Trong chương 5, chúng ta đã nghiên cứu về các cấu trúc khác nhau của truy vấn SQL. Hệ quản trị cơ sở dữ liệu quan hệ thường có hỗ trợ ngôn ngữ SQL thông qua giao diện tương tác, và người dùng có thể nhập trực tiếp các câu lệnh SQL để thực hiện truy vấn dữ liệu. Với những yêu cầu đơn giản có thể thực hiện ngay bằng một câu lệnh SQL thì phương pháp này là tốt. Tuy nhiên trên thực tế ta thường gặp những yêu cầu phức tạp hơn vì thế ta có thể phải sử dụng ngôn ngữ lập trình mà SQL cung cấp. Ví dụ, chúng ta có thể muốn tích hợp một ứng dụng cơ sở dữ liệu với giao diện đồ hoạ của người sử dụng, hoặc chúng ta muốn tích hợp với các chương trình ứng dụng khác đang tồn tại.
Các ứng dụng dựa trên hệ quản trị cơ sở dữ liệu để quản lý dữ liệu chạy như những tiến trình riêng rẽ, những tiến trình này kết nối với hệ quản trị cơ sở dữ liệu để tương tác với nó. Ngay khi một kết nối được thành lập, các câu lệnh SQL có thể được sử dụng để thêm, xoá, và sửa dữ liệu. Các truy vấn SQL có thể được sử dụng để truy vấn những dữ liệu mong muốn, nhưng chúng ta cần phải làm một cầu nối giữa các ngôn ngữ lập trình như C, Java với dữ liệu truy vấn được từ cơ sở dữ liệu: Kết quả của một truy vấn cơ sở dữ liệu là một tập hợp hoặc là các bản ghi, nhưng Java không hỗ trợ kiểu dữ liệu này. Thiếu sót này được giải quyết thông qua các cấu trúc của SQL, cho phép các ứng dụng thao tác trên một tập hợp các bản ghi tại cùng một thời điểm.
Chúng tôi giới thiệu Embedded SQL, Dynamic SQL và con trỏ trong Phần 1. Embedded SQL cho phép chúng ta truy cập dữ liệu sử dụng các truy vấn SQL trong phần mã của chương trình (Phần 1.1); cùng với Dynamic SQL, chúng ta có thể tạo ra các truy vấn run-time (Phần 1.3). Con trỏ được sử dụng như cầu nối giữa giá trị của kết quả truy vấn và ngôn ngữ lập trình (Phần 1.2). Java là ngôn ngữ lập trình được sử dụng rất thông dụng để phát triển các ứng dụng Internet, truy cập tới DBMS từ Java được xem là một chủ đề quan trọng. Phần 2 sẽ tìm hiểu về JDBC, một công cụ cho phép chúng ta thực hiện các truy vấn SQL từ ngôn ngữ lập trình Java và sử dụng những kết quả trong ngôn ngữ lập trình Java. JDBC cung cấp nhiều lợi ích hơn là Embedded SQL hay Dynamic SQL, và hỗ trợ khả năng kết nối với một vài DBMS mà không cần biên dịch lại mã của chương trình. Phần 4 tìm hiểu về SQLJ, nó tương tự như những truy vấn SQL, nhưng nó dễ dàng để lập trình trong Java cùng với JDBC.
Thường thì việc viết chương trình ứng dụng trên máy chủ cơ sở dữ liệu mang lại nhiều lợi ích hơn là chỉ truy vấn dữ liệu và thực hiện các ứng dụng trong một tiến trình riêng rẽ nào đó. Phần 5 tìm hiểu về stored procedures, là phần chương trình có thể được lưu trữ và thực hiện trên máy chủ cơ sở dữ liệu. Chúng ta kết luận chương bằng việc xem xét ví dụ ứng dụng B&N trong Phần 6. Trong khi viết các ứng dụng cơ sở dữ liệu, chúng ta phải luôn ghi nhớ rằng các chương trình ứng dụng đang được chạy đồng thời. Khái niệm về giao dịch, giới thiệu trong Chương 1 đã nêu lên những ảnh hưởng của một chương trình ứng dụng đối với cơ sở dữ liệu. Một ứng dụng có thể được phép lựa chọn những đặc tính của giao dịch thông qua các câu lệnh SQL, để điều khiển những mức độ ảnh hưởng của nó tới những ứng dụng khác đang chạy đồng thời. Chúng ta sẽ đề cập đến khái niệm giao dịch nhiều lần trong chương này. Phần trình bày về các tính chất của giao dịch và những hỗ trợ của SQL với nó được đề cập đầy đủ trong Chương 16. Những ví dụ xuất hiện trong chương này có thể được tìm thấy tại địa chỉ:
http://www.cs.wise.edu/~ dbbook
Truy cập tới cơ sở dữ liệu từ các ứng dụng
Trong phần này, chúng ta tìm hiểu về cách thực hiện các câu lệnh SQL trong ngôn ngữ lập trình như C hoặc Java. Việc sử dụng các câu lệnh SQL trong các ngôn ngữ lập trình này được gọi là Embedded SQL. Những chi tiết của Embedded SQL cũng phụ thuộc vào ngôn ngữ lập trình, cú pháp của chúng có một chút thay đổi trong từng ngôn ngữ. Trước tiên chúng ta tìm hiểu phần cơ bản nhất của Embedded SQL trong Phần 1.1. Sau đó chúng ta tìm hiểu về con trỏ trong Phần 1.2. Chúng ta sẽ bàn và Dynamic SQL trong Phần 1.3.
Embedded SQL
Các câu lệnh SQL được nhúng trong ngôn ngữ lập trình rất dễ hiểu. Các câu lệnh SQL (ví dụ, không có phần khai báo biến) có thể được sử dụng bất cứ ở đâu mà chương trình yêu cầu. Các câu lệnh SQL phải được đánh dấu rõ ràng để bộ tiền xử lý có thể giải quyết chúng trước khi biên dịch chương trình trong ngôn ngữ lập trình. Bất kỳ một biến nào của chương trình được sử dụng như một tham số trong câu lệnh SQL cũng phải được khai báo trong SQL. Trong một số trường hợp, một số biến đặc biệt của ngôn ngữ lập trình phải được khai báo trong SQL.
Tuy nhiên, ở đây có hai sự rắc rối gặp phải. Đầu tiên, các kiểu dữ liệu được SQL chấp nhận có thể không được ngôn ngữ lập trình chấp nhận và ngược lại. Khó khăn này được giải quyết bằng việc chuyển đổi về các kiểu dữ liệu phù hợp trước khi đưa giá trị vào câu lệnh SQL. Rắc rối thứ hai là giá trị trả về của câu lệnh SQL thường là một tập hợp các bản ghi, và khó khăn này được giải quyết khi sử dụng con trỏ. (Xem phần 1.2. Các lệnh thực hiện với các bảng- là tập hợp các bản ghi).
Trong phần trình bày về Embedded SQL, chúng ta giả sử rằng ngôn ngữ lập trình là C. Sở dĩ phải chỉ rõ như vậy vì có sự khác nhau trong cú pháp câu lệnh SQL trong từng ngôn ngữ lập trình.
Khai báo biến và một số ngoại lệ
Các câu lệnh SQL có thể tham chiếu tới các biến mà ngôn ngữ lập trình đã định nghĩa. Vì thế, những biến của ngôn ngữ lập trình được quy định là phải có tiền tố (:) trong các câu lệnh SQL và được khai báo giữa các câu lệnh EXEC SQL BEGIN DECLARE SECTION và EXEC SQL END DECLARE SECTION. Những khai báo này tương tự như chúng ta nhìn thấy trong ngôn ngữ C và cũng như C, các biến được ngăn cách bởi dấu chấm phẩy. Ví dụ, chúng ta có thể khai báo các biến c_sname, c_sid, c_rating, và c_age (trong đó tiền tố c được sử dụng để nhấn mạnh đây là những biến của ngôn ngữ lập trình) như sau:
EXEC SQL BEGIN DECLARE SECTION
char c_sname[20];
long c_sid;
short c_rating;
f loat c_age;
EXEC SQL END DECLARE SECTION
Câu hỏi đầu tiên xuất hiện là các kiểu dữ liệu của SQL có phù hợp với các kiểu dữ liệu của C, vì chúng ta vừa khai báo một tập hợp các biến trong ngôn ngữ C và sẽ sử dụng nó trong câu lệnh SQL. Chuẩn SQL-92 định nghĩa các kiểu dữ liệu của mình tương thích với phần lớn ngôn ngữ lập trình đang tồn tại. Trong ví dụ của chúng ta, c_snamecó kiểu dữ liệu là CHARACTER(20) trong câu lệnh SQL, c_sid có kiểu dữ liệu là INTEGER, c_rating là SMALLINT và c_age là REAL.
