chỉ ra một URI là một địa chỉ email:
<a href="mailto:webmaster@bookstore.com">Email the webmaster.</a>
The Hypertext Transfer Protocol (HTTP)
Một giao thức là một bộ tiêu chuẩn định nghĩa cấu trúc của các thông điệp giao tiếp giữa hai bên kết nối để chúng có thể hiểu được nhau. The Hypertext Transfer Protocol (HTTP) là giao thức phổ biến nhất được sử dụng trên Internet. Đó là giao thức máy trạm-máy chủ (client-server), trong đó máy trạm (thường là một trình duyệt Web) gửi một yêu cầu tới một máy chủ HTTP, máy chủ này sẽ trả lại kết quả cho máy trạm. Khi một người dùng yêu cầu một trang web (ví dụ, nhấp chuột vào một siêu liên kết), trình duyệt gửi HTTP request messagestới máy chủ. Các máy chủ nhận được các yêu cầu và trả lời bằng HTTP response messages bao gồm các đối tượng. Điều quan trọng có thể nhận ra là HTTP được sử dụng để truyền tải tất cả các loại tài nguyên, không chỉ các tập tin, nhưng hầu hết các nguồn tài nguyên trên Internet ngày nay là các tệp tin tĩnh hoặc các scrip xuất ra từ máy chủ.
Một biến thể của giao thức HTTP gọi là giao thức Secure Sockets Layer (SSL) sử dụng mã hóa an toàn để trao đổi thông tin giữa máy trạm và máy chủ. Chúng ta hoãn thảo luận về SSL tới Phần 21.5.2 và trình bày những giao thức HTTP cơ bản trong chương này.
Ví dụ, xem xét những gì sẽ xảy ra nếu một người dùng nhấn vào liên kết sau: http://www.bookstore.com/index.html. Đầu tiên, chúng tôi giải thích cấu trúc của một HTTP request message và sau đó là cấu trúc của một HTTP response message.
HTTP Requests
Máy trạm (Web brower) thành lập một kết nối tới webserver và gửi một HTTP request message. Ví dụ sau đây chỉ ra một ví dụ về HTTP request message.
GET index.html HTTP/1.1
User-agent: Mozilla/4.0
Accept: text/html, image/gif, image/jpeg
HTTP Responses
Máy chủ sẽ trả về cho máy trạm một HTTP response message. Nó truy cập trang index.html, sử dụng nó để thu thập những HTTP response message, và gửi những message này tới máy trạm. Một ví dụ của HTTP response:
HTTP/1.1 200 OK
Date: Mon, 04 Mar 2002 12:00:00 GMT
Content-Length: 1024
Content-Type: text/html
Last-Modified: Mon, 22 Jun 1998 09:23:24 GMT
<HEAD>
<HTML>
<HEAD>
</HEAD>
<BODY>
<Hl>Barns and Nobble Internet Bookstore</Hl>
Our inventory:
<H3>Science</H3>
<B>The Character of Physical Law</B>
…
- 200 OK: Yêu cầu thành công và đối tượng nằm trong phần thân của response message.
- 400 Bad Request: Mã lỗi chỉ ra rằng yêu cầu không được máy chủ hoàn thành.
- 404 Not Found: Đối tượng yêu cầu không tồn tại trên máy chủ.
- 505 HTTP Version Not Supported: Phiên bản của giao thức HTTP mà máy trạm sử dụng không được máy chủ hỗ trợ (Nhớ lại rằng phiên bản của giao thức này được nằm trong yêu cầu của máy trạm).
Máy trạm (trình duyệt Web) nhận được response message, đưa ra các tệp tin HTML, phân tích, và hiển thị nó. Trong khi làm điều này, nó có thể tìm thấy thêm những URIs trong các file, và sau đó nó sử dụng giao thức HTTP để lấy những tài nguyên này, mỗi một tài nguyên thiết lập một kết nối mới.
Một vấn đề quan trọng là giao thức HTTP là một giao thức ‘không lưu trạng thái’ (stateless protocol). Tất cả các thông báo - từ máy trạm tới HTTP server và ngược lại là ‘self-contained’, và kết nối thành lập (cùng với một thông báo yêu cầu) được duy trì cho đến khi response message được gửi. Các giao thức cung cấp không có cơ chế để tự động 'nhớ' những tương tác trước đó giữa máy trạm và máy chủ.
Tính chất không lưu trạng thái của giao thức HTTP có ảnh hưởng lớn đến việc các ứng dụng Internet được viết như thế nào. Xem xét một người dùng tương tác với ứng dụng Bookstore của chúng ta. Giả định rằng Bookstore cho phép người sử dụng đăng nhập vào website và sau đó thực hiện một số thao tác, chẳng hạn như đặt một số quyển sách hoặc thay đổi địa chỉ của họ, mà không cần đăng nhập lại (cho đến khi hết hạn hoặc người sử dụng đăng xuất). Làm thế nào để chúng ta theo dõi được một người dùng đã đăng nhập hay chưa? Vì HTTP có tính chất ‘không lưu trạng thái’, nên chúng ta không thể chuyển sang một trạng thái khác (ví dụ là trạng thái 'đã đăng nhập'). Thay vào đó, với mọi yêu cầu mà người dùng gửi tới máy chủ, chúng ta phải mã hoá mọi thông tin trạng thái nào ứng dụng yêu cầu, ví dụ như tình trạng đăng nhập của người dùng. Thêm nữa, chương trình ứng dụng phía máy chủ phải duy trì thông tin trạng thái này và đáp ứng khi có yêu cầu. Vấn đề này được trình bày trong Phần 5.
Ghi nhớ rằng sự ‘không lưu trạng thái’ của HTTP được thiết kế dựa trên yêu cầu làm thế nào để cân bằng được giữa sự dễ dàng thực hiện của giao thức HTTP và sự dễ dàng thực hiện của các nhà phát triển ứng dụng. Những người thiết kế ra HTTP lựa chọn cách thức là giữ cho bản thân giao thức này đơn giản, và nhường lại những chức năng yêu cầu đến các đối tượng cho các lớp ứng dụng nằm trên giao thức HTTP.
Văn bản HTML
Trong phần này và phần tiếp theo, chúng tôi tập trung giới thiệu về HTML và XML. Trong Phần 6, chúng tôi đề cập đến cách thức các ứng dụng sử dụng HTML và XML để tạo ra các form tiếp nhận những yêu cầu của người dùng, kết nối tới một máy chủ HTML, và chuyển những kết quả do lớp quản lý dữ liệu tạo ra vào một trong những định dạng này.
HTML là một ngôn ngữ đơn giản được sử dụng để biểu diễn dữ liệu. Các lệnh trong ngôn ngữ này được gọi là thẻ, nó thường có thẻ bắt đầu và thẻ kết thúc có dạng <TAG> và </TAG>. Ví dụ, xem xét đoạn HTML trong Hình 1. Nó mô tả một trang Web chỉ ra danh sách các quyển sách. Văn bản này nằm gọn trong thẻ <HTML> và </HTML>, chứng tỏ nó là một văn bản HTML. Phần còn lại của văn bản - nằm trong thẻ <BODY> và </BODY> chứa thông tin về ba quyển sách. Dữ liệu về mỗi quyển được biểu diễn như là một danh sách không được sắp xếp (UL) trong đó toàn bộ các thực thể được đánh dấu bằng thẻ <LI>. HTML định nghĩa một tập các thẻ đúng như là ý nghĩa của nó. Ví dụ, HTML định nghĩa thẻ <TITLE> với mục đích ghi tiêu đề của văn bản. Một ví dụ khác, thẻ <UL> biểu diễn một danh sách không được sắp xếp. Audio, video, thậm chí là các chương trình Java (được viết trong Java, một ngôn ngữ bậc cao) có thể nằm trong các văn bản HTML. Khi một người dùng truy cập một văn bản sử dụng một trình duyệt phù hợp, những hình ảnh trong văn bản được hiển thị, các file audio và video được bật, và những chương trình nhúng được thực hiện trên máy của người dùng. Sự dễ dàng tạo ra những văn bản HTML và dễ dàng truy cập sử dụng trình duyệt Internet là động lực cho sự phát triển mạnh mẽ của các trang Web.

Văn bản XML
Trong phần này, chúng tôi giới thiệu XML như là một định dạng văn bàn, và xem xét cách thức các ứng dụng có thể sử dụng XML. Việc quản lý các văn bản XML trong một DBMS đặt ra những thách thức mới; chúng ta sẽ bàn đến khía cạnh này của XML trong Chương 27.
Trong khi HTML có thể được sử dụng để đánh dấu các văn bản tuỳ vào mục đích hiển thị, nó không phù hợp để biểu diễn các cấu trúc của một nội dung dùng chung cho nhiều ứng dụng. Ví dụ, chúng ta có thể gửi một văn bản HTML chỉ ra trong Hình 1 tới một ứng dụng khác để hiển thị nó, như ứng dụng thứ hai có thể không phân biệt được phần tên đầu (first name) và phần cuối (last name) của các tác giả. (Ứng dụng này có thể cố gắng lấy những thông tin bằng cách tìm những đoạn văn bản nằm bên trong các thẻ, nhưng điều này làm hỏng mục đích sử dụng thẻ để biểu diễn cấu trúc của văn bản). Vì thế, HTML không thích hợp với những văn bản phức tạp.
Extensible Markup Language (XML) là một ngôn ngữ đánh dấu được phát triển để khắc phục những tồn tại của ngôn ngữ HTML. Ngược lại với một tập các thẻ cố định được xác định trong ngôn ngữ HTML, XML cho phép người sử dụng định nghĩa mới một tập các thẻ có thể được sử dụng để cấu trúc bất kỳ loại dữ liệu hay văn bản nào người dùng mong muốn truyền tải. XML có khả năng làm cho các hệ thống cơ sở dữ liệu tích hợp chặt chẽ với những ứng dụng Web hơn bao giờ hết.
XML được xây dựng dựa trên hai công nghệ, SGML và HTML. Standard Generalized Markup Language (SGML) là siêu ngôn ngữ cho phép định nghĩa dữ liệu và trao đổi văn bản như HTML. Chuẩn SGML được công bố vào năm 1998, và rất nhiều tổ chức quản lý nhiều những văn bản phức tạp đã sử dụng nó. Tuy nhiên, SGML phức tạp và yêu cầu các chương trình tinh vi mới khai thác được những khả năng của nó. XML đã được phát triển để có được những tính năng mạnh mẽ của SGML nhưng vẫn khá đơn giản. XML, giống như SGML, cho phép định nghĩa mới những ngôn ngữ đánh dấu văn bản.
Mục đích thiết kế của XML: XML đã được phát triển từ đầu những năm 1996. Mục đích của XML bao gồm:
1. XML nên tương thích với SGML.
2. Dễ dàng viết các chương trình xử lý những văn bản XML.
3. Thiết kế của XML nên có khuôn mẫu và xúc tích.
Giới thiệu XML
Chúng ta sử dụng tài liệu XML trên Hình 2 làm ví dụ.
- Các nguyên tử (element): Các nguyên tử, hay còn gọi là các thẻ, là những khối chính trong một văn bản XML. Bắt đầu của nội dung một nguyên tử ELM là được đánh dấu bằng <ELM>, nó được gọi là thẻ bắt đầu, và kết thúc bằng thẻ </ELM>, gọi là thẻ kết thúc. Trong văn bản ví dụ của chúng ta, nguyên tử BOOKLIST đóng tất cả thông tin trong văn bản này.
Thẻ BOOK phân chia dữ liệu thành từng quyển sách đơn. Những thẻ XML phải được lồng nhau hợp lý. Những thẻ bắt đầu xuất hiện bên trong nội dung của các thẻ khác phải có thẻ kết thúc tương ứng. Ví dụ, xem xét đoạn XML sau:
<BOOK>
<AUTHOR>
<FIRSTNAME>Richard</FIRSTNAME>
<LASTNAME>Feyninan</LASTNAME>
</AUTHOR>
</BOOK>
Thẻ AUTHOR nằm trọn vẹn bên trong thẻ BOOK, và cả hai thẻ LASTNAME và FIRSTNAME nằm trọn vẹn bên trong thẻ AUTHOR.
- Các thuộc tính: Mỗi thẻ có thể có những thuộc tính biểu diễn để cung cấp thêm thông tin. Các giá trị của thuộc tính được thiết đặt ở bên trong thẻ. Chúng ta có thể thiết đặt giá trị cho thuộc tính att thông qua biểu thức sau: <ELM att= “value”>. Tất cả các giá trị thuộc tính phải được đặt bên trong dấu ngoặc. Trong Hình 2, nguyên tử BOOK có hai thuộc tính. Thuộc tính GENRE(loại) xác định thể loại của cuốn sách (là sách khoa học hay sách viễn tưởng) và thuộc tính FORMAT chỉ quyển sách được đóng có bìa cứng hay bìa mềm.