Chúng ta cũng cần có một vài cách để SQL thông báo khi có lỗi xảy trong quá trình thực hiện nó. Chuẩn SQL-92 cung cấp hai biến để báo lỗi là SQLCODE và SQLSTATE. SQLCODE là bội số của hai và được định nghĩa để trả về một số giá trị âm khi mà có lỗi xảy ra. SQLSTATE được giới thiệu lần đầu tiên trong SQL-92, hỗ trợ các giá trị được định nghĩa trước ứng với lỗi cụ thể xảy ra. Một trong hai biến này phải được khai báo. Trong C, kiểu dữ liệu phù hợp của SQLCODE là long và SQLSTATE là char[6]. Trong chương này chúng ta giả sử rằng SQLSTATE đã được khai báo.
Các câu lệnh Embedded SQL
Tất cả các câu lệnh SQL nhúng trong ngôn ngữ lập trình phải được khai báo rõ ràng, chi tiết thế nào phụ thuộc vào từng ngôn ngữ lập trình; trong C, câu lệnh SQL phải có tiền tố là EXEC SQL. Một câu lệnh SQL có thể xuất hiện ở bất kỳ vị trí nào trong chương trình.
Ví dụ, câu lệnh Embedded SQL sau được sử dụng để thêm vào một dòng, giá trị của các cột là giá trị tương ứng của các biến.
EXEC SQL
INSERT INTO Sailors VALUES {:c_sname, :c_sid, :c_rating, :c_age);
Biến SQLSTATE nên được kiểm tra sau mỗi câu lệnh Embedded SQL để nhận được thông báo lỗi của câu lệnh (nếu có). SQL cung cấp lệnh WHENEVER để làm đơn giản công việc nhàm chán này.
EXEC SQL WHENEVER [SQLERROR|NOT FOUND][CONTINUE|GOTO stmt]
Con trỏ
Khó khăn nhất khi sử dụng các câu lệnh Embedded SQL trong các ngôn ngữ lập trình như C là sự không tương đồng xảy ra khi SQL thường thực hiện những phép toán trên tập hợp các bản ghi, trong khi đó ngôn ngữ lập trình như C không dễ dàng hỗ trợ kiểu dữ liệu này. Giải pháp được đề ra là phải cung cấp một cơ chế cho phép chúng ta truy cập tới nhiều dòng (bản ghi) dữ liệu trong quan hệ tại cùng một thời điểm.
Cơ chế này được gọi là con trỏ. Chúng ta có thể khai báo một con trỏ trên bất kỳ quan hệ nào hoặc trên bất kỳ một truy vấn SQL nào (bởi vì kết quả của một truy vấn cũng là tập hợp các dòng). Một khi con trỏ được khai báo, chúng ta có thể mở (open) nó; truy cập (fetch) tới dòng kế tiếp; di chuyển con trỏ (tới dòng tiếp theo, tới dòng sau dòng thứ n, tới dòng đầu tiên, tới dòng cuối cùng, etc., bằng việc xác định thêm một số biến cho lệnh FETCH); hoặc đóng con trỏ. Như vậy, một con trỏ sẽ cho phép chúng ta truy cập tới bất kỳ dòng nào trong bảng và đọc dữ liệu tại đó.
Định nghĩa và sử dụng con trỏ
Trong các ngôn ngữ lập trình, con trỏ giúp chúng ta thao tác với các dòng dữ liệu được lấy ra từ câu lệnh Embedded SQL.
- Chúng ta thường cần phải mở con trỏ nếu câu lệnh Embedded SQL là câu lệnh SELECT. Tuy nhiên, chúng ta có thể tránh mở nó nếu kết quả của câu lệnh SELECT chỉ là một dòng.
- Các câu lệnh INSERT, DELETE, và UPDATE thường không yêu cầu con trỏ, mặc dù một vài biến thể của DELETE và UPDATE có thể yêu cầu con trỏ.
Như trong ví dụ, chúng ta có thể tìm được tên và tuổi của một thuỷ thủ mà chỉ cần gán một giá trị cho một biến c_sid trong ngôn ngữ lập trình, như sau:
EXEC SQL SELECT S.sname, S.age
INTO :c_sname, :c_age
FROM Sailors S
WHERE S.sid = :c_sid;
Mệnh đề INTO cho phép chúng ta gán trị những cột của kết qủa câu lệnh SELECT (trong trường hợp kết quả này chỉ có duy nhất một dòng) cho hai biến c_name và c_age. Vì thế, chúng ta không cần phải sử dụng con trỏ trong trường hợp này. Nhưng điều gì sẽ xảy ra với truy vấn sau, yêu cầu đưa ra tên và tuổi của tất cả các thuỷ thủ có rating lớn hơn giá trị của biến c_minrating?
SELECT S.sname, S.age
FROM Sailors S
WHERE S.rating > :c_minrating;
Kết quả của truy vấn này là một tập hợp các dòng dữ liệu, không phải chỉ là một dòng như truy vấn trước. Nếu như chúng ta vẫn thực hiện như trên thì chúng ta sẽ thấy mệnh đề INTO không thực hiện được vì hai biến :c_sname, :c_age không thể cùng lúc lưu trữ nhiều giá trị. Giải pháp ở đây là chúng ta phải sử dụng một con trỏ:
DECLARE sinfo CURSOR FOR
SELECT S.sname, S.age
FROM Sailors S
WHERE S.rating > :c_minrating;
Đoạn mã này có thể thực hiện trong chương trình C, và khi chạy chương trình, một con trỏ sinfo được định nghĩa. Sau đó, chúng ta có thể mở con trỏ này:
OPEN sinfo;
Khi con trỏ được mở, nó trỏ tới dòng đầu tiên của kết quả truy vấn. Chúng ta có thể sử dụng lệnh FETCH để gán giá trị dòng đầu tiên này vào các biến của chương trình:
FETCH sinfo INTO :c_sname, :c_age;
Khi câu lệnh này thực hiện xong, con trỏ sẽ trỏ tới dòng kế tiếp và các giá trị của các cột được gán vào những biến tương ứng của chương trình. Bằng việc thực hiện lặp câu lệnh FETCH (giả sử, sử dụng vòng lặp While trong ngôn ngữ C), chúng ta có thể đọc tất cả các dòng trong kết quả truy vấn, từng dòng một.
Khi chúng ta làm việc xong với một con trỏ nào đó, chúng ta có thể đóng nó lại:
CLOSE sinfo;
Chúng ta cũng có thể mở lại nó khi chúng ta cần, và giá trị của :cminratingtrong truy vấn SQL sẽ vẫn là giá trị của biến c_minrating ở thời điểm trước.
Các thuộc tính của con trỏ
Cấu trúc chung của một con trỏ là:
DECLARE cursorname [INSENSITIVE] [SCROLL] CURSOR
[ WITH HOLD]
FOR some query
[ORDER BY order-item-list ]
[| FOR UPDATE ]
Một con trỏ nào đó có thể được khai báo là chỉ đọc (FOR READ ONLY) hoặc nó có thể là một con trỏ áp dụng trên một quan hệ hoặc một khung nhìn có khả năng cập nhật (FOR UPDATE). Nếu con trỏ có khả năng cập nhật, những biến thể của lệnh UPDATE và DELETE sẽ cho phép chúng ta cập nhật hoặc xoá dòng dữ liệu mà con trỏ đang trỏ tới. Ví dụ, nếu .sinfo là một con trỏ có khả năng cập nhật và đang được mở, chúng ta có thể thực hiện câu lệnh sau:
UPDATE Sailors S
SET S.rating = S.rating - 1
WHERE CURRENT of sinfo;
Câu lệnh Embedded SQL này sẽ thay đổi giá trị rating của dòng mà con trỏ sinfo đang trỏ tới, tương tự, chúng ta có thể xoá dòng này bằng lệnh:
DELETE Sailors S
WHERE CURRENT of sinfo;
Mặc định, con trỏ sẽ ở chế độ có thể cập nhật được, trừ những con trỏ scrollable hoặc insensitive (xem phần sau), trong những trường hợp này mặc định con trỏ ở chế độ chỉ đọc (read only).
Nếu từ khoá SCROLL được chỉ ra, con trỏ sẽ là con trỏ có khả năng cuộn, có nghĩa là lệnh FETCH có thể được sử dụng để xác định con trỏ này một cách linh hoạt hơn; trong khi đó lệnh FETCH cơ bản chỉ cho phép con trỏ truy cập đến dòng tiếp theo.
Nếu từ khoá INSENSITIVE được chỉ ra, con trỏ được đối xử giống như nó đang được duyệt trên một bản sao của một tập các dòng kết quả. Mặt khác, các giao dịch đang thực thi có thể sửa những dòng dữ liệu này. Ví dụ, trong khi chúng ta đang đọc dữ liệu sử dụng con trỏ sinfo, đồng thời có thể có một giao dịch khác sửa giá trị rating trong quan hệ Sailor bằng lệnh:
UPDATE Sailors S
SET S.rating = S.rating – 1
Xem xét một dòng Sailor trong hai trường hợp: (1) nó chưa được đọc (fetch), và (2) giá trị rating ban đầu sẽ gặp một điều kiện nào đó trong mệnh đề WHERE của một truy vấn có con trỏ sinfo, nhưng giá trị rating mới thì không. Khi chúng ta fetch một dòng nào đó của Sailor, nếu INSENTITIVE được xác định, cách thực hiện giống như là tất cả các câu trả lời đã được tính toán và lưu trữ khi con trỏ sinfo đã được mở; vì thế, lệnh update không ảnh hưởng tới những dòng đã fetch bằng con trỏ sinfo nếu nó được thực hiện sau khi sinfo được mở. Nếu không có từ khoá INSENTITIVE, việc thực hiện sẽ phụ thuộc vào tình trạng này.