- Tham chiếu thực thể: Các tham chiếu thực thể là đường tắt tới các phần khác nhau của văn bản hoặc nội dung của các tệp khác, và chúng ta gọi cách sử dụng một thực thể nào đó trong XML là một tham chiếu thực thể. Bất cứ khi nào một tham chiếu thực thể xuất hiện trong một văn bản, nó sẽ được thay thế bằng nội dung của nó. Các tham chiếu thực thể được bắt đầu bằng dấu ‘&’ và kết thúc bằng dấu ‘;’. Năm thực thể được định nghĩa trước trong XML sẽ thay thế cho những ký tự đặc biệt trong XML. Ví dụ, ký tự < dùng để đánh dấu vị trí bắt đầu của một lệnh XML phải được biểu diễn bằng thực thể lt. Bốn ký tự khác là &, >, ”, và ’ được biểu diễn thông qua các thực thể amp, gt, quot và apos. Ví dụ, ký hiệu ‘1<5’ phải được mã hoá trong XML như sau: ' l < 5 '. Chúng ta cũng có thể sử dụng các thực thể để thêm các ký tự Unicode vào trong văn bản. Unicode là một chuẩn để biểu diễn dữ liệu, tương tự như ASCII.
- Chú thích: Chúng ta có thể thêm chú thích tại vị trí bất kỳ trong văn bản XML. Chú thích bắt đầu bằng <!- và kết thúc bằng ->. Chú thích có thể chứa những ký tự bất kỳ, trừ xâu ký tự --.
- Những khai báo kiểu văn bản (Document Type Declarations-DTDs): Trong XML, chúng ta có thể định nghĩa ngôn ngữ đánh dấu của chúng ta. Một DTD là một tập các quy tắc cho phép chúng ta xác định tập các thẻ, thuộc tính và các thực thể. Vì thế, một DTD sẽ chỉ rõ những thẻ nào được phép, thứ tự xuất hiện của chúng, và chúng có thể được lồng nhau như thế nào. Chúng ta bàn chi tiết về DTDs trong phần tiếp theo.
Chúng ta gọi một văn bản XML là định-dạng-tốt nếu nó tuân theo những hướng dẫn sau:
- Văn bản bắt đầu bằng một khai báo XML. Một ví dụ của khai báo XML ở dòng đầu tiên của văn bản chỉ ra trong Hình 2.
- Một thẻ gốc chứa tất cả các thẻ khác. Trong ví dụ của chúng ta, thẻ gốc là thẻ BOOKLIST.
- Tất cả các thẻ phải được lồng nhau. Yêu cầu này có nghĩa là các thẻ bắt đầu và kết thúc phải xuất hiện cùng nhau.

XML DTDs
Một DTD là một tập các quy tắc cho phép chúng ta tự xác định tập các thẻ, thuộc tính, và các thực thể. Một DTD chỉ ra những thẻ nào chúng ta có thể sử dụng và các ràng buộc trên những thẻ này, ví dụ, các thẻ có thể được lồng nhau như thế nào và các thẻ có thể xuất hiện ở đâu trong văn bản. Trong phần còn lại của mục này chúng ta sẽ sử dụng ví dụ DTD trong Hình 3 để minh hoạ cách thức cấu trúc một các DTD.

Một DTD được đặt trong <!DOCTYPE name [DTDdeclaration] >, trong đó name là tên của của thẻ ngoài cùng, và DTDdeclaration là các quy tắc của DTD đó. DTD này bắt đầu bằng thẻ ngoài cùng - thẻ gốc- trong ví dụ của chúng ta là thẻ BOOKLIST. Xem xét luật tiếp theo:
<!ELEMENT BOOKLIST (BOOK)*>
Luật này nói với chúng ta rằng thẻ BOOKLIST chứa 0 hoặc nhiều thẻ BOOK. Ký hiệu * đằng sau BOOK xác định có bao nhiêu thẻ BOOK có thể xuất hiện ở bên trong thẻ BOOKLIST. Dấu * quy định có 0 hoặc nhiều sự kiện, ký hiệu + quy định có 1 hoặc nhiều sự kiện, và ký hiệu ? quy định 0 hoặc 1 sự kiện. Ví dụ, nếu chúng ta muốn đảm bảo rằng một BOOKLIST có ít nhất một cuốn sách, chúng ta có thể thay đổi quy tắc này như sau:
<!ELEMENT BOOKLIST (BOOK)+>Hãy cùng chúng tôi xem xét luật tiếp theo:
<!ELEMENT BOOK (AUTHOR,TITLE,PUBLISHED?)>Luật này chỉ ra rằng một thẻ BOOK sẽ chứa một thẻ AUTHOR, một thẻ TITLE, và một thẻ lựa chọn PUBLISHED (có thể có hoặc không). Lưu ý việc sử dụng dấu ? để chỉ ra rằng thông tin là không bắt buộc, có 0 hoặc một sự kiện của thẻ này.
Hãy cùng chúng tôi xem xét luật tiếp theo:
<! ELEMENT LASTNAME (#PCDATA)>Từ trước đến giờ chúng ta đã chỉ đề cập đến những thẻ chứa những thẻ khác. Quy tắc này chỉ ra rằng LASTNAME là một thẻ không có chứa thẻ khác bên trong, nhưng nó chứa tập ký tự. Các thẻ chỉ chứa những thẻ khác được nói là có nội dung thẻ, ngược lại những thẻ chứa #PCDATA được nói là có nội dung trộn. Thường thì một khai báo thẻ có cấu trúc như sau:
<! ELEMENT (contentType)>Năm kiểu nội dung cho phép là:
- Những thẻ khác.
- Ký hiệu #PCDATA.
- Ký hiệu EMPTY, chứng tỏ rằng thẻ này không có nội dung. Các thẻ không có nội dung không yêu cầu có thẻ đóng.
- Ký hiệu ANY, chứng tỏ rằng bất cứ nội dung nào đều được phép. Điều này nên tránh vì nó sẽ không thể làm những kiểm tra với cấu trúc văn bản ở bên trong thẻ này.
- Một biểu thức thông thường được xây dựng từ bốn lựa chọn tiền tố. Nó có thể như sau:
- expl, exp2, exp3: Một danh sách các biểu thức thông thường.
- exp*: Một biểu thức có thể lựa chọn (0 hoặc nhiều sự kiện).
- exp?: Một biểu thức có thể lựa chọn (0 hoặc một sự kiện).
- exp+: Một biểu thức bắt buộc (1 hoặc nhiều sự kiện).
- expl | exp2: expl hoặc exp2
Các thuộc tính của thẻ được khai báo bên ngoài thẻ. Ví dụ, xem xét cách khai báo thuộc tính trong hình 3:
<!ATTLIST BOOK GENRE (Science|Fiction) #REQUIRED>>Đoạn XML DTD này khai báo thuộc tính GENRE là thuộc tính của thẻ BOOK. Thuộc tính này có hai giá trị: Science và Fiction. Mỗi một thẻ BOOK phải được biểu diễn trong thẻ bắt đầu của nó bằng một thuộc tính GENRE vì thuộc tính này được yêu cầu do đã xác định #REQUIRED. Hãy cùng chúng tôi xem cấu trúc thông thường của một khai báo thuộc tính DTD:
<!ATTLIST elementName (attName attType default)+>Từ khoá ATTLIST đánh dấu việc khai báo thuộc tính. Xâu elementName là tên của thẻ có thuộc tính được định nghĩa theo sau. Phần đằng sau là khai báo của một hoặc nhiều thuộc tính. Mỗi thuộc tính có một tên (attName), và kiểu (attType). XML định nghĩa một số kiểu cho mỗi thuộc tính. Chúng ta chỉ bàn đến các kiểu xâu ký tự và các kiểu dữ liệu đếm được ở đây. Một thuộc tính kiểu xâu ký tự có thể mang giá trị của bất kỳ xâu ký tự nào. Chúng ta có thể khai báo một thuộc tính với kiểu dữ liệu là CDATA. Ví dụ, chúng ta khai báo thuộc tính kiểu xâu ký tự của thẻ BOOK như sau:
<! ATTLIST BOOK edition CDATA "1">Nếu một thuộc tính có kiểu dữ liệu đếm được, chúng ta liệt kê tất cả các giá trị của nó có thể nhận trong phần khai báo thuộc tính đó. Trong ví dụ của chúng ta, thuộc tính GENRE là kiểu đếm được; nó có thể nhận hai giá trị là ‘Science’ và ‘Fiction’.
Thành phần cuối cùng của khai báo thuộc tính là giá trị mặc định của nó. DTD trong Hình 3 chỉ ra hai xác định mặc định khác nhau: #REQUIRED và xâu ‘Paperback’. Xác định mặc định #REQUIRED chỉ ra rằng thuộc tính này được yêu cầu và bất cứ khi nào thẻ liên quan đến nó xuất hiện trong XML thì giá trị của thuộc tính cũng phải được xác định. Phần mặc định là xâu ký tự ‘Paperback’ chứng tỏ rằng thuộc tính này không yêu cầu bắt buộc phải có; khi thẻ xuất hiện không có giá trị của thuộc tính này thì nó sẽ mang giá trị mặc định là ‘Paperback’. Ví dụ, chúng ta có thể xác định giá trị mặc định của thuộc tính GENRE là ‘Science’ như sau:
<!ATTLIST BOOK GENRE (Science|Fiction) "Science">Trong ví dụ về Bookstore của chúng ta, tài liệu XML có một tham chiếu tới DTD được chỉ ra trong Hình 4.

Domain-Specific DTDs
Gần đây, DTDs đã được phát triển cho một số lĩnh vực đặc biệt- phủ lên một vùng rộng lớn của thương mại, kỹ thuật, tài chính, công nghệ và khoa học...- và rất nhiều những điều thú vị về XML đã được bắt nguồn từ một niềm tin rằng có nhiều hơn và nhiều hơn nữa những DTDs chuẩn sẽ được phát triển. DTDs đã được chuẩn hoá sẽ cho phép trao đổi dữ liệu giữa những nguồn dữ liệu không đồng nhất.
Ngay cả trong môi trường nơi mà tất cả các dữ liệu XML là hợp lệ, nó cũng không thể tích hợp một số tài liệu XML một cách minh bạch bằng cách đối sánh các thẻ trong các DTDs khác nhau. Nếu cả hai văn bản sử dụng một chuẩn DTD thì chúng ta sẽ tránh được vấn đề này. Sự phát triển của các chuẩn DTDs bị ảnh hưởng bởi các yếu tố xã hội nhiều hơn là khó khăn trong việc nghiên cứu, vì các đối tượng tham gia trong lĩnh vực này cần phải có ‘tiếng nói chung’ - sự hợp tác với nhau.
Ví dụ, Ngôn ngữ đánh dấu toán học (Mathematical markup language-MathML) đã được phát triển để mã hoá những ký hiệu toán học trên Web. Có hai loại thẻ MathML. Các thẻ trình diễn biểu diễn cấu trúc của một văn bản; ví dụ thẻ mrow xác định một xâu ký tự sẽ được trình bày theo chiều ngang, thẻ msup xác định ký tự cơ sở và số mũ của nó. Các thẻ nội dung biểu diễn các khái niệm toán học. Ví dụ thẻ plus sẽ xác định một phép tính cộng.
MathML cho phép chúng ta mã hoá các đối tượng toán học bằng cả hai loại vì yêu cầu của người sử dụng với các đối tượng có thể khác nhau. Các thẻ nội dung mã hoá chính xác các đối tượng mà không có sự nhập nhằng, và có thể được sử dụng trong các ứng dụng như các hệ thống tính toán số học.
Ví dụ, xem xét công thức đơn giản sau:
x2-4x-32=0
Sử dụng các thẻ trình diễn, công thức được biểu diễn như sau:
<mrow>
<mrow> <msup><mi>x</mi><mn>2</mn></msup>
<mo>-</mo>
<mrow><mn>4</mn>
<mo>&invisibletimes;</mo>
<mi>x</mi>
</mrow>
<mo>-</mo><mn>32</mn>
</mrow><mo>=</mo><mn>0</mn>
</mrow>
Sử dụng các thẻ nội dung, công thức được biểu diễn như sau:
<reln><eq/>
<apply>
<minus/>
<apply> <power/> <ci>x</ci> <cn>2</cn> </apply>
<apply> <times/> <cn>4</cn> <ci>x</ci> </apply>
<cn>32</cn>
</apply> <cn>0</cn>
</reln>
Nhớ rằng sẽ có sự bổ sung sức mạnh khi chúng ta sử dụng MathML thay vì mã hoá công thức bằng HTML. Cách thường dùng khi biểu diễn các đối tượng toán học trong HTML là phải sử dụng đến các ảnh của các công thức, ví dụ:
<IMG SRC="images/equation.gif" ALT=" x**2 - 4x - 32 = 10 " >Công thức này được mã hoá bên trong thẻ IMG cùng với việc thêm phần định dạng hiển thị bằng việc sử dụng thẻ ALT. Sử dụng việc mã hoá này cho một đối tượng toán học dẫn đến những vấn đề sau. Đầu tiên, ảnh phải được điều chỉnh kích cỡ để phù hợp với kiểu chữ hiện tại, nếu không thì ảnh sẽ quá nhỏ hoặc quá lớn. Thứ hai, trên các hệ thống có các màu nền khác nhau, ảnh sẽ không phù hợp với các màu nền tương ứng, dẫn đến khó khăn trong hiển thị và in ấn,
Kiến trúc ba-lớp của ứng dụng
Trong phần này, chúng ta bàn đế kiến trúc của các ứng dụng trên Internet chuyên sâu về dữ liệu. Các ứng dụng này có thể được hiểu dưới dạng ba thành phần chức năng khác nhau: quản lý dữ liệu, chương trình ứng dụng và trình diễn. Thành phần quản lý dữ liệu thường sử dụng một DBMS để lưu trữ dữ liệu, như hai thành phần còn lại là chương trình ứng dụng và trình diễn giải quyết nhiều vấn đề hơn là chỉ những chức năng mà DBMS cung cấp.
Chúng ta bắt đầu bằng việc giới thiệu ngắn gọn về lịch sử của các kiến trúc ứng dụng chuyên sâu cơ sở dữ liệu, và giới thiệu các kiến trúc một-lớp và kiến trúc máy trạm-máy chủ (client-server) trong Phần 7.5.1. Chúng ta giải thích kiến trúc ba-lớp chi tiết trong Phần 7.5.2, và những ưu điểm của nó trong Phần 7.5.3.
Kiến trúc một lớp và máy trạm-máy chủ
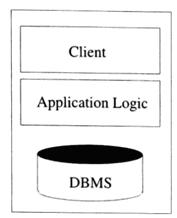
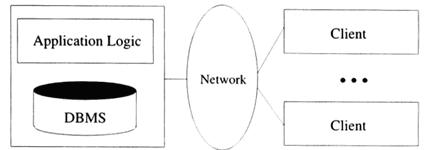
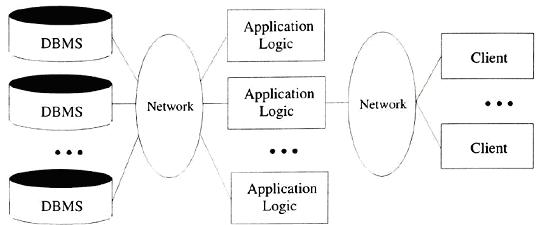
Kiến trúc hai-lớp còn được gọi là kiến trúc máy trạm-máy chủ, gồm một máy trạm và một máy chủ, được giao tiếp với nhau thông qua một giao thức được định-nghĩa-tốt. Sự phân công chức năng thực hiện giữa hai máy tính này có thể được điều chỉnh thay đổi. Trong kiến trúc máy trạm-máy chủ truyền thống, các máy trạm chỉ làm nhiệm vụ là một giao diện đồ hoạ của người sử dụng, và máy chủ thực hiện cả hai chức năng quản lý dữ liệu và tính toán logic; vì thế các máy trạm thường được gọi là máy-trạm-yếu, và kiến trúc này được minh hoạ trong Hình 6.
Một sự phân chia khác là máy trạm thực hiện cả hai chức năng: giao diện người dùng và tính toán logic, hoặc các máy trạm thực hiện chức năng là giao diện người dùng và một phần của tính toán logic, phần còn lại thực hiện ở phía máy chủ; máy trạm trong trường hợp này thường được gọi là máy-trạm-mạnh, và kiến trúc này được minh hoạ trong Hình 7.
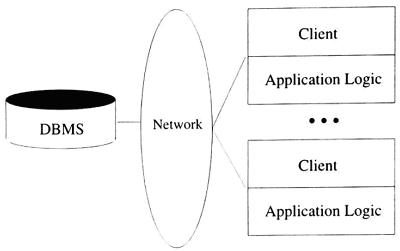
Mười năm trước đây, các công cụ phục vụ mô hình máy trạm-máy chủ đã được phát triển như Microsoft Visual Basic và Sybase Powerbuilder. Những công cụ này cho phép phát triển nhanh chóng các phần mềm chạy trên kiến trúc máy trạm-máy chủ, góp phần vào sự thành công của mô hình này.
Mô hình máy-trạm-mạnh có một số nhược điểm so với mô hình máy-trạm-yếu. Đầu tiên, nó không có một vùng tập trung để cập nhật và bảo trì các tính toán logic khi cần thiết, vì mã nguồn ứng dụng chạy trên nhiều máy trạm khác nhau. Thứ hai, có một lượng lớn các ‘kiểm tra đúng đắn’ giữa máy trạm và máy chủ. Ví dụ, DBMS của một ngân hàng phải kiểm tra việc thực thi ứng dụng ở máy ATM để đảm bảo cơ sở dữ liệu có sự nhất quán.(Một cách để giải quyết vấn đề này là sử dụng stored procedures. Chúng ta sẽ bàn đến stored procedures chi tiết trong Phần 5).
Nhược điểm thứ ba của kiến trúc máy-trạm-mạnh là nó không thể đồng thời phục vụ được quá nhiều yêu cầu của người dùng đồng thời, cụ thể là không nhiều hơn vài trăm máy trạm. Ứng dụng ở phía máy trạm gửi các truy vấn SQL tới máy chủ và máy chủ trả về kết quả cho máy trạm. Một lượng lớn kết quả truy vấn phải được trao đổi giữa máy trạm và máy chủ. (stored procedures sẽ giúp làm giảm lượng dữ liệu phải trao đổi này). Thứ tư, các hệ thống máy-trạm-mạnh không đáp ứng được khi các ứng dụng cần truy cập đến nhiều hệ thống cơ sở dữ liệu. Giả sử, có x hệ thống cơ sở dữ liệu khác nhau được truy cập bởi y máy trạm, thì sẽ có x*y kết nối khác nhau được mở, rõ ràng đây không là giải pháp tốt.

Kiến trúc ba-lớp
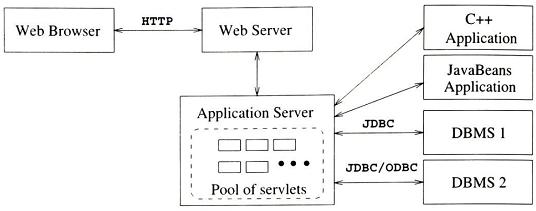
Kiến trúc hai-lớp-máy-trạm-yếu đã có sự phân chia trong việc trình bày dữ liệu từ các phần khác nhau của ứng dụng. Kiến trúc ba-lớp đã tiến thêm một bước, nó đã tách rời phần logic ứng dụng với phần quản lý dữ liệu.
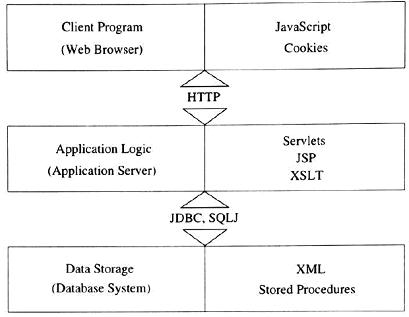
Lớp giữa: Logic ứng dụng thực hiện ở đây. Chương trình nguồn của nó thường được viết bằng C ++ hoặc Java.
Lớp quản lý dữ liệu: Các ứng dụng Web chuyên sâu về dữ liệu bao gồm các DBMS, là nội dung của cuốn sách này.
Hình 8 chỉ ra một kiến trúc ba-lớp cơ bản. Các công nghệ khác nhau đã được phát triển nhằm phân bố ba lớp của ứng dụng để có thể phù hợp với nhiều nền tảng phần cứng khác nhau. Hình 9 chỉ ra những công nghệ liên quan đến từng lớp.
Tổng quan về lớp trình diễn
Ở lớp trình diễn, chúng ta cần cung cấp các form để người dùng có thể đưa vào các yêu cầu, và hiển thị thông báo phản hồi mà lớp giữa đưa ra. HTML đã trình bày trong Phần 3 là ngôn ngữ biểu diễn dữ liệu chính. Một điều quan trọng là lớp này được mã hoá để dễ dàng tương thích với các thiết bị hiển thị và các định dạng khác nhau: ví dụ các máy tính bàn thông thường khác với các thiết bị cầm tay, khác với điện thoại di động. Sự tương thích này có thể đạt được ở lớp giữa bằng cách đưa ra những trang khác nhau cho những kiểu máy tính khác nhau, hoặc ở máy trạm thông qua các style sheets xác định cách thức dữ liệu được trình bày. Ở trường hợp cuối cùng, lớp giữa có nhiệm vụ đưa ra dữ liệu phù hợp đáp ứng yêu cầu của người dùng, trong khi đó lớp trình diễn quyết định cách thức hiển thị những thông tin này.
Chúng ta tìn hiển các công nghệ của lớp trình diễn, bao gồm các style sheets trong Phần 6.
Tổng quan về lớp giữa
Lớp giữa thực thi phần mã nguồn của chương trình ứng dụng. Nó điều khiển những dữ liệu nào cần phải đưa vào trước khi một hành động nào đó được thực hiện, xác định thứ tự các hành động được thực hiện, điều khiển việc truy cập tới lớp cơ sở dữ liệu, và thường linh động thu thập các trang HTML phù hợp từ kết quả truy vấn cơ sở dữ liệu.
Mã nguồn của lớp giữa có khả năng hỗ trợ tất cả các role khác nhau của ứng dụng. Ví dụ, trong một cửa hàng Internet, chúng ta muốn khách hàng có thể xem được danh mục hàng và thực hiện việc đặt hàng, người quản trị có thể kiểm tra hàng hoá trong kho, và có thể phân tích dữ liệu để trả lời được truy vấn về lịch sử của việc đặt hàng. Một role có thể yêu cầu nhiều công việc phức tạp.
Ví dụ, xem xét một khách hàng muốn mua một sản phẩm. Trước khi việc bán được thực hiện, khách hàng này phải đi qua một loạt các bước: Cô ấy phải thêm các sản phàm vào giỏ hàng, cung cấp địa chỉ giao hàng và mã số thẻ thanh toán (trừ khi cô ấy có một tài khoản trên trang Web này), và phải xác nhận lại hoá đơn bán hàng sau khi đã được cộng thêm giá vận chuyển và thuế sản phẩm. Việc điều khiển thứ tự thực hiện các bước và ghi nhớ những bước nào đã được thực hiện sẽ được làm ở lớp giữa. Việc đưa ra dữ liệu đáp ứng các bước trên cần đến thao tác truy cập cơ sở dữ liệu, nhưng không phải lúc nào cũng như vậy (ví dụ, một giỏ hàng không được lưu trữ trong cơ sở dữ liệu cho đến khi việc bán được hoàn tất).
Chúng ta nghiên cứu chi tiết về lớp giữa trong Phần 7.
Những ưu điểm của kiến trúc ba-lớp
Kiến trúc ba-lớp có những ưu điểm sau:
- Những hệ thống không đồng nhất: Các ứng dụng có thể tận dụng sức mạnh của các phần mềm và nền tảng hệ thống của các lớp khác nhau. Chương trình tại các lớp khác nhau dễ được sửa đổi hoặc thay thế mà không ảnh hưởng tới các lớp khác.
- Các máy trạm yếu: Các máy trạm chỉ cần có năng lực tính toán vừa phải phục vụ cho lớp trình diễn. Các máy trạm chỉ cần là các trình duyệt Web.
- Truy cập dữ liệu: Trong nhiều ứng dụng, dữ liệu phải được truy cập từ nhiều nguồn khác nhau. Điều này có thể được thực hiện dễ dàng ở lớp giữa, nơi chúng ta có thể quản lý tập trung các kết nối tới tất cả các hệ thống cơ sở dữ liệu liên quan.
- Phục vụ nhiều máy trạm: Tất cả các truy cập của các máy trạm tới hệ thống đều thông qua lớp giữa. Lớp giữa có thể chia sẻ các kết nối tới cơ sở dữ liệu cho các máy trạm, và nếu lớp giữa trở thành ‘cổ chai’, chúng ta có thể dàn xếp cho một số máy chỉ thực hiện chức năng của lớp giữa; các máy trạm có thể kết tới tới bất kỳ máy chủ nào nếu phần thiết kế logic được thực hiện hợp lý. Điều này được minh hoạ trong Hình 10, trong đó chỉ ra cách thức lớp giữa truy cập tới nhiều nguồn dữ liệu khác nhau. Tất nhiên, chúng ta sẽ nhờ DBMS cho mỗi truy cập nguồn dữ liệu (và ở đây có thể bao gồm thêm phần xử lý song song và sao lưu dữ liệu, chúng ta sẽ bàn tới trong Chương 22).