Một con trỏ là Holdable cursor khi nó sử dụng mệnh đề WITH HOLD, và nó không được đóng lại khi một giao dịch đã hoàn thành. Mục đích của con trỏ loại này xuất phát từ một thực tế rằng có những giao dịch dài- giao dịch cần truy cập (có thể thay đổi giá trị) một số lượng lớn các dòng trong một bảng. Nếu vì một lý do nào đó giao dịch này bị huỷ bỏ, hệ thống có thể phải làm lại rất nhiều công việc khi giao dịch đó được khởi động lại. Ngay cả khi giao dịch đó không bị huỷ, những khoá của nó được nắm giữ trong một thời gian dài và vì thế khả năng xử lý đồng thời của hệ thống sẽ giảm. Một lựa chọn ở đây là nên chia nhỏ giao dịch này thành những giao dịch nhỏ hơn, nhưng việc ghi nhớ vị trí trong bảng giữa những giao dịch (và những chi tiết khác) rất phức tạp và dễ gặp lỗi. Việc cho phép một chương trình ứng dụng có thể kết thúc một giao dịch mà nó đã tạo ra, trong khi duy trì việc điều khiển trên bảng tích cực (ví dụ là con trỏ) sẽ giải quyết vấn đề này: Một ứng dụng có thể kết thúc giao dịch của nó và khởi tạo một giao dịch mới và bằng cách lưu lại những thay đổi nó đã làm tới mức đó.
Cuối cùng, các lệnh FETCH truy vấn các dòng theo thứ tự nào? Thông thường thứ tự này không được xác định, nhưng mệnh đề ORDER BY có thể được sử dụng nếu muốn việc truy cập sẽ theo thứ tự. Ghi nhớ rằng những cột được đề cập trong mệnh đề ORDER BY không thể được cập nhật qua con trỏ dạng này.
Order-item-list là một danh sách của order-items; một order-item là tên của một cột, theo sau có thể là một trong hai từ khoá ASC hoặc DESC. Tất cả các cột được đề cập trong mệnh đề ORDER BY cũng phải xuất hiện trong select-list của truy vấn này. Những từ khoá ASC hoặc DESC phải theo sau cột cần sắp xếp- thứ tự tăng dần (ASC) hoặc giảm dần (DESC), chế độ mặc định là ASC. Mệnh đề này phải được đứng ở vị trí cuối cùng trong truy vấn.
Xem xét truy vấn được bàn trong Phần 5.5.1, và kết quả được chỉ tra trong Hình 5.13. Giả sử rằng một con trỏ được mở trên truy vấn này, cùng với mệnh đề:
ORDER BY minage ASC, rating DESC
Kết quả của truy vấn này đầu tiên được sắp xếp tăng dần theo minage, và nếu có vài dòng có cùng giá trị minage, những dòng này sẽ được sắp xếp giảm dần theo rating. Con trỏ này sẽ fetch tới các dòng theo thứ tự được chỉ ra trong Hình 6.1.

Dynamic SQL
Giả sử một ứng dụng cần truy cập dữ liệu từ một DBMS nào đó. Khi đó, ứng dụng nhận những lệnh từ người dùng, dựa trên yêu cầu của người dùng để tự sinh ra những câu lệnh SQL phù hợp để truy cập dữ liệu cần thiết. Trong những trường hợp này, chúng ta có thể không dự đoán được những câu lệnh SQL nào cần để thực hiện, mặc dù có một số thuật toán chỉ ra cách mà ứng dụng có thể xây dựng những câu lệnh SQL cần thiết khi có một yêu cầu người dùng đưa vào.
SQL cung cấp một vài tiện ích để đối mặt với tình trạng này; nó được biết đến như là Dynamic SQL. Chúng tôi cung cấp hai câu lệnh chính, PREPARE và EXECUTE thông qua một ví dụ đơn giản:
char c_sqlstring[] = {"DELETE FROM Sailors WHERE rating>5"};
EXEC SQL PREPARE readytogo FROM :c_sqlstring;
EXEC SQL EXECUTE readytogo;
Câu lệnh đầu tiên khai báo một biến C là c_sqlstring và khởi tạo giá trị của nó, giá trị đó là một câu lệnh SQL. Câu lệnh thứ hai nhằm phân tích cú pháp và biên dịch xâu ký tự này thành một câu lệnh SQL, và gán nó vào biến readytogo. (Vì readytogo là một biến SQL, chỉ giống như là tên của một con trỏ, nên nó không cần phải được định vị bằng dấu ‘:’ ở đằng trước). Câu lệnh thứ ba sẽ thực hiện câu lệnh SQL này.
Có nhiều trường hợp yêu cầu được sử dụng Dynamic SQL. Tuy nhiên, ghi nhớ rằng việc chuẩn bị của một câu lệnh Dynamic SQL diễn ra ngay tại thời điểm chạy chương trình (run-time). Những lệnh Embedded SQL có thể được chuẩn bị ở thời điểm biên dịch và sau đó thực hiện như chúng ta thường mong muốn. Vì thế, bạn nên hạn chế sử dụng Dynamic SQL, chỉ sử dụng nó khi nào thực sự cần thiết. Có rất nhiều vấn đề liên quan đến Dynamic SQL, nhưng ở đây chúng ta không bàn nhiều về nó.
Giới thiệu về JDBC
ODBC và JDBC là viết tắt của Open DataBase Connectivity và Java DataBase Connectivity. Cả ODBC và JDBC đều khai thác những khả năng của cơ sở dữ liệu theo một cách thức đã được chuẩn hoá thông qua Application Programming Interface (API). Khác với Embedded SQL, ODBC và JDBC cho phép một thực hiện có thể truy xuất tới các DBMS khác nhau mà không cần biên dịch lại. Thêm nữa, sử dụng DBMS và JDBC, một ứng dụng nào đó có thể truy xuất không chỉ một DBMS mà nhiều DBMS khác nhau đồng thời.
ODBC và JDBC có được khả năng linh động ở mức thực thi bằng việc bổ sung thêm một lớp gián tiếp. Tất cả các thao tác trực tiếp với một DBMS xác định nào đó được thực hiện thông qua một DBMS-driver. Một driver là một chương trình phần mềm xử lý các yêu cầu của ODBC hoặc JDBC. Những driver phù hợp được đăng ký với Driver Manager.
Một điểm thú vị cần ghi nhớ là một driver nào đó không nhất thiết phải tương tác với một DBMS hiểu ngôn ngữ SQL. Driver có khả năng chuyển đổi những câu lệnh SQL từ chương trình ứng dụng thành những câu lệnh tương đương mà DBMS hiểu được. Vì thế, trong phần còn lại của mục này, chúng tôi coi một hệ thống con lưu trữ dữ liệu tương ứng với một driver nào đó như là một nguồn dữ liệu (data source).
Một ứng dụng nào tương tác cùng với nguồn dữ liệu thông qua ODBC hoặc JDBC sẽ lựa chọn một nguồn dữ liệu, tự động tải driver tương ứng và thành lập một kết nối với nguồn dữ liệu đó. Số lượng các kết nối được mở là không giới hạn, và một ứng dụng nào đó có thể mở một vài kết nối tới các nguồn dữ liệu khác nhau. Mỗi một kết nối có các giao dịch của nó; ở đây, một kết nối chỉ có thể nhìn thấy những thay đổi của một kết khác khi nó đã hoàn thành. Trong khi một kết nối nào đó đang mở, giao dịch được thực hiện bằng việc gửi đi câu lệnh SQL, lấy kết quả, xử lý lỗi và cuối cùng là hoàn thành (commit) hay là quay trở lại trạng thái ban đầu (roll back) của cơ sở dữ liệu trước thời điểm thực hiện giao dịch này. Sau đó, ứng dụng sẽ ngắt kết nối với nguồn dữ liệu để ngừng việc tương tác.
Trong phần còn lại của chương này, chúng ta sẽ tập trung tìm hiểu về JDBC.
JDBC Drivers: Nguồn cập nhật nhất của JDBC drivers là Sun JDBC Driver ở trang:
http://industry.java.sun.com/products/jdbc/drivers
JDBC drivers có thể dùng được cho tất cả các hệ thống cơ sở dữ liệu.
Kiến trúc
Kiến trúc của JDBC có bốn thành phần chính: ứng dụng, bộ quản lý driver, một vài nguồn dữ liệu riêng của cácdriver, và các nguồn dữ liệu tương ứng.
Một ứng dụng khởi tạo và ngắt một kết nối với một nguồn dữ liệu nào đó. Nó thiết đặt những ranh giới giao dịch, gửi đi những câu lệnh SQL, và truy vấn tới những kết quả- tất cả thông qua một giao diện được định nghĩa tốt như JDBC API. Mục đích chính của bộ quản lý driver là tải các drivers của JDBC và đưa các hàm JDBC gọi từ ứng dụng tới một driver phù hợp. Bộ quản lý drivers cũng quản lý sự khởi động của JDBC và các thông tin mà ứng dụng gọi và có thể ghi lại tất cả các hàm được gọi. Thêm nữa, bộ quản lý drivers thực hiện một số việc kiểm tra lỗi ban đầu. Một driver thành lập một kết nối với nguồn dữ liệu. Sau đó gửi các yêu cầu và trả lại kết quả của yêu cầu, driver này chuyển đổi dữ liệu, những định dạng lỗi, và những mã lỗi từ dạng nào đó của nguồn dữ liệu vào JDBC chuẩn. Nguồn dữ liệu này xử lý các lệnh từ driver và trả về kết quả.
Phụ thuộc vào vị trí tương quan của nguồn dữ liệu và ứng dụng, có một vài kịch bản kết nối được lập. Các drivers trong JDBC được chia làm bốn loại phụ thuộc vào mối quan hệ giữa ứng dụng và nguồn dữ liệu.
Loại I: Bridges: Loại này sẽ chuyển đổi các hàm của JDBC vào các hàm của API không native với DBMS. Ví dụ JDBC-ODBC bridge; một ứng dụng nào đó có thể sử dụng JDBC để truy cập một nguồn dữ liệu của ODBC. Ứng dụng này tải chỉ một driver, một bridge. Bridges có ưu điểm là dễ đặt một ứng dụng lên trên phần cài đặt đang tồn tại, không cần cài đặt thêm các drivers mới. Nhưng việc sử dụng bridge gặp một số nhược điểm. Sự tăng lên của số lượng các lớp giữa nguồn dữ liệu và ứng dụng làm ảnh hưởng đến quá trình thực hiện. Thêm nữa, người dùng bị hạn chế những chức năng mà ODBC driver hỗ trợ.
Loại II:Trực tiếp chuyển tới Native API thông qua Non-Java Driver: Kiểu này của driver sẽ thực hiện chuyển các hàm JDBC trực tiếp vào API của một nguồn dữ liệu xác định. Driver này thường được viết sử dụng ngôn ngữ C kết hợp với Java; nó tự liên kết và xác định nguồn dữ liệu. Kiến trúc này thực hiện hiệu quả hơn đáng kể so với JDBC-ODBC bridge. Một bất lợi ở đây là driver của cơ sở dữ liệu cần được cài đặt trên mỗi máy chạy ứng dụng.
Loại III: Network Bridges: Gửi các câu lệnh trên Network tới một máy chủ trung gian giao tiếp được với data source. Chỉ cần JDBC driver nhỏ trên mỗi máy trạm, vì nó chỉ có nhiệm vụ gửi những câu lệnh SQL tới máy chủ trung gian. Máy chủ trung gian sau đó có thể sử dụng Loại II JDBC driver để kết nối với nguồn dữ liệu.
Loại IV:Trực tiếp chuyển tới Native API thông qua Java Driver: Thay vì gọi DBMS API trực tiếp, driver kết nối với DBMS thông qua Java sockets. Trong trường hợp này, driver phía máy trạm được viết bằng Java, nhưng nó là DBMS xác định. Giải pháp này không yêu cầu một lớp trung gian và từ đó tất cả việc thực hiện do Java đảm nhiệm, quá trình thực hiện thường là tốt.
Các lớp và giao diện JDBC
JDBC là một tập hợp các lớp và các giao diện có thể truy cập đến cơ sở dữ liệu từ các chương trình viết bằng ngôn ngữ lập trình Java. Nó bao gồm các phương pháp kết nối tới nguồn dữ liệu từ xa, các câu lệnh SQL đang thực thi, tập kết quả của các câu lệnh SQL đang được kiểm tra, quản lý các giao dịch. Các lớp và các giao diện là một phần của gói Java.sql. Vì thế, tất cả các đoạn mã nguồn trong phần còn lại của mục này nên có câu lệnh import java.sql.* ở đầu chương trình, chúng ta sẽ bỏ qua câu lệnh này trong phần còn lại của mục này. JDBC 2.0 cũng bao gồm gói javax.sql, gói không bắt buộc của JDBC. Khi gói javax.sql được thêm vào, khả năng bể kết nối và giao diện Rowset sẽ được bổ sung. Chúng ta sẽ bàn đến bể kết nối trong Phần 6.3.2, và giao diện ResultSet trong Phần 6.3.4.
Bây giờ, chúng ta minh họa các bước phải làm để gửi đi một truy vấn tới một nguồn dữ liệu và truy cập tới các kết quả trả về.
Quản lý JDBC Driver
Trong JDBC, các driver của nguồn dữ liệu được lớp Drivermanager quản lý, nó chứa tất cả các driver đã được tải lên. Lớp Drivermanager bao gồm các cách thức registerDriver, deregisterDriver, và getDrivers để có thể linh động bổ sung hoặc xoá các driver. Bước đầu tiên khi kết nối với nguồn dữ liệu là tải JDBC driver tương ứng. Bước này được hoàn thành bằng việc sử dụng cơ chế của Java hỗ trợ việc tải các lớp lên một cách linh động.
Ví dụ sau cho phép tải một JDBC driver:
Class.forName(''oracle/jdbc.driver.OracleDriver'');
Có hai cách khác nhau để đăng ký một driver. Chúng ta có thể thêm một driver sử dụng câu lệnh -Djdbc.drivers=oracle/jdbc.driver ở một dòng lệnh khi chúng ta bắt đầu chương trình Java.
Sau khi đăng ký driver, chúng ta có thể kết nối tới nguồn dữ liệu.
Các kết nối
Một phiên làm việc cùng với một nguồn dữ liệu nào đó được bắt đầu thông qua việc tạo một đối tượng Connection. Một kết nối nào đó xác nhận một phiên làm việc cùng với một nguồn dữ liệu; nhiều kết nối trong cùng một chương trình Java có thể tham chiếu tới các nguồn dữ liệu khác nhau hoặc cùng một nguồn dữ liệu. Các kết nối được xác định thông qua một JDBC URL, một URL sử dụng giao thức jdbc. Vì thế một URL có dạng:
jdbc:<subprotocol>:<otherParameters>
Các kết nối JDBC: Hãy nhớ đóng các kết nối tới nguồn dữ liệu và trả lại những kết nối có khả năng chia sẻ cho bể kết nối. Các hệ thống cơ sở dữ liệu chỉ cho phép một số lượng hạn chế những tài nguyên có thể cho các kết nối, và các kết nối “mồ côi” có thể chỉ được phát hiện khi time-out— và trong khi hệ thống cơ sở dữ liệu đang đợi một kết nối time-out, các nguồn tài nguyên mà những kết nối “mồ côi” sử dụng sẽ bị lãng phí.
Đoạn mã chương trình ví dụ thành lập một kết nối tới một cơ sở dữ liệu Oracle với giả thiết là xâu userid và password được thiết lập giá trị rỗng.
String url = "jdbc:oracle:www.bookstore.com:3083"
Connection connection;
try{
Connection connection =
DriverManager.getConnection(url,userId,password);
}
catch(SQLException excpt) {
System.out.println(excpt.getMessage());
return;
}Thành lập một kết nối với JDBC
Trong JDBC, các kết nối có thể có các thuộc tính khác nhau. Ví dụ, một kết nối có thể định rõ đặc tính “granularity” (nguyên tử) của giao dịch. Nếu tính chất tự động hoàn thành được thiết đặt cho một kết nối, thì mỗi một câu lệnh SQL được coi như là một giao dịch chứa chính bản thân câu lệnh SQL đó. Nếu tính chất tự động hoàn thành này tắt, thì một loạt các câu lệnh được soạn thảo cho một giao dịch có thể được hoàn tất sử dụng phương thức commit() của lớp Connection, hoặc huỷ bỏ nếu sử dụng phương thức rollback(). Một lớp Connection có các phương thức để thiết đặt chế độ tự động hoàn thành (Connection. setAutoCommit) và để gọi lại chế độ tự động hoàn thành (getAutoCommit). Những phương thức sau là một phần của giao diện Connection cho phép thiết lập và lấy các thuộc tính khác nhau:
- public int getTransactionIsolation() throws SQLException và
public void setTransactionIsolation(int l) throws SQLException.
Hai hàm này sẽ lấy và thiết đặt mức cô lập hiện tại cho các giao dịch trong kết nối hiện tại. Có tất cả năm mức cô lập (chi tiết sẽ trình bày trong Phần 16.6) có thể được sử dụng, và đối số l có thể được thiết đặt như sau:
- TRANSACTION_NONE
- TRANSACTION_READ_UNCOMMITTED
- TRANSACTION_READ_COMMITTED
- TRANSACTION_REPEATABLE_READ
- TRANSACTION_SERIALIZABLE
- public boolean getReadOnly() throws SQLException và
public void setReadOnly(boolean readOnly) throws SQLException.