- Những lợi ích trong phát triển phần mềm: Bằng việc chia ứng dụng thành các phần như biểu diễn địa chỉ, truy cập dữ liệu, và thực hiện logic của chương trình, chúng ta đạt được nhiều điểm lợi. Phần thực hiện logic của chương trình được tập trung giải quyết, và vì thế nó dễ dàng được bảo trì, thay đổi và gỡ lỗi. Sự ảnh hưởng lẫn nhau giữa các lớp được định nghĩa tốt thông qua chuẩn APIs. Vì thế, mỗi lớp ứng dụng có thể được xây dựng từ các thành phần được phát triển, gỡ lỗi, và kiểm tra độc lập .
Lớp trình diễn
Trong phần này, chúng ta trình bày các công nghệ phía máy trạm trong kiến trúc ba-lớp. Chúng ta bàn về các form HTML trong Phần 6.1. Trong Phần 6.2, chúng ta giới thiệu về JavaScrip. Chúng ta tổng kết những công nghệ phía máy trạm bằng việc trình bày về Style sheets trong Phần 6.3. Style sheets là ngôn ngữ cho phép chúng ta biểu diễn cùng một trang Web với các định dạng khác nhau cho các máy trạm; ví dụ, định dạng dữ liệu cho các trình duyệt Web khác với cho điện thoại di động, hoặc trình duyệt Web của Netscape khác với của Microsofts Internet Explorer.
Các Form HTML
Form HTMLs là một cách thường dùng để giao tiếp dữ liệu giữa lớp máy trạm và lớp giữa. Định dạng chung của một form như sau:
<FORM ACTION="page.jsp" METHOD="GET" NAME="LoginForm">
...
</FORM>
Một văn bản HTML có thể chứa nhiều hơn một form. Bên trong một Form HTML có thể có bất kỳ một thẻ HTML nào, ngoại trừ một FORM khác. Thẻ FORM có ba thuộc tính quan trọng sau:
- ACTION: Xác định URI của trang mà nội dung của form sẽ gửi tới trang này; nếu thuộc tính ACTION không xuất hiện, thì URI của trang hiện tại được sử dụng. Trong ví dụ trên, đầu vào của form sẽ được gửi tới trang có tên là page.jsp. (Chúng ta sẽ giải thích các phương pháp đọc dữ liệu form tại lớp giữa trong Phần 7.)
- METHOD: Phương thức HTTP/1.0 được sử dụng để gửi đi các dữ liệu đầu vào (được nhập trong form) tới Webserver. Có hai lựa chọn, GET và POST; chúng ta sẽ trình bày phần này ở mục sau.
- NAME: Thuộc tính này chứa tên của form. Mặc dù không cần thiết, nhưng chúng ta nên đặt tên cho form. Trong phần 6.2, chúng ta sẽ bàn tới cách viết các chương trình phía-máy-trạm bằng JavaScript trong đó có việc tham chiếu tới các form thông qua tên và thực hiện các kiểm tra trên những trường của form.
Bên trong Form HTMLs, các thẻ INPUT, SELECT, và TEXTAREA được sử dụng để xác định các thành phần đầu vào: một form có thể có nhiều thành phần của mỗi loại. Thành phần đầu vào đơn giản nhất là một trường INPUT.
Một ví dụ về thẻ INPUT như sau:
<INPUT TYPE="text" NAME="title">
Thẻ INPUT có một số thuộc tính. Ba thuộc tính quan trọng nhất là TYPE, NAME và VALUE. Thuộc tính TYPE xác định kiểu của trường đầu vào. Nếu thuộc tính TYPE có giá trị là text, thì trường này nhận giá trị là text. Nếu thuộc tính TYPE có giá trị là password, thì trường đầu vào là một trường text mà những ký tự nhập vào dù là gì thì cũng chỉ hiển thị ra màn hình là những ký tự *. Nếu thuộc tính TYPE là kiểu reset, nó là một nút đơn giản có khả năng thiết lập lại tất cả các trường đầu vào của form thành giá trị mặc định của chúng. Nếu thuộc tính TYPE có giá trị là submit thì nó là một nút có khả năng gửi các giá trị của các trường đầu vào khác nhau trong form tới máy chủ. Nhớ rằng reset và submit sẽ ảnh hưởng tới toàn bộ form. Trong ví dụ trước, chúng ta xác định title là NAME của trường input.
Thuộc tính NAME của thẻ INPUT xác định tên cho trường này và được sử dụng để nhận ra giá trị của trường đầu vào khi nó được gửi tới máy chủ. NAME phải được thiết đặt cho các thẻ INPUT của tất cả các loại ngoại trừ submit và reset.
Thuộc tính VALUE của thẻ input có thể được sử dụng cho các trường text hoặc password để xác định nội dung mặc định của trường này. Với các nút submit hoặc Form trong Hình 11 chỉ ra hai trường text, một là trường input text thông thường và một là trường password. Nó cũng chứa hai nút, một nút reset có nhãn là ‘'Reset
Values’ và một nút có nhãn là ‘Log on’. Ghi nhớ rằng có hai trường input được đặt tên, ngược lại hai nút reset và submit không có thuộc tính NAME.

Form HTMLs có các cách khác nhau để nhận giá trị đầu vào, như các thẻ TEXTAREA và SELECT đã nhắc đến ở trên; chúng ta không bàn sâu đến chúng ở đây.
Gửi các tham số tới các script phía máy chủ
Như đã đề cập trong phần mở đầu của mục 6.1, có hai cách khác nhau để gửi dữ liệu trong Form HTML tới Webserver. Nếu sử dụng phương thức GET thì những nội dung của form này được tập hợp vào một truy vấn URI (sẽ trình bày sau) và gửi tới máy chủ. Nếu sử dụng phương thức POST, thì nội dung của form này được mã hoá như trong phương thức GET, nhưng nội dung này được gửi trong một khối dữ liệu độc lập thay vì gắn trực tiếp chúng vào một URI. Vì thế trong phương thức GET nội dung của form người dùng có thể nhìn thấy như một URI có cấu trúc, ngược lại đối với phương thức POST, nội dung của form được gửi bên trong một thông điệp HTTP và người dùng không được nhìn thấy chúng.
Việc sử dụng phương thức GET cung cấp cho người dùng cơ hội để đánh dấu một trang nào đó cùng với URI có cấu trúc và vì thế có thể ‘nhảy’ trực tiếp tới những phần sau của nó; điều này là không thể khi sử dụng phương thức POST. Lựa chọn GET hay POST nên được xác định bằng ứng dụng.
Hãy cùng chúng tôi xem đoạn mã của URI khi phương thức GET được sử dụng. Đoạn mã URI có dạng sau:
action?name1=valuel&name2=value2&name3=value3
Action là một URI đã xác định trong thuộc tính ACTION của thẻ FORM, hoặc URI văn bản hiện tại nếu thuộc tính ACTION không được chỉ ra. Các cặp name=value là giá trị đầu vào mà người dùng đã nhập trong các trường INPUT của form. Với những trường INPUT mà người dùng không nhập dữ liệu cho nó, phần tên vẫn được biểu diễn kèm với giá trị rỗng (name=). Cụ thể, xem xét form nhập vào password ở cuối phần trước. Giả sử rằng người dùng nhập giá trị ‘John Doe’ vào trường username, và ‘secret’ vào password. Thì request URI là:
page.jsp?username=John+Doe&password=secretDữ liệu đầu vào được nhập qua form có thể chứa những ký tự ASCII thông thường, ví dụ những ký tự trống, nhưng URIs phải là một xâu liên tục không chứa ký tự trống. Vì thế, các ký tự đặc biệt như ký tự trống, ‘=’, và những ký tự không có khả năng in ra phải được mã hoá một cách đặc biệt. Để tạo ra một URI có các trường được mã hoá, chúng ta thực hiện các bước sau:
- Chuyển đổi tất cả các ký tự đặc biệt trong phần name và giá trị là ‘%xyz’, trong đó ‘xyz’ là giá trị mã ASCII của ký tự theo hệ 16. Những ký tự đặc biệt bao gồm =, &, %, +, và những ký tự không thể in được. Ghi nhớ rằng chúng ta có thể mã hoá tất cả các ký tự theo giá trị ASCII của chúng.
- Chuyển đổi tất cả các ký tự trống thành ký tự ‘+’.
- Gán phần tên và giá trị tương ứng bằng cách sử dụng dấu ‘=’ và sau đó dán các cặp tên-giá trị cùng với dấu ‘&’ để tạo ra một request URI của form:
action?namel=valuel&name2=value2&name3=value3Lưu ý thứ tự xử lý các thành phần đầu vào của Form HTML ở lớp giữa, chúng ta cần thuộc tính ACTION của thẻ FORM để gán nó tới trang, script, hoặc chương trình phần mềm sẽ xử lý những giá trị của những trường mà người dùng nhập vào form. Chúng ta sẽ bàn về các cách chương trình nhận giá trị của form trong Phần 7.1 và 7.3.
JavaScript
JavaScript là một ngôn ngữ kịch bản ở lớp máy trạm nơi mà chúng ta có thể thêm các chương trình chạy trực tiếp trên máy trạm (ví dụ, ở máy chạy trình duyệt Web). JavaScrip thường được sử dụng cho những tính toán ở máy trạm:
- Dò tìm trình duyệt: JavaScrip có thể được sử dụng để dò tìm các loại trình duyệt và tải về những trang Web cụ thể.
- Xác nhận tính hợp lệ của form: JavaScrip được sử dụng để thực hiện những kiểm tra tính nhất quán đơn giản trên những trường của form. Ví dụ, một chương trình JavaScrip có thể kiểm tra một trường trong form cho phép nhập địa chỉ email xem có ký tự @ trong đó không, hoặc tất cả các trường của form đều yêu cầu người sử dụng nhập dữ liệu vào.
- Điều khiển trình duyệt: Bao gồm những trang đang được mở, ví dụ một trang Web quảng cáo chứa nhiều trang Web bên trong nó, điều này có thể được lập trình bằng JavaScrip.
JavaScrip được nhúng vào văn bản HTML bằng một thẻ đặc biệt, thẻ SCRIPT. Thẻ SCRIPT có thuộc tính LANGUAGE, chỉ định ngôn ngữ mà script được viết. Với JavaScrip, chúng ta phải thiết đặt thuộc tính ngôn ngữ của nó. Một thuộc tính khác của thẻ SCRIPT là SRC, nó dùng để chỉ định một file ở bên ngoài được nhúng vào văn bản HTML. Thường thì file mã nguồn của JavaScrip có đuôi là ‘.js’. Đoạn mã lệnh sau đây chỉ ra có một file JavaScrip được nhúng trong một văn bản HTML:
<SCRIPT LANGUAGE=" JavaScript" SRC="validateForm.js">
</SCRIPT>
Thẻ SCRIPT có thể được đặt bên trong chú thích của HTML để đoạn mã chương trình JavaScrip không hiển thị nguyên văn trên các trình duyệt Web. Sau đây là một đoạn ví dụ JavaScrip khác giúp tạo ra hộp thoại pop-up cùng với một lời chào. Chúng ta đặt đoạn mã lệnh JavaScrip bên trong chú thích HTML vì những lý do vừa đề cập.
<SCRIPT LANGUAGE="JavaScript" >
<!--
alert("Welcome to our bookstore");
//-->
</SCRIPT>
JavaScrip cung cấp hai cách để tạo chú thích: chú thích cho một dòng sử dụng ký hiệu ‘//’ ở đầu dòng đó, và chú thích cho nhiều dòng sử dụng ‘/*’ để bắt đầu và ‘*/’ để kết thúc.
Biến trong JavaScrip có thể mang giá trị số, logic (true hoặc false), xâu ký tự, và một số kiểu dữ liệu khác. Các biến dùng chung (global) được khai báo cùng với từ khoá var, và chúng có thể được sử dụng ở bất kỳ đâu bên trong văn bản HTML. Những biến địa phương (local) dùng cho các hàng JavaScrip không cần được khai báo. Các biến không có kiểu cố định nhưng hoàn toàn có thể mang kiểu của dữ liệu được gán cho nó.
JavaScrip thường sử dụng những phép gán (=, +=, vv…), các phép toán số học (+, -, *, /, %), các phép so sánh (==, !=, >=, vv…), và những phép toán logic (&& cho phép AND, || cho phép OR, và ! cho phép NOT). Xâu ký tự có thể được nối dài sử dụng phép ‘+’ xâu. Kiểu dữ liệu của đối tượng xác định phép toán nào được sử dụng; ví dụ 1+1 là 2, vì chúng là phép cộng hai số, ngược lại “1”+ “1” là “11” vì chúng là phép nối xâu ký tự. Một số câu lệnh thường gặp trong JavaScrip là: các phép gán, các câu lệnh điều kiện (if (điều kiện) {các câu lệnh;} else {các câu lệnh;}), và các câu lệnh lặp (for-loop, do-while, và while-loop).