Hai hàm này cho phép người dùng chỉ định những giao dịch được thực hiện thông qua kết nối này là chỉ đọc.
- public boolean isClosed() throws SQLException.
Kiểm tra kết nối hiện tại đã được đóng chưa.
- setAutoCommit and get AutoCommit.
Chúng ta đã bàn đến hai hàm này.
Việc thành lập một kết nối tới một nguồn dữ liệu là một phép toán đắt giá vì nó bao gồm nhiều bước, như là thành lập một kết nối mạng tới nguồn dữ liệu, xác thực quyền, và phân chia các tài nguyên ví dụ như bộ nhớ. Trong trường hợp một ứng dụng nào đó lập nhiều kết nối khác nhau từ các phần khác nhau (như một Web server), các kết nối thường được “dùng chung” (pool) để tránh hiện tượng overhead. Một bể kết nối (connection pool) là một tập hợp các kết nối đã được kết nối với một nguồn dữ liệu nào đó. Bất cứ khi nào một kết nối được yêu cầu, một trong số các kết nối trong bể được sử dụng thay vì việc phải tạo ra một kết nối mới tới nguồn dữ liệu đó. Bể kết nối có thể được quản lý thủ công trong quá trình lập trình chương trình ứng dụng, hoặc có thể sử dụng gói javax.sql, gói này cung cấp các tính năng của bể kết nối và cho phép chúng ta thiết đặt lại các tham số khác nhau, như là dung lượng của bể, tỷ lệ co giãn kích thước bể. Hầu hết các ứng dụng (Phần 7.7.2) sử dụng gói javax.sql.
Thực thi các câu lệnh SQL
Bây giờ chúng ta sẽ bàn đến cách thức tạo và thực hiện các câu lệnh SQL sử dụng JDBC. Trong các đoạn mã lệnh ví dụ của phần này, chúng ta giả sử rằng chúng ta có một đối tượng Connection có tên là con. JDBC hỗ trợ ba cách khác nhau để thực thi các câu lệnh:Statement, PreparedStatement, và CallableStatement. Lớp Statement là lớp cơ sở của hai lớp còn lại. Nó cho phép chúng ta truy vấn tới nguồn dữ liệu. Chúng ta sẽ tìm hiểu về lớp PreparedStatement ở đây và lớp CallableStatement trong Phần 6.5 khi chúng ta tìm hiểu về Stored procedures. Lớp PreparedStatement sinh ra một cách linh động các câu lệnh SQL đã được biên dịch-những câu lệnh có thể đã được sử dụng một vài lần; những câu lệnh SQL này có thể có các tham biến, nhưng cấu trúc của chúng được cố định khi một đối tượng PreparedStatement được tạo. Xem xét một ví dụ sử dụng đối tượng PreparedStatement chỉ ra trong Hình 6.3. Một truy vấn SQL được xác định là một xâu truy vấn, nhưng sử dụng dấu “?” cho các giá trị của các biến, những giá trị sẽ được thiết lập sau khi sử dụng phương thức setString, setFloat, và setInt. Ký hiệu thay thế “?” có thể được sử dụng bất kỳ đâu trong các câu lệnh SQL, nơi mà chúng ta muốn sẽ được thay thế bằng một giá trị. Ví dụ, ký hiệu thay thế có thể xuất hiện trong mệnh đề WHERE (ví dụ, ‘WHERE author=?’), hoặc trong các câu lệnh UPDATE và INSERT. Phương thức setString là một cách để thiết đặt giá trị cho một biến; những phương thức tương tự có thể thiết đặt cho các kiểu dữ liệu như int, float, và date. Chúng ta nên sử dụng clearParameters() trước khi thiết lập các biến giá trị để xoá đi bất kỳ một giá trị cũ nào.
//initial quantity is always zero
String sql = “INSERT INTO Books VALUES(?, ?, ?, ?, 0, ?)”;
PreparedStatement pstmt = con.prepareStatement(sql);
//now instantiate the parameters with values
//assume that isbn, title, etc. are Java variables that
//contain the values to be inserted
pstmt.clearParameters();
pstint.setString(l,isbn);
pstmt.setString(2,title):
pstmt.setString(3,author);
pstmt.setFloat(5,price);
pstmt.setlnt(6,year);
int numRows = pstmt.executeUpdate();Câu lệnh SQL Update sử dụng một đối tượng PreparedStatement
Có những cách khác nhau để gửi một truy vấn tới nguồn dữ liệu. Ví dụ, chúng ta đã sử dụng lệnh executeUpdate, nó được sử dụng nếu chúng ta biết rằng câu lệnh SQL đó không trả về bất kỳ bản ghi nào (các lệnh SQL: UPDATE, INSERT, ALTER, và DELETE). Phương thức executeUpdate trả về một số nguyên chỉ ra số dòng đã được sửa bằng lệnh SQL; trả về giá trị 0 nếu câu lệnh thực hiện thành công mà không sửa bất kỳ dòng nào. Phương thức executeQuery được sử dụng nếu câu lệnh SQL trả về dữ liệu, ví dụ như một truy vấn SELECT thông thường nào đó. JDBC có cơ chế con trỏ có dạng là một đối tượng ResultSet, phần này chúng ta sẽ bàn đến sau. Phương thức thực hiện này phổ biến hơn việc sử dụng executeQuery và executeUpdate; phần cuối chương này cung cấp nhiều thông tin hơn về con trỏ.
ResultSets
Như đã trình bày trong những phần trước, một câu lệnh executeQuery trả về một đối tượng ResultSet, nó tương tự như một con trỏ. Những con trỏ ResultSet trong JDBC 2.0 rất hiệu quả, chúng cho phép đi lên, đi xuống, cuộn tròn để thực hiện các thao tác với bản ghi.
Trong dạng cơ bản nhất, đối tượng ResultSet cho phép chúng ta đọc một dòng của kết quả truy vấn ở một thời điểm. Ban đầu, đối tượng ResultSet được định vị ở trước dòng đầu tiên, và chúng ta phải truy vấn đề dòng đầu tiên sử dụng phương thức next(). Phương thức next trả về giá trị false nếu không còn dòng nào trong kết quả truy vấn, và true nếu ngược lại. Đoạn mã lệnh minh hoạ cách sử dụng cơ bản của đối tượng ResultSet.
ResultSet rs=stmt.executeQuery(sqlQuery);
//rs is now a cursor
//first call to rs.next() moves to the first record
//rs.next() moves to the next row
String sqlQuery;
ResultSet rs = stmt.executeQuery(sqlQuery)
while (rs.next()) {
//process the data
}Sử dụng một đối tượng ResultSet
Trong khi next() cho phép chúng ta truy vấn đến dòng tiếp theo trong kết quả truy vấn, chúng ta cũng có thể di chuyển đến các dòng dữ liệu theo các cách khác:
- previous() trở về một dòng trước đó
- absolute(int num) di chuyển đến dòng xác định có vị trí là num.
- relative(int num) đi lên hoặc đi xuống (nếu num là số âm) so với vị trí hiện tại, relative(-1) có cùng tác dụng như là previous().
- first() di chuyển đến dòng đầu tiên, và last() di chuyển đến dòng cuối cùng.
So sánh các kiểu dữ liệu của Java và SQL
Xem xét sự tương tác giữa một ứng dụng với một nguồn dữ liệu, những vấn đề chúng ta bắt gặp trong môi trường Embedded SQL (ví dụ, trao đổi thông tin giữa một ứng dụng và nguồn dữ liệu thông qua các biến chia sẻ) tăng lên. Để giải quyết những vấn đề này, JDBC cung cấp các loại dữ liệu đặc biệt và xác định mối quan hệ giữa chúng để làm chúng tương ứng với các kiểu dữ liệu SQL. Hình 2 chỉ ra các phương thức truy cập trong một đối tượng ResultSet cho các kiểu dữ liệu SQL chung nhất. Với những phương pháp truy cập này, chúng ta có thể truy cập tới những giá trị dòng hiện tại của kết quả truy vấn. Có hai dạng của mỗi phương thức truy cập: một là truy cập đến giá trị thông qua chỉ số cột, bắt đầu là 1, và hai là truy cập thông qua tên của cột. Ví dụ sau chỉ ra cách truy cập tới các trường của dòng ResultSet hiện tại sử dụng các phương thức truy cập.
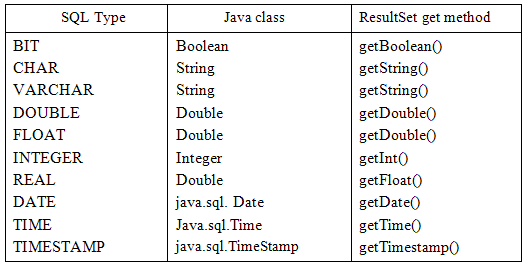
ResultSet rs=stmt.executeQuery(sqlQuery);
String sqlQuery;
ResultSet rs = stint.executeQuery(sqlQuery)
while (rs.next()){
isbn = rs.getString(1):
title = rs.getString(“TITLE”);
//process isbn and title
}
Cảnh báo lỗi
Tương tự như biến SQLSTATE, hầu hết các phương thức trong java.sql có thể sử dụng SQLException để nhắc nhở nếu một lỗi nào đó xảy ra. Lời nhắc đó nằm trong SQLState, đó là một xâu ký tự nào biểu diễn lỗi này (ví dụ, một câu chứa một mã lỗi SQL). Để thêm vào phương thức getMessage() được thừa kế từ Throwable, SQLException có hai phương thức nữa để cung cấp thêm thông tin, và một phương thức để lấy những lời nhắc bổ sung:
- public String getSQLState() trả về SQLState xác định dựa trên SQL:1999, như đã trình bày trong Phần 6.1.1.
- public int getErrorCode() trả về một mã lỗi.
- public SQLException getNextException() trả về lời nhắc nhở tiếp theo trong một chuỗi những lời nhắc liên quan đến đối tượng SQLException hiện tại.
Một SQLWarning là một lớp con của SQLException. Những cảnh báo này không khắt khe như những thông báo lỗi. Các đối tượng Connection, Statement, và ResultSet đều có chung một phương thức getWarning() để truy cập tới những lời nhắc SQL. Chúng ta có thể xoá những lời cảnh báo thông qua clearWarnings(). Những đối tượng Statement tự động xoá đi những cảnh báo khi nó thực hiện sang câu lệnh tiếp theo; Các đối tượng ResultSet xóa những lời cảnh báo ngay khi một bộ dữ liệu mới được truy cập. Hình 6.6 là một ví dụ mã lệnh giúp ta thu được các SQLWarnings.
try {
stmt = con.createStatement();
warning = con.getWarnings();
while( warning != null) {
// handlesQLWarnings //code to process warning
warning = warning.getNextWarning(); //get next warning
}
con.clear Warnings();
stmt.executeUpdate(queryString);
warning = stmt.getWarnings();
while( warning!= null) {
//handleSQLWarnings //code to process warning
warning = warning.getNextWarning(); //get next warning
}
} // end try
catch ( SQLException SQLe) {
// code to handle exception
} // end catchXử lý JDBC Warnings và Exceptions
Kiểm tra cơ sở dữ liệu hệ thống
Chúng ta có thể sử dụng đối tượng DatabaseMetaData để lấy những thông tin về hệ thống cơ sở dữ liệu. Ví du, đoạn mã sau chỉ ra cách lấy ra tên và driver version của JDBC driver:
DatabaseMetaData md = con.getMetaData();
Systein.out.println("Driver Information:");
System.out.println("Name:" + md.getDriverName()
+ "; version:" + md.getDriverVersion());
Đối tượng DatabaseMetaData có nhiều phương thức (trong JDBC 2.0, có chính xác là 134); chúng ta liệt kê một số phương thức ở đây:
- public ResultSet getCatalogs() throws SQLException. Hàm này trả về một ResultSet có thể được sử dụng lặp đi lặp lại trên tất cả các quan hệ. Các hàm getIndexInfo() và getTables() làm việc tương tự.
- public int getMaxConnectionsO throws SQLException. Hàm này trả về số lượng lớn nhất các kết nối có thể.
Chúng ta sẽ tổng kết những nội dung đã bàn về JDBC thông qua một đoạn mã lệnh trong Hình 6.7, nó sẽ kiểm tra tất cả các database metadata.
DatabaseMetaData dmd = con.getMetaData();
ResultSet tablesRS = dmd.getTables(null,null,null,null);
string tableName;
while(tablesRS.next()) {
tableName = tablesRS.getString("TABLE_NAME");
//print out the attributes of this table
System.out.println("The attributes of table "
+ tableName + " are:");
ResultSet columnsRS=dmd.getColuins(null,null,tableName,null):
while (columnsRS.next()) {
System.out.print(columnsRS.getString("COLUMN_NAME")+ “ ” );
}
//print out the primary keys of this table
System.out.println("The keys of table "+tableName + " are:");
ResultSet keysRS = dmd.getPrimaryKeys(null,null,tableName);
while (keysRS.next()) {
System.out.print(keysRS.getString("COLUMN_NAME") + " ");
}
}Đưa ra những thông tin về một nguồn dữ liệu
SQLJ
SQLJ (viết tắt của 'SQL-Java') đã được SQLJ Group phát triển, một nhóm nhà cung cấp cơ sở dữ liệu và Sun. SQLJ đã được phát triển để tạo ra thêm một cách tạo ra các truy vấn trong JDBC một cách linh hoạt. Vì thế nó có liên quan mật thiết với Embedded SQL. Không như JDBC, có những truy vấn SQL bán-tĩnh cho phép trình biên dịch thực hiện những kiểm tra cú pháp SQL, những kiểm tra đánh giá sự tương thích giữa các biến trên máy trạm với các thuộc tính SQL tương ứng và sự nhất quán của các truy vấn cùng với lược đồ cơ sở dữ liệu – các bảng, các thuộc tính, các khung nhìn, và các thủ tục- tất cả được kiểm tra cùng lúc khi biên dịch. Ví dụ, cả SQLJ và Embedded SQL, các biến ở trong ngôn ngữ lập trình luôn được gán tĩnh cho các tham số tương ứng, ngược lại trong JDBC, chúng ta cần phân tách các câu lệnh để gán mỗi biến cho một tham số và truy cập kết quả. Ví dụ, câu lệnh SQLJ sau đây sẽ gán các biến trong ngôn ngữ lập trình là title, price, và author cho các giá trị trả về của con trỏ books.
#sql books = {
SELECT title, price INTO :title, :price
FROM Books WHERE author = :author
};
Trong JDBC, chúng ta có thể quyết định một cách linh động những biến nào của ngôn ngữ lập trình sẽ nắm giữ kết quả truy vấn. Trong ví dụ sau đây, chúng ta đọc title của một quyển sách vào trong biến ftitle nếu quyển sách đó được viết bằng Feynman, và vào biến otitle trong những trường hợp khác:
//assume we have a ResultSet cursor rs
author = rs.getString(3);
if (author=="Feynman") {
ftitle = rs.getString(2);
}
else {
otitic = rs.getString(2);
}
Khi biết các ứng dụng SQLJ, chúng ta chỉ viết mã lệnh Java thông thường và các câu lệnh Embedded SQL. Các ứng dụng SQLJ được tiền xử lý thông qua một chương trình dịch. Nếu chương trình sửa đổi, nó có thể được biên dịch lại bằng bất kỳ trình biên dịch Java nào. Thông thường, thư viện SQLJ Java gọi tới một JDBC driver, nơi nắm giữ những kết nối tới hệ thống cơ sở dữ liệu.
Có một sự khác nhau tồn tại giữa Embedded SQL và SQLJ và JDBC. Vì những nhà phát triển cung cấp các phiên bản khác nhau về SQL, chúng ta có thể viết các truy vấn SQL theo chuẩn SQL-92 hoặc SQL:1999. Tuy nhiên, khi sử dụng Embedded SQL, yêu cầu phải sử dụng các cấu trúc SQL xác định của từng nhà cung cấp- các cấu trúc này dựa trên chuẩn SQL-92 và SQL:1999. SQLJ và JDBC có thể linh động hơn để tương thích với các hệ thống cơ sở dữ liệu khác nhau.
Trong phần còn lại, chúng tôi sẽ cung cấp giới thiệu ngắn gọn về SQLJ.
Viết mã lệnh SQLJ
Chúng ta sẽ tìm hiểu SQLJ thông qua các ví dụ. Hãy cùng chúng tôi bắt đầu bằng một đoạn mã lệnh SQLJ, nó đưa ra những bản ghi từ bảng Books sau khi so sánh với một tác giả (author) nào đó được cung cấp.
String title; Float price; String author;
#sql iterator Books (String title, Float price);
Books books;
//the application sets the author
//execute the query and open the cursor
#sql books = {
SELECT title, price INTO :title, :price
FROM Books WHERE author = :author
};
//retrieve results
while (books.next()) {
System.out.println(books.title() + ", " + books.price());
}
books.close();
Đoạn mã viết bằng JDBC sẽ như sau (giả sử chúng ta cũng đã khai báo price, name, và author):
PreparedStatement stmt = connection.prepareStatement(
"SELECT title, price FROM Books WHERE author = ?");
//set the parameter in the query and execute it
stmt.setString(l, author);
ResultSet rs = stmt.executeQuery();
//retrieve the results
while (rs.next()) {
System.out.println(rs.getString(l) + ", " + rs.getFloat(2));
}
So sánh hai đoạn mã lệnh viết bằng JDBC và SQLJ, chúng ta nhận thấy rằng mã lệnh của SQLJ dễ hiểu hơn JDBC. Vì thế, SQLJ giảm thời gian viết chương trình và bảo trì cho các nhà phát triển phần mềm.