JavaScrip cho phép chúng ta tạo ra các hàng sử dụng từ khoá function:
function f (arg1 , arg2) {các câu lệnh;}. Chúng ta có thể gọi các hàm từ chương trình JavaScrip, và các hàm có thể trả về giá trị sử dụng từ khoá return.
Chúng ta tổng kết phần giới thiệu về JavaScrip này với một ví dụ về hàm JavaScrip để kiểm tra trường login và password của một form HTML là không rỗng. Hình 12 chỉ ra hàm JavaScrip này và form HTML. Đoạn mã này là một hàm testLoginEmpty() dùng để kiểm tra xem có trường nào trong form LoginForm bị rỗng không. Hàm testLoginEmpty được kiểm tra trong một form event handler. Một event handler là một hàm được gọi nếu một sự kiện nào đó xảy ra trên một đối tượng trong Website. Even handler chúng ta sử dụng ở đây là onSubmit, nó được gọi nếu nút submit được nhấn (hoặc nếu người dùng nhấn trở lại vào một trường text trong form). Nếu event handler trả về giá trị true, thì nội dung của form được gửi (submit) tới máy chủ, ngược lại nội dung này sẽ không được gửi tới máy chủ. JavaScrip có nhiều chức năng hơn là những kiến thức cơ bản được giới thiệu trong phần này; những điều thú vị về JavaScrip bạn có thể tìm hiểu thêm trong những phần tham khảo được giới thiệu ở cuối chương.

Style Sheets
Các máy trạm khác nhau có chế độ hiển thị khác nhau, vì lẽ đó chúng ta cần nhiều cách khác nhau để hiển thị cùng một thông tin. Ví dụ, trong một trường hợp đơn giản nhất, chúng ta cần sử dụng kích thước và màu chữ khác nhau để đảm bảo sự tương phản cao trên màn hình đen- trắng. Ví dụ phức tạp hơn, chúng ta có thể cần sắp xếp lại các đối tượng trên một trang để thích hợp với các loại màn hình nhỏ như các màn hình thiết bị cầm tay. Một ví dụ khác, chúng ta có thể đánh dấu một số thông tin quan trọng trên trong trang. Style Sheets là một cách để cùng một nội dung văn bản sẽ được hiển thị trên các định dạng khác sao cho phù hợp.
Một Style Sheets chứa các cấu trúc hướng dẫn một trình duyệt Web (hoặc bất kỳ cái gì mà máy trạm sử dụng để hiển thị một trang Web) cách chuyển đổi dữ liệu của một văn bản để hiển thị sao cho thích hợp với các màn hình máy trạm khác nhau.

Có hai ngôn ngữ Style Sheets: XSL và CSS. CSS được tạo cho HTML với mục đích phân chia những đặc tính hiển thị của các thẻ định dạng khác nhau vào bản thân các thẻ đó. XSL là phần mở rộng của CSS để phục vụ riêng cho các văn bản XSL; bên cạnh đó cho phép chúng ta định nghĩa mức độ các đối tượng được định dạng, XLS chứa một ngôn ngữ chuyển đổi cho phép chúng ta sắp xếp lại các đối tượng. Những file đích của CSS là những file HTML, trong khi đó những file đích của XSL là những file XML.
Cascading Style Sheets
Cascading Style Sheet (CSS) được sử dụng để định nghĩa cách thức hiển thị các thẻ HTML. (Trong Phần 13, chúng ta đã giới thiệu một ngôn ngữ Style Sheets được thiết kế cho các văn bản XML). Thông thường, các Style được lưu trữ trong Style Sheets- là nơi chứa các định nghĩa của style. Rất nhiều văn bản HTML khác nhau, như tất cả các văn bản trong một website, có thể tham chiếu tới cùng CSS. Vì thế, chúng ta có thể thay đổi định dạng của một website bằng việc thay đổi một file duy nhất. Đây là một cách thay đổi việc bố trí của rất nhiều trang Web tại cùng một thời điểm rất tiện lợi, trong đó bước đầu tiên sẽ là hướng tới việc phân tách nội dung với việc trình bày.
Một ví dụ Style Sheet được chỉ ra trong Hình13. Nó được nhúng trong một file HTML bằng dòng lệnh sau:
<LINK REL="style sheet" TYPE="text/ess" HREF="books.css"/>
Mỗi dòng trong một CSS sheet chứa ba phần; thành phần được lựa chọn (selector), thuộc tính (property), và giá trị (value). Chúng được sắp xếp theo cách sau:
Selector{property: value}
Slector là định dạng của một thẻ chúng ta đang định nghĩa. Property chỉ ra thuộc tính của thẻ mà ta đang muốn thiết đặt giá trị trong Style Sheet. Ví dụ, xem xét dòng đầu tiên của một ví dụ Style Sheet được chỉ ra trong Hình 13.
BODY {BACKGROUND-COLOR: yellow}
Dòng này có cùng tác dụng khi thay đổi mã HTML như sau:
<BODY BACKGROUND-COLOR= "yellow" >.
Giá trị nên đặt trong dấu ngoặc khi chúng có nhiều hơn một từ. Một Selector có thể có nhiều hơn một thuộc tính và chúng được phân tách nhau bằng dấu phẩy như được chỉ ra trong dòng cuối cùng của ví dụ Hình 13.
P {MARGIN-LEFT: 50px; COLOR: red}CSS có các ký hiệu mở rộng; phần tham khảo ở cuối chương chỉ ra những cuốn sách và các tài liệu trực tuyến về CSSs.
XSL
XLS là một ngôn ngữ của các Style Sheets dùng cho các mục đích đặc biệt. Một XLS style Sheet là một file biểu diễn cách thức hiển thị một văn bản XML nào đó. XSL chia sẻ những tính năng của CSS và tương thích với nó (mặc dù nó sử dụng những ký hiệu đặc biệt.)
Khả năng của XLS là rất lớn, vượt xa so với những tính năng của CSS. XSL chứa ngôn ngữ chuyển đổi XSL (XSL Transformation language), còn gọi là XSLT, một ngôn ngữ cho phép chúng ta biến đổi một file đầu vào là một văn bản XML thành một văn bản XML có cấu trúc khác. Ví dụ, với XLST chúng ta có thể thay đổi thứ tự các thẻ chúng ta đang hiển thị (ví dụ, sắp xếp chúng), xử lý các thẻ, ngăn chặn các thẻ trong một vùng và biểu diễn chúng ở một vùng khác, và thêm những đoạn văn bản cần thiết khi trình bày.
XSL cũng chứa một XML Path Language (XPath), ngôn ngữ này cho phép chúng ta tham chiếu tới các phần khác nhau của một văn bản XML. Chúng ta sẽ bàn về Xpath trong Phần 27. XSL cũng chứa XSL Formatting Object, một cách định dạng đầu ra của một XSLT nào đó.
Lớp giữa
Trong phần này chúng ta bàn đến các công nghệ được sử dụng cho lớp giữa. Thế hệ đầu tiên của các ứng dụng lớp giữa là các chương trình độc lập được viết bằng các ngôn ngữ như C, C++, và Perl. Nhưng những người lập trình nhanh chóng nhận thức được rằng việc tương tác với một ứng dụng độc lập thật sự rất tốn kém; nó bao gồm việc khởi động ứng dụng bất cứ khi nào nó được yêu cầu và những quá trình trao đổi thông tin giữa webserver và ứng dụng. Do đó, cách làm này không đáp ứng được khi có một số lượng lớn người sử dụng đồng thời. Từ đó dẫn đến sự phát triển của các máy chủ ứng dụng (application server), nó cung cấp môi trường run-time cho một số công nghệ có thể được sử dụng để lập trình những thành phần ứng dụng trong lớp giữa. Hầu hết các website lớn hiện này sử dụng máy chủ ứng dụng để chạy các chương trình ứng dụng của lớp giữa.
Chúng ta bắt đầu phần 7.1 để tìm hiểu về Hệ giao tiếp cổng vào chung (Common Gateway Interface), một giao thức được sử dụng để chuyển những tham số từ các form HTML vào các chương trình ứng dụng chạy ở lớp giữa. Chúng ta giới thiệu về máy chủ ứng dụng trong phần 7.2. Sau đó, chúng ta trình bày về các công nghệ được sử dụng để viết ứng dụng ở lớp giữa: Java servlets (Phần7.3) và Java Server Pages (Phần 7.4). Chức năng quan trọng khác là duy trì trạng thái của các thành phần trong lớp giữa vì các thành phần máy trạm đi qua một loạt các bước để hoàn thành một giao dịch (ví dụ, quá trình thanh toán một giỏ hàng hoặc quá trình đặt vé máy bay). Trong Phần 7.5 chúng ta bàn đến Cookies, một trong những phương pháp tiếp cận để duy trì trạng thái.
CGI: The Common Gateway Interface
CGI kết nối các form HTML với các chương trình ứng dụng. Nó là một giao thức định nghĩa cách thức các tham số từ các form chuyển tới các chương trình ứng dụng ở phía máy chủ. Chúng ta không đi vào chi tiết của giao thức CGI cụ thể vì các thư viện sẽ cho phép các chương trình ứng dụng lấy các tham số từ form HTML; chúng ta xem xét một ví dụ trong một chương trình CGI. Chương trình kết nối với webserver thông qua CGI thường được gọi là CGI scripts, vì rất nhiều các chương trình ứng dụng như vậy được viết bằng ngôn ngữ script như Perl.
Ví dụ trong Hình 14 là một ví dụ của một chương trình tương tác với một Form HTML thông qua CGI. Webpage này chứa một form mà người sử dụng có thể điền tên tác giả. Nếu người dùng nhấn và nút “Send it”, script ‘findBooks’ chỉ ra trong Hình 14 được thực hiện như một quá trình độc lập. Giao thức CGI định nghĩa cách thức kết nối giữa form và script. Hình 15 minh hoạ những quá trình tạo ra khi sử dụng giao thức CGI.
Hình 16 chỉ ra một ví dụ CGI script được viết bằng ngôn ngữ Perl. Chúng ta bỏ qua việc kiểm tra lỗi để làm đơn giản chương trình. Perl là một ngôn ngữ lập trình thường được sử dụng để viết các CGI script và nhiều thư viện Perl, gọi là các modules cung cấp giao diện mức cao cho các giao thức CGI. Chúng ta sử dụng một trong những thư viện này, gọi là thư viện DBI trong ví dụ của chúng ta. Module CGI này là tập hợp những hàm tiện ích hỗ trợ việc tạo các CGI scripts. Trong phần 1 của script ví dụ, chúng ta trích ra một tham số của một form HTML, tham số này được gửi từ một máy trạm:
$authorName = $datain - > param('authorName');
Ghi nhớ rằng biến có tên authorName đã được sử dụng trong form của Hình 14 để đặt tên cho trường đầu vào đầu tiên. Để tiện lợi, giao thức CGI trừu tượng hoá việc thực thi thực sự cách thức một Webpage được trả về cho Web browser; Webpage đơn giản chỉ chứa đầu ra của chương trình của chúng ta, và chúng ta bắt đầu việc tập hợp trang HTML đầu ra trong Phần 2. Mọi thứ script viết trong các câu-lệnh-print là một phần của Webpage động được trả về cho brower. Chúng ta kết thúc trong Phần 3 bằng việc thêm vào các thẻ đóng cho trang kết quả.

Các máy chủ ứng dụng
Ứng dụng có thể được thực thi bằng việc gọi đến các chương trình phía máy chủ sử dụng giao thức CGI. Tuy nhiên, khi có một yêu cầu từ một Webpage nào đó, hệ thống đều phải tạo ra một tiến trình mới, giải pháp này không khả thi khi số lượng yêu cầu tại một thời điểm lớn. Vấn đề này dẫn đến sự phát triển của các máy chủ ứng dụng. Một máy chủ ứng dụng duy trì một bể (pool) các tiến trình và sử dụng nó để thực thi các yêu cầu. Vì thế, nó tránh được chi phí khởi động tiến trình mới cho mỗi yêu cầu.


Các máy chủ ứng dụng đã phát triển các gói ở lớp giữa phức tạp, cung cấp nhiều hàm để loại bỏ các tiến trình overhead. Chúng tạo thuận lợi cho việc truy cập đồng thời tới nhiều nguồn dữ liệu khác nhau (ví dụ, bằng việc cung cấp JDBC drivers), và cung cấp các dịch vụ quản lý phiên làm việc (session management). Thường thì, các tiến trình có một số bước. Người sử dụng hy vọng hệ thống xử lý giao dịch của mình giống như chỉ có một giao dịch tại một thời điểm. Một số phiên làm việc được nhận diện bằng cookies, URI extensions, và các trường ẩn ở trong các Form HTML có thể được sử dụng để nhận diện một phiên làm việc. Các máy chủ ứng dụng cung cấp các chức năng để nhận ra một phiên làm việc nào đó khởi động và kết thúc và giữ lại dấu vết của các phiên làm việc của từng người sử dụng. Chúng cũng giúp đảm bảo có được các truy cập cơ sở dữ liệu bằng việc hỗ trợ một cơ chế user-id phổ biến. (Chi tiết hơn về bảo mật sẽ được trình bày trong Chương 21).
Servlets
Java servlets là những đoạn chương trình Java có thể chạy ở lớp giữa, Webservers hoặc máy chủ ứng dụng. Có những quy ước đặc biệt xác định cách thức đọc dữ liệu đầu vào và cách thức viết dữ liệu đầu ra bằng servlets. Servlets là platform độc lập, vì thế chúng đã trở nên rất phổ dụng đối với những nhà phát triển Web.
Vì servlets là những chương trình Java nên chúng rất linh hoạt. Ví dụ, servlets có thể xây dựng được Webpages, truy cập cơ sở dữ liệu, và duy trì trạng thái. Servlets có thể truy cập tới tất cả Java APIs, bao gồm JDBC. Tất cả servlets phải thực thi giao diện Servlet. Trong hầu hết các trường hợp, servlets có thể thực hiện các lớp HttpServlet của các server kết nối với các máy trạm thông qua HTTP. Lớp HttpServlet cung cấp các phương thức như doGet và doPost để nhận các tham số từ các form HTML, và nó trả kết quả cho các máy trạm thông qua HTTP. Các Servlets kết nối thông qua các giao thức khác (như ftp) cần phải thêm lớp GenericServlet.
Servlets là những lớp Java được biên dịch bằng Servlet container. Servlet container quản lý thời gian sống (life-span) của các servlets độc lập bằng việc tạo và hủy chúng. Mặc dù servlets có thể trả lời bất kỳ loại yêu cầu nào, nhưng chúng hầu như chỉ được sử dụng để mở rộng các ứng dụng trên Webservers. Với những ứng dụng này, có một thư viện rất hữu ích của các lớp servlet HTTP-riêng biệt.
Servlets thường quản lý các yêu cầu từ các form HTML và duy trì trạng thái giữa các máy chủ và máy trạm. Chúng ta bàn về cách thức duy trì trạng thái này trong Phần 7.5. Một mẫu (templete) của một cấu trúc servlet chung được minh hoạ trong Hình 18. Servlets đơn giản này chỉ đưa ra hai chữ “Hello World”, nhưng nó chỉ ra cấu trúc chung của của một servlets đầy đủ-chính thức. Đối tượng yêu cầu (request object) được sử dụng để đọc dữ liệu từ form HTML. Đối tượng phản hồi (response object) được sử dụng để xác định mã trạng thái phản hồi HTTP và các tiêu đề (header) của phản hồi HTTP. Đối tượng đầu ra này được sử dụng để soạn thảo nội dung trả về cho các máy trạm.
Nhớ rằng HTTP trả về một dòng trạng thái, một tiêu đề, một dòng trống và sau đó là đến nội dung. Trong ví dụ này servlets của chúng ta chỉ trả về đoạn text đơn giản. Chúng ta có thể mở rộng servlets này bằng việc thiết lập kiểu nội dung cho HTML, việc thêm HTML như sau:

Điều gì xảy ra trong suốt quá trình tồn tại của một servlet? Một vài phương thức được gọi ở các giai đoạn khác nhau trong quá trình phát triển của một servlet. Khi một trang yêu cầu là một servlet, webserver gửi yêu cầu này tới servlet container. Tại thời điểm tạo servlet, servlet container gọi tới phương thức init(), và trước khi kết thúc servlet này, servlet container gọi tới phương thức destroy() của servlet này.
Khi một servlet container gọi một servlet, nó bắt đầu bằng phương thức service(), sau đó phương thức này tự động gọi đến các phương thức sau dựa trên phương pháp chuyển giao HTTP: service() gọi doGet() ứng với một HTTP GET request, và nó gọi doPost() ứng với một HTTP POST request. Việc phát đi tự động này cho phép một servlet thực hiện các công việc khác nhau trên một yêu cầu dữ liệu tuỳ vào phương pháp chuyển giao HTTP. Thường thì, chúng ta không ghi đè lên phương thức service() trừ khi chúng ta muốn lập trình cho một servlet xử lý cả HTTP POST request và HTTP GET request giống hệt nhau.
Chúng ta tổng kết những nội dung đã trình bày về servlets bằng một ví dụ trong Hình 19, ví dụ này minh hoạ cách thức gửi các tham số từ một Form HTML tới một servlet.

JavaServer Pages
Trong những phần trước, chúng ta đã xem xét cách sử dụng các chương trình Java ở lớp giữa để mã hoá ứng dụng và kiết xuất ra những Webpage một cách linh động. Nếu chúng ta cần xuất ra các trang HTML, chúng ta lập trình nó là một đối tượng đầu ra. Vì thế, chúng ta có thể nghĩ về servlets như là một chương trình Java, cùng với việc nhúng HTML cho đầu ra.
JavaServer pages (JSPs) trao đổi các vai trò của đầu ra và ứng dụng. JavaServer pages được viết trong HTML cùng với servlet- như các đoạn mã lệnh được nhúng trong các thẻ HTML đặc biệt. Vì thế, khi so sánh với servlets, JavaServer pages thích hợp hơn để xây dựng các giao diện chỉ có một số đoạn chương trình bên trong, ngược lại servlets thích hợp hơn đối với các chương trình ứng dụng phức tạp.
Trong khi có một sự khác nhau lớn đối với những người lập trình, lớp giữa xử lý JavaServer pages theo một cách rất đơn giản: Chúng thường xuyên được biên dịch thành một servlet, sau đó được một servlet container quản lý tương tự như các servlets khác.
Đoạn chương trình trong Hình 20 chỉ ra một ví dụ JSP đơn giản. Trong phần giữa của đoạn mã HTML này, chúng ta truy cập tới thông tin từ một form.

Duy trì trạng thái
Như những gì chúng ta đã thảo luận ở các phần trước, hệ thống cần phải duy trì trạng thái của người dùng khi họ đi qua các trang khác nhau. Ví dụ, xem xét việc một người dùng muốn thanh toán một số mặt hàng ở Website ‘Barnes and Nobble’. Đầu tiên, người dùng này phải thêm các sản phẩm muốn mua vào giỏ hàng trong khi đó cô ấy có thể duyệt qua các trang khác nhau.
Chúng ta gọi một tương tác với một Webserver là không lưu trạng thái nếu không có thông tin nào được duy trì từ một yêu cầu này đến một yêu cầu tiếp theo. Chúng ta gọi một tương tác với một Webserver là stateful, hoặc chúng ta có thể gọi là state được duy trì, nếu có một phần bộ nhớ được sử dụng để lưu trữ thông tin giữa các yêu cầu tới máy chủ, và những hành động khác nhau được đưa ra tuỳ thuộc vào nội dung được lưu trữ là gì. Giao thức HTTP là không lưu trạng thái.
Trong ví dụ Barnes và Nobble của chúng ta, chúng ta cần duy trì thông tin về giỏ hàng của người dùng. Vì trạng thái này không được duy trì ở giao thức HTTP nên nó phải được duy trì ở máy chủ hoặc ở máy trạm. Vì người thiết kế đã xây dựng giao thức HTTP là không lưu trạng thái, hãy cùng chúng tôi ôn lại những ưu và nhược điểm của quyết định này. Đầu tiên, một giao thức không lưu trạng thái dễ dàng cho lập trình và sử dụng, và nó có nhiều tác dụng với các ứng dụng chỉ yêu cầu tải các thông tin tĩnh. Thêm nữa, không bộ nhớ ngoài nào cần được sử dụng để duy trì trạng thái, vì thế giao thức này rất hiệu quả. Mặt khác, thiếu các cơ chế bổ sung ở lớp trình diễn và lớp giữa, chúng ta không thể ghi lại các yêu cầu ở phía trước, và chúng ta không thể lưu lại được các giỏ hàng và các đăng nhập người dùng.
Vì chúng ta không thể duy trì trạng thái bằng giao thức HTTP, vậy thì chúng ta sẽ duy trì nó ở đâu? Có hai cách lựa chọn. Chúng ta có thể thực hiện việc duy trì trạng thái này ở lớp giữa, bằng việc sắp xếp thông tin trong bộ nhớ chính cục bộ của ứng dụng, hoặc thậm chí ở hệ thống cơ sở dữ liệu. Ngoài ra, chúng ta có thể duy trì trạng thái ở máy trạm bằng việc lưu trữ dữ liệu trong form này thông qua một cookie. Chúng ta sẽ bàn đến hai cách duy trì trạng thái này trong hai phần tiếp theo.
Duy trì trạng thái ở lớp giữa
Ở lớp giữa, có một vài nơi ở lớp giữa cho phép ta duy trì trạng thái. Trước hết, chúng ta có thể lưu lại trạng thái này ở lớp đáy, trong máy chủ cơ sở dữ liệu. Trạng thái này giúp phục hồi hệ thống khi có sự cố, nhưng một truy cập cơ sở dữ liệu được yêu cầu để truy vấn và cập nhật trạng thái, một nút cổ chai dễ dàng hình thành. Mặt khác, ta có lưu trạng thái ở bộ nhớ chính của lớp giữa. Nhược điểm là những thông tin này là những thông tin hay thay đổi vì thế tốn rất nhiều bộ nhớ. Chúng ta cũng có thể lưu trữ trạng thái ở các file cục bộ của lớp giữa, một sự thoả hiệp giữa hai cách tiếp cận trên.
Một cách làm ở đây duy trì trạng thái ở lớp giữa hoặc lớp cơ sở dữ liệu chỉ cho những dữ liệu cần được duy trì trên nhiều phiên làm việc khác nhau. Ví dụ dữ liệu này là những hoá đơn của khách hàng trong quá khứ, một chuỗi những thao tác kích chuột cần phải ghi lại khi người dùng đi qua các website này, hoặc những lựa chọn cố định khác mà người dùng làm, như quyết định về cách bố trí trang theo sở thích của mình. Như những ví dụ minh hoạ này, thông tin trạng thái thường tập trung xung quanh những người dùng tương tác với website.
Duy trì trạng thái ở lớp trình diễn: Cookies
Một khả năng khác là chúng ta duy trì trạng thái tại lớp trình diễn và gửi nó tới lớp giữa cùng với HTTP request. Chúng ta thao tác chủ yếu với giao thức HTTP bằng việc gửi những thông tin bổ sung vào mỗi request. Những thông tin này được gọi là một cookie.
Một cookie là một tập các cặp {name, value} có thể được quản lý ở lớp trình diễn và lớp giữa. Cookies dễ dàng sử dụng trong Java servlets và JavaServer pages và cung cấp một cách đơn giản để làm việc với dữ liệu không quan trọng duy trì ở các máy trạm. Chúng duy trì một số phiên làm việc của máy trạm bởi vì chúng tồn tại trong các catch của trình duyệt ngay cả khi các trình duyệt đã đóng.
Một nhược điểm của cookies là chúng thường được coi như những ‘kẻ xâm lấn’, vì thế rất nhiều người dùng vô hiệu hoá cookies trên trình duyệt của họ; trình duyệt cho phép người dùng ngăn chặn cookies lưu trên máy tính. Một nhược điểm khác là dữ liệu trên một cookie có dung lượng tối đa là 4KB, nhưng với hầu hết ứng dụng đây không phải là một giới hạn tồi. Chúng ta có thể sử dụng các cookies để lưu trữ các thông tin như: giỏ hàng của người dùng, thông tin đăng nhập và những lựa chọn không ‘kiên định’ khác được sinh ra trong phiên làm việc hiện tại. Tiếp theo, chúng ta sẽ bàn đến cách các cookies có thể được điều khiển bằng servlets ở lớp giữa.
The Servlet Cookie API
Một cookie được lưu trữ trong một file text nhỏ ở máy trạm và nó chứa các cặp (name, vale), trong đó cả name và value đều là xâu ký tự. Chúng ta tạo ra một cookie mới bằng lớp Java Cookie trong chương trình ứng dụng ở lớp giữa:
Cookie cookie = new Cookie("username","guest");
cookie..setDomain( "www.bookstore.com");
cookie.setSecure(false); // no SSL required
cookie.setMaxAge(60*60*24*7*31); // one month lifetime
response.addCookie(cookie);
Hãy cùng chúng tôi nhìn vào đoạn chương trình này. Đầu tiên, chúng ta tạo ra một đối tượng cookie xác định bằng cặp {name, value}. Tiếp đến chúng ta thiết đặt các thuộc tính của cookie này; sau đây một số thuộc tính chung nhất:
- setDomain và getDomain: Domain này xác định Website sẽ nhận cookie. Giá trị mặc định của thuộc tính này chính là domain đã tạo ra cookie.