Chúng ta hãy cùng nhau xem xét các thành phần trong đoạn mã SQLJ một cách chi tiết hơn. Tất cả các câu lệnh SQLJ có một tiền tố #sql. Trong SQLJ, chúng ta truy cập tới các kết quả của truy vấn SQL bằng các đối tượng iterator, là các con trỏ cơ bản. Một iterator là một minh hoạ của một lớp iterator. Sử dụng một iterator trong SQLJ phải đi qua năm bước:
- Khai báo Iterator Class: Đoạn mã trước sử dụng câu lệnh:
#sql iterator Books (String title, Float price);
Câu lệnh này tạo ra một Java class mới.
- Tạo một đối tượng Iterator Object từ Iterator Class: Chúng ta tạo một iterator của chúng ta thông qua câu lệnh Books books;.
- Khởi tạo một Iterator sử dụng một câu lệnh SQL: Trong ví dụ của chúng ta sử dụng câu lệnh #sql books = ....
- Lặp, đọc các dòng từ một đối tượng Iterator: Bước này tương tự như việc đọc các dòng trong một đối tượng ResultSet của JDBC.
- Đóng đối tượng Iterator.
Có hai kiểu của lớp Iterator: named iterators và positional iterators. Với named iterators, chúng ta chỉ rõ cả kiểu biến và tên của mỗi cột trong một iterator. Điều này cho phép chúng ta truy cập tới các cột riêng lẻ bằng tên như trong ví dụ trước, chúng ta có thể truy cập tới cột title trong bảng Books sử dụng biểu thức books.title(). Với positional iterators, chúng ta chỉ cần chỉ rõ kiểu biến của mỗi cột trong một iterator. Để truy cập tới các cột riêng lẻ, chúng ta sử dụng cấu trúc FETCH . . . INTO, tương tự như trong Embedded SQL. Cả hai kiểu iterator trên cho cùng một kết qủa, sử dụng cách nào tuỳ thuộc vào người lập trình.
Hãy cùng xem ví dụ của chúng tôi. Chúng tôi tạo một positional iterator thông qua câu lệnh sau:
#sql iterator Books (String, Float);
Sau đó chúng ta truy cấp đến từng dòng như sau:
while (true) {
#sql { FETCH :books INTO :title, :price, };
if (books.endFetch()) {
break;
}
// process the book
}
Store procedures
Một điều quan trọng chúng ta cần phải biết là một số phần của chương trình ứng dụng nên được thực thi trực tiếp trong hệ thống cơ sở dữ liệu. Lợi ích của việc này là giảm được sự trao đổi một lượng lớn dữ liệu giữa máy chủ chứa cơ sở dữ liệu và máy trạm, thêm nữa nó cũng tận dụng được năng lực mạnh mẽ của các máy chủ.
Khi các câu lệnh SQL được phát ra từ một ứng dụng ở xa, các bản ghi trong kết quả của truy vấn cần được chuyển từ máy chủ tới các máy trạm. Nếu chúng ta sử dụng một con trỏ để truy cập tới kết quả của câu lệnh SQL, hệ quản trị cơ sở dữ liệu có những tính năng như các khoá và bộ nhớ phải thực hiện nhiệm vụ của nó trong khi ứng dụng đó đang xử lý các bản ghi mà con trỏ đó truy cập. Ngược lại, một stored procedure là một chương trình có thể được thực thi và hoàn thành trong không gian làm việc của máy chủ. Những kết quả có thể được đóng gói và trả về cho ứng dụng, hoặc ứng dụng này có thể được thực hiện trực tiếp trên máy chủ, không cần trao đổi kết quả liên tục với máy trạm.
Stored procedures cũng có nhiều lợi ích đối với người lập trình phần mềm. Khi một stored procedure được đăng ký tại một máy chủ, những người sử dụng khác có thể tái sử dụng stored procedure này. Thêm nữa, những người lập trình ứng dụng không cần phải biết lược đồ cơ sở dữ liệu nếu chúng ta tóm lược được tất cả các truy cập tới cơ sở dữ liệu trong các stored procedures.
Tạo một stored procedure đơn giản
Hãy cùng nhau theo dõi một ví dụ về stored procedure viết bằng SQL. Chúng ta nhìn thấy rằng các stored procedure phải được đặt tên; stored procedure này có tên là ‘ShowNumberOfOrders’. Mặt khác, nó chỉ chứa một câu lệnh SQL đã được biên dịch và lưu trữ trên máy chủ.
CREATE PROCEDURE ShowNumberOfOrders
SELECT C.cid, C.cname, COUNT(*)
FROM Customers C, Orders O
WHERE C.cid = O.cid
GROUP BY C.cid, C.cnameMột Stored Procedures trong SQL
Stored procedures cũng có thể chứa biến. Những biến này phải có kiểu dữ liệu giống kiểu dữ liệu của SQL, và là một trong ba dạng sau: IN, OUT, hoặc INOUT. Các biến dạng IN là các tham số được lưu trong stored procedure. Các biến dạng OUT được stored procedure đó trả về. Các biến INOUT kết hợp những tính chất của biến dạng IN và OUT. Stored procedures kiểm tra chặt chẽ khi có sự so sánh giữa các kiểu dữ liệu: Nếu một biến có kiểu là INTEGER, nó sẽ không thể được gọi bằng một tham số có kiểu VARCHAR. Hãy cùng chúng tôi xem ví dụ về một stored procedure có các tham số. Stored procedure này trong Hình 6.9 có hai tham số: book_isbn và addedQty.
CREATE PROCEDURE AddInventory (
IN book_isbn CHAR(10),
IN addedQty INTEGER)
UPDATE Books
SET qty_in_stock = qty_in_stock + addedQty
WHERE book_isbn = isbnMột Stored Procedure có tham số
Stored procedures không phải được viết bằng SQL; chúng có thể được viết bằng ngôn ngữ lập trình. Như stored procedures là một hàm Java được thực hiện linh động trên máy chủ ngay khi có một yêu cầu từ một máy trạm nào đó.
CREATE PROCEDURE RankCustomers(IN number INTEGER)
LANGUAGE Java
EXTERNAL NAME 'file:///c:/storedProcedures/rank.jar'Một Stored Procedure trong Java
Việc gọi Stored Procedures
Stored procedures có thể được gọi trong SQL cùng với câu lệnh CALL:
CALL storedProcedureName(argumentl, argument2, . . . , argumentN)
Trong Embedded SQL, các tham số của một stored procedure thường là các biến trong ngôn ngữ lập trình. Ví dụ. stored procedure AddInventory sẽ được gọi như sau:
EXEC SQL BEGIN DECLARE SECTION
char isbn[10];
long qty;
EXEC SQL END DECLARE SECTION
//set isbn and qty to some values
EXEC SQL CALL AddInventory(:isbn,:qty);
Việc gọi các Stored Procedures từ JDBC
Chúng ta có thể gọi các stored procedure từ JDBC sử dụng một lớp là CallableStatement. CallableStatement là một lớp con của lớp PreparedStatement và cung cấp những tính năng tương tự. Một stored procedure có thể chứa nhiều câu lệnh SQL. Chúng ta minh hoạ trường hợp khi kết quả của một stored procedure là một ResultSet đơn.
CallableStatement cstmt=
con.prepareCall(" {call ShowNumberOfOrders}");
ResultSet rs = cstmt.executeQuery()
while (rs.next())
…
Việc gọi các Stored Procedures từ SQLJ
Thủ tục “ShowNumberOfOrders” được gọi như sau khi sử dụng SQLJ:
//create the cursor class
z#sql Iterator CustomerInfo(int cid, String cname, int count);
//create the cursor
CustomerInfo customerinfo;
//call the stored procedure
#sql customerinfo = {CALL ShowNumberOfOrders}
while (customerinfo.next()) {ra>
System.out.println(custoinerinfo.cid()+"," + customerinfo.count ());
}
SQL/PSM
Tất cả các hệ thống cơ sở dữ liệu đều cung cấp các cách thức để người dùng dễ dàng viết các stored procedures một cách đơn giản. Trong phần này, chúng tôi sẽ giới thiệu tóm tắt về chuẩn SQL/PSM, nó là một đại diện của hầu hết các ngôn ngữ của các nhà cung cấp khác nhau. Trong PSM, chúng ta định nghĩa các modun, là tập hợp của các stored procedures, các quan hệ tạm thời, và các khai báo khác.
Trong SQL/PSM, chúng ta định nghĩa một stored procedure như sau:
CREATE PROCEDURE name(parameterl,..., parameterN)
local variable declarations
procedure code;
Chúng ta có thể khai báo một hàm (function) đơn giản như sau:
CREATE FUNCTION name (parameterl,..., parameterN)
RETURNS sqlDataType
local variable declarations
function code;
Mỗi một biến nằm trong một trong số ba dạng (IN, OUT, hoặc INOUT) như đã trình bày trong phần trước, tên biến, và kiểu dữ liệu SQL của biến đó. Chúng ta có thể nhìn thấy các thủ tục SQL/PSM trong phần 6.5.1. Trong trường hợp này, một biến địa phương khai báo là rỗng, và đoạn mã lệnh của thủ tục này chứa một truy vấn SQL.