- setSecure và getSecure: Nếu cờ (flag) bằng true, thì cookie này được gửi chỉ khi chúng ta đang sử dụng một phiên bản Sercure của giao thức HTTP, ví dụ là SSL.
- setMaxAge và getMaxAge: Thuộc tính MaxAge xác định thời gian sống của cookie tính theo đơn vị giây. Nếu giá trị MaxAge nhỏ hơn hoặc bằng 0, cookie này được xoá ngay khi đóng trình duyệt.
- setName và get Name: Chúng ta không sử dụng những hàm này trong đoạn chương trình của chúng ta, chúng cho phép chúng ta đặt tên cho cookie.
- setValue và getValue: Những hàm này cho phép chúng ta thiết đặt và đọc giá trị của cookie.
Cookie được thêm vào request object trong Java servlets để được gửi tới máy trạm. Khi một cookie được nhận từ một site (ví dụ www.bookstore.com), trình duyệt Web trên máy trạm này gán nó vào tất cả các HTTP request nó gửi tới site này cho đến khi cookie kết thúc.
Chúng ta có thể truy cập tới nội dung của một cookie trong lớp giữa thông qua phương thức getCookies() của đối tượng request, nó sẽ trả về một mảng các đối tượng cookies. Đoạn chương trình sau đây đọc mảng này và tìm cookie có tên là ‘username’.
Cookie[] cookies = request.getCookies();
String theUser;
for(int i=0; i < cookies.length; i++) {
Cookie cookie = cookies [i];
if (cookie.getName().equals("username"))
theUser = cookie.getValue();
}
Một kiểm tra đơn giản có thể được sử dụng để kiểm tra một người dùng nào đó đã tắt cookies: Gửi một cookie tới người dùng này, sau đó kiểm tra xem đối tượng request được trả về vẫn chứa cookie này hay không. Ghi nhớ rằng một cookie không bao giờ nên chứa password chưa được mã hoá hoặc những thông tin bí mật khác mà chưa mã hoá, vì người dùng có thể dễ dàng kiểm tra, sửa, và xoá bất kỳ cookie nào tại bất cứ thời điểm nào. Ứng dụng cần phải có những kiểm tra sự nhất quán để đảm bảo rằng dữ liệu trong cookie là đúng.
Trường hợp nghiên cứu: Cửa hàng sách trên Internet
Bây giờ DBDudes hướng tới việc thực hiện của lớp ứng dụng và xem xét bổ sung kết nối DBMS tới World Wide Web.
DBDudes bắt đầu với việc xem xét quản lý các phiên làm việc (section). Ví dụ, người dùng muốn đăng nhập tới site, duyệt danh mục và lựa chọn những cuốn sách muốn mua mà không muốn phải nhập lại mã số định danh của họ. Công việc của section là phải quản lý các quá trình lựa chọn sách, thêm chúng vào giỏ, và có thể cả việc loại bỏ một số quyển sách ra khỏi giỏ, kiểm tra và thanh toán sách.
Sau đó DBDudes xem xét xem Webpages hiển thị sách nên là tĩnh hay động. Nếu có một Webpage tĩnh cho mỗi quyển, thì trong cơ sở dữ liệu chúng ta cần thêm một trường vào quan hệ Books để chỉ ra vị trí của file chứa quyển sách đó. Thậm chí cần có một thiết kế giao diện đặc biệt cho mỗi quyển sách. Đây là một giải pháp tốn rất nhiều công sức. DBDudes thuyết phục B&N để xây dựng một Webpage cho tất cả các quyển sách theo một mẫu chung và thông tin về một quyển sách nào đó được lấy ra từ quan hệ Books. Vì thế, DBDudes không sử dụng các trang HTML tĩnh như ví dụ trong Hình 1 để hiển thị thông tin.
DBDudes cân nhắc việc sử dụng XML để định dạng dữ liệu giữa máy chủ cơ sở dữ liệu và lớp giữa, hoặc giữa lớp giữa và lớp máy trạm. Việc trình diễn dữ liệu trong XML của lớp giữa được minh hoạ trong Hình 2 và 3 cho phép dễ dàng tích hợp những nguồn dữ liệu khác trong tương lai, nhưng B&N nhận thấy rằng ứng dụng không cần đến sự tích hợp này, vì thế họ quyết định không sử dụng XML.
DBDudes thiết kế chương trình như sau. Họ nghĩ rằng sẽ có các Webpage khác nhau như sau:
- Index.jsp: Trang chủ của B&N. Đây là trang chính của cửa hàng. Trang này có các trường tìm kiếm dạng text và các nút cho phép người dùng tìm kiếm sách theo tên tác giả, mã ISBN, hoặc tiêu đề. Ở đây cũng có đường liên kết tới trang hiển thị giỏ hàng –cart.jsp.
- Login.jsp: Cho phép những người dùng đã đăng ký được đăng nhập vào hệ thống. Ở đây DBDudes sử dụng form HTML tương tự như trong Hình 11. Ở lớp giữa, họ sử dụng đoạn mã lệnh tương tự như trong Hình 19 và JavaServer pages như trong Hình 20.
- Search.jsp: Liệt kê tất cả các quyển sách trong cơ sở dữ liệu thoả mãn điều kiện tìm kiếm của người dùng. Người dùng có thể thêm những quyển vừa tìm thấy vào giỏ hàng; mỗi quyển có một nút để chuyển nó tới giỏ hàng (Nếu quyển này đã tồn tại trong giỏ, thì số lượng mua sẽ tăng lên một). Ở đây cũng có một trường cho phép nhập số lượng quyển sách muốn mua đó. Trang search.jsp cũng chứa một nút trực tiếp liên kết tới trang cart.jsp.
- Cart.jsp: Liệt kê tất cả các quyển sách đang có trong giỏ hàng. Danh sách này nên bao gồm tất cả các quyển sách trong giỏ hàng cùng với những thông tin về tên sách, giá, và một hộp thoại dạng text cho phép người dùng nhập vào số lượng muốn mua của mỗi quyển, và một nút để xoá bỏ sách ra khỏi giỏ ứng với mỗi quyển. Trang này còn có ba nút khác: một nút để tiếp tục quá trình mua hàng (nút này giúp người dùng trở về index.jsp), nút thứ hai để cập nhật giỏ hàng sau khi đã sửa lại thông tin về số lượng sách trong hộp thoại text, và nút thứ ba để đi tới hoá đơn, trực tiếp đưa người dùng tới trang confirm.jsp.
- Confirm.jsp: Đưa ra một hoá đơn hoàn chỉnh và cho phép người dùng nhập vào thông tin của họ và mã khách hàng (custormer ID). Có hai nút ở trang này: một nút để huỷ bỏ hoá đơn và nút thứ hai là để chấp nhận (submit) hoá đơn cuối cùng. Nút huỷ bỏ sẽ huỷ đi hoá đơn và đưa người dùng về trang chủ. Nút submit sẽ cập nhật cơ sở dữ liệu cùng với hoá đơn mới, làm rỗng giỏ hàng và giúp người dùng quay về trang chủ.
DBDudes cũng đề nghị sử dụng JavaScrip ở lớp giữa để kiểm tra dữ liệu đầu vào trước khi nó được gửi tới lớp giữa. Ví dụ, trong trang login.jsp, DBDudes muốn viết đoạn chương trình JavaScrip tương tự như trong Hình 12.
Điều này dẫn DBDudes đến quyết định cuối cùng: cách kết nối các ứng dụng với DBMS. Họ xem xét hai cách chính trình bày trong Phần 7: CGI script hay là sử dụng một máy chủ ứng dụng. Nếu họ sử dụng CGI scripts, họ sẽ phải viết chương trình quản lý giao dịch- đây là một công việc không dễ. Nếu họ sử dụng một máy chủ ứng dụng, họ có thể sử dụng tất cả các chức năng mà máy chủ này cung cấp. Vì thế, họ đề nghị B&N thực hiện việc xử lý phía máy chủ sử dụng một máy chủ ứng dụng.
B&N chấp nhận việc quyết định sử dụng một máy chủ ứng dụng, nhưng quyết định rằng không có đoạn mã chương trình nào được áp dụng cho máy chủ ứng dụng vì B&N không muốn bị phụ thuộc vào một nhà cung cấp. DBDudes đồng ý xây dựng các phần sau:
- DBDudes thiết kế các trang mức đỉnh- những trang cho phép người dùng đi tới Website cũng như một loạt những form tìm kiếm và trình bày kết quả.
- Giả sử rằng DBDudes lựa chọn một máy chủ ứng dụng dựa vào Java, họ phải biết Java servlets để xử lý các yêu cầu đưa ra từ form. Có khả năng họ sử dụng lại những JavaBean đang tồn tại. Họ có thể sử dụng JDBC như là một giao diện cơ sở dữ liệu; những ví dụ của chương trình JDBC có thể tìm thấy trong Phần 6.2. Thay vì lập trình servlets, họ có thể dùng JavaServer pages và chú thích các trang bằng các thẻ đánh dấu JSP đặc biệt.
- DBDudes lựa chọn một máy chủ ứng dụng sử dụng các thẻ đánh dấu riêng của họ, vì thế họ phải thương lượng lại với B&N, nhưng B&N không cho phép họ sử dụng những thẻ như thế trong chương trình.
Bây giờ, chúng ta giả sử rằng DBDudes và B&N đã chấp nhận sử dụng CGI scripts, DBDudes sẽ phải thực hiện các công việc sau:
- Tạo các trang HTML mức đỉnh cho phép người dùng truy cập đến trang Web và hàng loạt các form cho phép người dùng tìm kiếm sách thông qua ISBN, tên tác giả, tiêu đề. Một trang ví dụ chứa form tìm kiếm được chỉ ra trong Hình 1. Khi thêm các form nhập dữ liệu đầu vào, DBDudes phải phát triển thêm các giao diện thích hợp để hiển thị kết quả.
- Phát triển ứng dụng để theo dõi một phiên làm việc của người dùng. Những thông tin liên quan phải được lưu trữ ở phía máy chủ hoặc ở trình duyệt của người dùng thông qua cookies.
- Viết các scripts xử lý những yêu cầu của người dùng. Ví dụ, một khách hàng có thể sử dụng một form gọi là ‘Search books by title’ (Tìm sách theo tiêu đề) để nhập tiêu đề và tìm kiếm sách theo tiêu đề. Giao diện CGI kết nối với một script xử lý yêu cầu này. Ví dụ trong Hình 16 là minh hoạ của script kiểu này viết bằng Perl sử dụng thư viện DBI để truy cập dữ liệu.
Những bàn luận trên của chúng ta chỉ mới đề cập đến các giao diện phục vụ khách hàng. DBDudes cũng cần phải thêm vào ứng dụng những giao diện cho phép nhân viên có thể cập nhật dữ liệu và người quản lý của B&N có thể truy vấn cơ sở dữ liệu để đưa ra những báo cáo tổng hợp về tình tình kinh doanh.
Toàn bộ những file về trường hợp nghiên cứu này có thể được tìm thấy trên Webpage của quyển sách này.
Câu hỏi ôn tập
Trả lời những câu hỏi ôn tập sau, câu trả lời có thể tìm thấy ở phần được liệt kê bên cạnh:
- URIs và URLs là gì? (Phần 2.1)
- Giao thức HTTP làm việc như thế nào? Giao thức không lưu trạng thái là gì? (Phần 2.2)
- Giải thích những khái niệm chính của HTML. Vì sao nó chỉ được sử dụng để biểu diễn dữ liệu và mà không được sử dụng để trao đổi dữ liệu? (Phần 3)
- HTML có những thiếu sót gì, và XML giải quyết chúng như thế nào? (Phần 4)
- Những thành phần chính của một văn bản XML là gì? (Phần 4.1)
- Vì sao chúng ta có XML DTDs? Thế nào là một văn bản XML được định dạng tốt? Một văn bản XML đúng là gì? Cho một ví dụ về một văn bản XML đúng nhưng không được định dạng tốt, và ngược lại. (Phần 4.2)
- Vai trò của domain-specific DTDs? (Phần 4.3)
- Kiến trúc ba lớp là gì? Những ưu điểm của nó so với kiến trúc một lớp và hai lớp? Trình bày một cách tổng quát các tính năng chính của mỗi thành phần trong kiến trúc ba lớp. (Phần 5)
- Giải thích cách thức kiến trúc ba lớp giải quyết các vấn đề sau của các ứng dụng Internet: tính không đồng nhất, máy trạm yếu (thin clients), tích hợp dữ liệu, phát triển phần mềm. (Phần 5.3)
- Viết một Form HTML . Mô tả tất cả các thành phần của một Form HTML . (Phần 6.1)
- Đâu là sự khác nhau giữa phương thức HTML POST và HTML GET? (Phần 11)
- JavaScrip sử dụng cho việc gì? Viết một hàm JavaScrip kiểm tra một thành phần của Form HTML có chứa một địa chỉ email đúng cú pháp. (Phần 6.2)
- Style Sheets giải quyết vấn đề gì? Những ưu điểm khi sử dụng Style Sheets? (Phần 6.3)
- Cascading Style Sheets là gì? Giải thích các thành phần của Cascading Style Sheets. XSL là gì và nó khác với CSS ở điểm nào? (Phần 6.3 và 13)
- CGI là gì và nó giải quyết những vấn đề gì? (Phần 7.1)
- Các máy chủ ứng dụng (application servers) là gì, nó khác với các Webservers như thế nào? (Phần 7.2)
- Servlets là gì? Cách thức servlets xử lý dữ liệu từ các form HTML? Giải thích những gì xảy ra trong suốt thời gian sống của một servlets. (Phần 7.3)
- Điều gì là sự khác nhau giữa servlets và JSP? Khi nào chúng ta nên sử dụng servlets và khi nào chúng ta nên sử dụng JSP? (Phần 7.4)
- Vì sao chúng ta cần duy trì trạng thái ở lớp giữa? Cookies là gì? Trình duyệt quản lý cookies như thế nào? Chúng ta có thể truy cập dữ liệu trong cookies từ servlets như thế nào? (Phần 7.5)
BÀI TẬP
Trả lời tóm tắt những câu hỏi sau:
- Giải thích các khái niệm và trình bày chúng được sử dụng để làm gì: HTML, URL, XML, Java, JSP, XSL, XSLT, servlet, cookie, HTTP, CSS, DTD.
- CGI là gì? Vì sao CGI được giới thiệu? Những nhược điểm của một kiến trúc sử dụng CGI scripts?
- Sự khác nhau giữa một Webserver và một máy chủ ứng dụng? Các chức năng mà máy chủ ứng dụng điển hình cung cấp?
- Một văn bản XML được định dạng tốt (well-formed) khi nào? Một văn bản XML đúng khi nào?
Câu trả lời với mỗi câu hỏi như sau:
- HTTP (HyperText Transfer Protocol) là một giao thức kết nối được sử dụng để kết nối các máy trạm với các máy chủ trên Internet. URL (Universal Resource Locator) là một xâu ký tự xác định một địa chỉ internet duy nhất. HTML (HyperText Markup Language) là một ngôn ngữ đơn giản sử dụng các thẻ đặc biệt để viết văn bản trên Internet. CSS (Cascading Style Sheets) được sử dụng để định nghĩa cách thức hiển thị các văn bản HTML. XML (Extensible Markup Language) cho phép người dùng định nghĩa các thẻ đánh dấu của bản thân họ trong một văn bản nào đó. XSL (Extensible Style Language) có thể được sử dụng để biểu diễn cách thức hiển thị một văn bản XML. XSLT (XML Transformation Language) là một ngôn ngữ cho phép biến đổi một đầu vào XML thành một cấu trúc XML khác. DTD (Document Type Declaration) biểu diễn cách thức sử dụng các thẻ mới trong văn bản XML. Java là một ngôn ngữ lập trình. Servlets là các phần nhỏ của Java chạy trên lớp giữa hoặc lớp máy chủ và được sử dụng cho bất kỳ chức năng nào mà Java cung cấp. JSP (JavaServer Pages) là các trang HTML có các đoạn mã servlet được nhúng vào. Cookies là một cách đơn giản để lưu các dữ liệu tại máy trạm.
- CGI (Common Gateway Interface) xác định cách thức máy chủ web kết nối với các chương trình khác bên phía máy chủ. Các chương trình CGI được sử dụng để chuyển dữ liệu trong form HTML tới các chương trình khác bên phía máy chủ. Mỗi một trang yêu cầu sẽ tạo ra một quá trình mới trên máy chủ.
- Web server quản lý các trao đổi với các web browser bên phía máy trạm. Các máy chủ ứng dụng được sử dụng để duy trì một bể các tiến trình. Thông thường, chúng ở lớp trung gian giữa web server và các nguồn dữ liệu như các hệ cơ sở dữ liệu. Các máy chủ ứng dụng bỏ qua các vấn đề như việc chồng tạo-tiến-trình và có thể cũng được cung cấp các tính năng khác như trừu tượng hóa những nguồn dữ liệu không đồng nhất và duy trì thông tin trạng thái của các phiên làm việc.
- Một văn bản XML là đúng nếu nó có DTD hỗ trợ và văn bản này tuân thủ những quy tắc của DTD. Văn bản XML có định dạng tốt nếu nó tuân thủ những hướng dẫn sau: (1) nó bắt đầu bằng khai báo XML, (2) nó chứa một phần tử gốc chứa tất cả các phần tử khác và (3) tất cả các phần tử được đặt lồng nhau.
Trả lời tóm tắt những câu hỏi sau về giao thức HTTP:
- Một giao thức kết nối là gì?
- Cấu trúc của một HTTP request message? Cấu trúc của một HTTP reponse message? Vì sao các HTTP message phải có một trường version (phiên bản)?
- Giao thức không lưu trạng thái là gì? Vì sao HTTP được thiết kế là không lưu trạng thái?
- Chỉ ra HTTP request message đưa ra khi bạn yêu cầu tới trang chủ của cuốn sách này (http://www.cs.wisc.edu/~dbbook). Chỉ ra HTTP response message mà máy chủ đưa ra.
Dành cho độc giả
Trong bài tập này, bạn được yêu cầu để viết các chức năng của một giỏ hàng; bạn sẽ sử dụng nó trong các bài tập theo sau. Viết một loạt các trang JSP hiển thị một giỏ hàng gồm các sản phẩm và cho phép người dùng thêm, xoá, thay đổi số lượng của từng sản phẩm. Để làm điều này, sử dụng một cookie lưu trữ các thông tin sau:
- UserID của người dùng sở hữu giỏ hàng.
- Số các sản phẩm có trong giỏ hàng.
- ProductID và số lượng của mỗi sản phẩm.
Dành cho độc giả
Trong bài tập trước, thay thế trang product.jsp bằng trang search.jsp. Trang này cho phép người dùng tìm kiếm sản phẩm theo tên hoặc mô tả sản phẩm. Nên có một hộp thoại dạng text để nhập thông tin cần tìm và các nút lựa chọn (radio button) cho phép người dùng lựa chọn giữa tìm-bằng-tên và tìm-bằng-mô-tả. Trang xử lý kết quả tìm kiếm nên giống như trang products.jsp (đã trình bày trong bài tập trước) và được gọi là product.jsp. Nên truy cập tới tất cả các bản ghi mà nội dung tìm kiếm là một chuỗi con của tên hoặc thông tin mô tả. Để tích hợp với bài tập trước, việc đơn giản là thay thế tất cả các liên kết tới products.jsp bằng search.jsp.
Dành cho độc giả
Viết một chương trình xác thực đơn giản (không cần mã hoá phawords). Chúng ta coi một người dùng là đã xác thực nếu cô ấy cung cấp cặp username-phaword đúng; ngược lại, chúng ta nói người dùng đó là chưa được xác thực. Để đơn giản, giả sử rằng bạn có một lược đồ cơ sở dữ liệu chỉ lưu trữ customer id và phaword:
- Khi người dùng đăng nhập vào hệ thống, như thế nào và ở đâu bạn ghi lại thông tin này.
- Thiết kế một trang cho phép một người dùng đã đăng ký đăng nhập vào hệ thống.
- Thiết kế một trang tiêu đề (header) để kiểm tra xem người dùng vào thăm trang này đã đăng nhập rồi.
Dành cho độc giả
TechnoBook.com đang trong quá trình tổ chức lại Website. Vấn đề chính là làm thế nào quản lý hiệu quả một số lượng lớn kết quả tìm kiếm. Trong một nghiên cứu về việc chương trình tương tác với người dùng, người ta biết rằng những người dùng hiện đại muốn hiển thị 20 kết quả tìm kiếm trong một lần, và họ muốn chương trình thực hiện như vậy. Những truy vấn trả về một đợt các kết quả được gọi là top N queries. (Xem phần 25.5 để biết cơ sở dữ liệu hỗ trợ việc này). Ví dụ, kết quả từ 1-20 được trả về, sau đó từ 21-40, sau đó 41-60 và tiếp tục như thế. Các công nghệ khác nhau được sử dụng để thực hiện điều này và TechnoBooks.com muốn thực hiện hai công nghệ.
Books(bookid:INTEGER,title:CHAR(80),author:CHAR(80),price: REAL)
For i = 1 to 111 {
Insert the tuple (i, "AAA", "AAA Author", 5.99)
i = i + 1
Insert the tuple (i, "BB", "BBB Author", 5.99)
i = i + 1
Insert the tuple (i, "CCC", "CCC Author", 5.99)
i = i + 1
Insert the tuple (i, "DDD", "DDD Author", 5.99)
i = i + 1
Insert the tuple (i, "EEE", "EEE Author", 5.99)

EXEC SQL SELECT B.Title
FROM Books B
WHERE (B.Title = 'DDD' AND B.Bookid > 101) OR (B.Title > 'DDD')
ORDER BY B.Title, B.Bookid
- Previous: Tiêu đề của bản ghi đầu tiên trong tập previous, và khoá chính của bản ghi đầu tiên trong tập previous.
- Next: Tiêu đề của bản ghi đầu tiên trong tập next, và khoá chính của bản ghi đầu tiên trong tập next.
Dành cho độc giả
BÀI TẬP LỚN
Trong chương này, bạn tiếp tục các bài tập ở chương trước và tạo ra các phần khác của ứng dụng tại lớp giữa và lớp trình diễn. Các tài liệu liên quan đến các bài tập này có thể tìm thấy tại địa chỉ:
http://www.cs.wise.edu/~ dbbook
Nhớ lại Website Notown Records bạn đã làm trong Bài 6.6. Tiếp theo, bạn được yêu cầu để phát triển website này. Thiết kế các phần của website làm việc ở lớp giữa và lớp trình diễn, và kết hợp chương trình bạn viết trong Bài 6.6 để truy cập cơ sở dữ liệu.
- Tất cả người dùng đều bắt đầu ở một trang chung.
- Với mỗi hành động (action), người dùng cung cấp những thông tin đầu vào nào? Họ cung cấp nó như thế nào, bằng việc kích trên một liên kết hay thông qua một Form HTML .
- Thứ tự của các bước mà người dùng đi qua để đến một bản ghi? Biểu diễn dòng ứng dụng mức cao bằng việc chỉ ra cách thức mỗi hành động người dùng được quản lý.
Giành cho độc giả
Nhớ lại bài tập về công ty dược đã làm ở Bài 6.7 trong chương 6. Làm theo các bước trong Bài 7.7 để thiết kế ứng dụng và lớp trình diễn và hoàn thiện Website.
Giành cho độc giả
Nhớ lại bài tập về cơ sở dữ liệu của trường đại học đã làm trong Bài 8 ở chương 6. Làm theo các bước trong Bài 7 để thiết kế ứng dụng và lớp trình diễn và hoàn thiện Website.
Giành cho độc giả
Nhớ lại bài tập về đặt về máy bay đã làm trong Bài 6.9 ở chương 6. Làm theo các bước trong Bài 7.7 để thiết kế ứng dụng và lớp trình diễn và hoàn thiện Website.
Giành cho độc giả
TÀI LIỆU THAM KHẢO
Phiên bản mới nhất của các chuẩn được đề cập trong chương này có thể tìm trong website của tổ chức World Wide Web (www.w3.org). Nó chứa những liên kết tới những thông tin về HTML, cascading style sheets, XML, XSL, và nhiều thứ khác. Quyển sách của Hall giới thiệu chung về những công nghệ lập trình Web [357]: một điểm bắt đầu tốt để nghiên cứu trên Web là trang www.Webdeveloper.com. Có rất nhiều quyển giới thiệu về lập trình CGI, ví dụ [210, 198]. Trang JavaSoft (java.sun.com) là điểm bắt đầu tốt để nghiên cứu về servlets, JSP và tất cả các công nghệ khác liên quan đến Java. Quyển của Hunter[394] là những giới thiệu ban đầu hữu ích về Java servlets. Microsoft hỗ trợ Active Server Pages (ASP), một công nghệ có thể so sánh được với JSP. Nhiều hơn thông tin về ASP có thể được tìm thấy trên trang Microsoft Developer's Network (msdn.microsoft.com).
Có một địa chỉ rất tuyệt vời đề cập đến những ưu điểm của XML, ví dụ www.xml.com và www.ibm.com/xml, tại đây cũng có các liên kết tới các chuẩn khác. Có những quyển sách tốt đề cấp đến nhiều khía cạnh khác nhau của XML, ví dụ [195, 158. 597, 474. 381, 320]. Thông tin về UNICODE có thể được tìm thấy trong website http://www.imicode.org. Thông tin về JavaServer Pages và servlets có thể được tìm thấy tại java.sim.com, java.sun.com/products/jsp và Java.sun.com/products/servlet.