Chúng ta bắt đầu bằng một ví dụ của hàm SQL/PSM minh hoạ cấu trúc chính của SQL/PSM. Hàm này có đầu vào là một khách hàng được xác định bằng cid của cô ấy và một năm (year) nào đó. Hàm này trả về thứ hạng rating của khách hàng đó, thứ hạng này được định nghĩa như sau: Những khách hàng đã mua nhiều hơn 10 quyển sách trong năm đó được xếp hạng hai (two); khách hàng mua từ 5 đến 10 quyển được xếp hạng là một (one); những trường hợp khác được xếp hạng là không (zero). Đoạn mã lệnh đưa ra xếp hạng của một khách hàng trong một năm nào đó là:
CREATE PROCEDURE RateCustomer
(IN custid INTEGER, IN year INTEGER)
RETURNS INTEGER
DECLARE rating INTEGER;
DECLARE numOrders INTEGER;
SET numOrders =
(SELECT COUNT(*) FROM Orders O WHERE O.cid = custid);
IF (numOrders>10) THEN rating=2;
ELSEIF (numOrders>5) THEN rating=l;
ELSE rating=0;
END IF;
RETURN rating;
Thông qua ví dụ này chúng ta hãy cùng tìm hiểu ngắn gọn về một số cấu trúc của SQL/PSM:
- Chúng ta có thể khai báo các biến địa phương sử dụng lệnh DECLARE. Trong ví dụ của chúng ta, chúng ta khai báo hai biến địa phương là rating, và numOrders.
- Các PSM/SQL trả về giá trị thông qua câu lệnh RETURN. Trong ví dụ của chúng ta, chúng ta trả về một giá trị của biến địa phương là rating.
- Chúng ta có thể gán những giá trị cho các biến cùng với câu lệnh SET. Trong ví dụ của chúng ta, chúng ta gán giá trị trả về của một truy vấn cho biến numOrders.
- SQL/PSM có sử dụng cấu trúc rẽ nhánh và lặp. Cấu trúc rẽ nhánh có dạng như sau:
IF (condition) THEN statements;
ELSEIF statements;
…
ELSEIF statements;
ELSE statements; END IF
Cấu trúc lặp có dạng như sau:
LOOP
Statements;
END LOOP
- Các truy vấn có thể được sử dụng như là một phần của các biểu thức trong cấu trúc rẽ nhánh: các truy vấn trả về một giá trị đơn có thể được gán cho biến giống như ví dụ trên.
- Chúng ta có thể sử dụng các câu lệnh của con trỏ như trong Embedded SQL (OPEN, FETCH, CLOSE), nhưng chúng ta không cần cấu trúc EXEC SQL, và các biến không phải có tiền tố là dấu “:”.
Trên đây chỉ là tổng quan rất ngắn gọn về SQL/PSM, các tham chiếu liệt kê ở cuối chương sẽ cung cấp nhiều thông tin hơn.
Trường hợp nghiên cứu: Cửa hàng Internet
DBDudes đã hoàn thành việc thiết kế cơ sở dữ liệu logic trong Phần 3.8, và bây giờ xem xét các truy vấn mà chúng phải hỗ trợ. Họ hy vọng ứng dụng của họ sẽ được viết bằng Java, vì thế họ xem xét JDBC và SQLJ.
Xem lại lược đồ cơ sở dữ liệu của DBDudes:
Books(isbn: CHAR(10), title:CHAR(8), author:CHAR(80),
qty_in_stock:INTEGER, price: REAL, year_published: INTEGER)
Customers(cid: INTEGER, cname: CHAR(80), address: CHAR(200))
Orders (ordernum: INTEGER, isbn: CHAR (10), cid: INTEGER,
cardnum: CHAR(16), qty:INTEGER,order_date:DATE,ship_date: DATE)
Bây giờ, DBDudes xem xét các kiểu của yêu cầu truy vấn và cập nhật. Đầu tiên, họ tạo ra một danh sách các công việc phải thực hiện trong ứng dụng.
Những công việc này được các khách hàng thực hiện, bao gồm:
- Các khách hàng tìm sách thông qua tên tác giả (author name), tiều đề (title), hoặc mã ISBN.
- Các khách hàng đăng ký với website này. Những khách hàng đã đăng ký có thể muốn thay đổi thông tin của họ. DBDudes tin rằng họ phải thêm thông tin vào bảng Customers để lưu giữ login và password của mỗi khách hàng, chúng ta không bàn đến khía cạnh này thêm nữa.
- Các khách hàng kiểm tra giỏ hàng của mình lần cuối cùng trước khi thanh toán.
- Các khách hàng có thể thêm hoặc bỏ bớt sách đã lựa chọn ra khỏi giỏ hàng.
- Các khách hàng kiểm tra trạng thái của các hoá đơn đang tồn tại và xem xét những hoá đơn cũ.
Những công việc hành chính được các nhân viên của B&N thực hiện bao gồm:
- Nhân viên tìm kiếm thông tin liên lạc của khách hàng.
- Nhân viên thêm các quyển sách mới vào kho.
- Nhân viên hoàn tất những hoá đơn, và cần phải cập nhật ngày giao hàng của từng quyển sách.
- Nhân viên phân tích dữ liệu để tìm ra những khách hàng tiềm năng và những khách hàng yêu thích để gửi cho họ những chiến dịch bán hàng đặc biệt.
Tiếp đến, DBDudes xem xét các kiểu truy vấn để có thể đáp ứng được những yêu cầu này. Để hỗ trợ tìm kiếm sách theo tên, tác giả, tiêu đề, hoặc mã ISBN, DBDudes quyết định viết một thủ tục như sau:
CREATE PROCEDURE SearchByISBN (IN bookIsbn CHAR(10))
SELECT B.title, B.author, B.qty_in_stock, B.price, B.year_published
FROM Books B
WHERE B.isbn = bookIsb
Việc đặt một hoá đơn nào đó bao gồm việc thêm một hoặc nhiều bản ghi vào trong bảng Orders. Vì DBDudes không lựa chọn Java để viết chương trình, họ giả sử rằng những quyển sách riêng lẻ trong một hoá đơn được lưu ở lớp ứng dụng trong một mảng của Java. Để hoàn thành hoá đơn, họ viết một đoạn mã JDBC để thêm những thành phần của mảng vào trong bảng Orders. Giả sử rằng đoạn mã có một số biến Java đã được khai báo trước.
String sql = "INSERT INTO Orders VALUES(?, ?, ?, ?, ?, ?)";
PreparedStatement pstmt = con.prepareStatement(sql);
con.setAutoCommit(false);
try {
// orderList is a vector of Order objects
// ordernum is the current order number
// cid is the ID of the customer, cardnum is the credit card number
for (int i=0; i<orderList.length(); i++)
// now instantiate the parameters with values
Order currentOrder = orderList [i];
pstmt.clearParameters();
pstmt.setInt(l, ordernum):
pstmt.setString(2, Order.getIsbn());
pstmt.setInt(3, cid);
pstmt.setString(4, creditCardNum);
pstmt.setInt(5. Order.getQtyO);
pstmt.setDate(6, null);
pstmt.executeUpdate();
}
con.commit ();
catch(SQLException e){
con.rollback();
System.out.println(e.getMessage());
} Thêm một hoá đơn đã hoàn thành vào cơ sở dữ liệu
DBDudes viết đoạn mã lệnh JDBC khác và các stored procedures khác cho tất cả các công việc còn lại. Họ sử dụng đoạn mã tương tự với một số chương trình mà chúng ta đã thấy trong chương này.
- Việc thành lập một kết nối tới một cơ sở dữ liệu được minh hoạ trong Hình 6.2.
- Việc thêm sách mới vào kho, Hình 6.3.
- Việc xử lý những kết quả từ các truy vấn SQL, Hình 6.4.
- Với mỗi khách hàng, chỉ ra bao nhiêu hoá đơn cô, anh ấy đã đặt. Chúng tôi chỉ ra một ví dụ về stored procedure đơn giản trong Hình 6.8.
- Việc tăng số lượng bản sách của một quyển sách, Hình 6.9.
- Xếp hạng khách hàng theo số lượng sách họ đã mua, Hình 6.10.
DBDudes cũng đã xử lý những trường hợp đặc biệt và những cảnh báo, Hình 6.6.
DBDudes cũng đã quyết định viết một trigger. Bất cứ khi nào một hoá đơn mới được thêm vào bảng Orders, nó được thêm cùng với trường ship_date được thiết đặt thành null. Trigger này xử lý mỗi dòng trong hoá đơn và gọi đến stored procedure là ‘UpdateShipDate’. Stored procedure này (đoạn mã lệnh không được chỉ ra ở đây) cập nhật trường ship_date cho mỗi hoá đơn mới thành ‘tomorrow’, trong trường hợp trường qty_in_stock của quyển sách tương ứng trong bảng Books lớn hơn zero. Ngược lại, stored procedure này thiết đặt trường ship_date lên hai tuần.
CREATE TRIGGER update_ShipDate
AFTER INSERT ON Orders /* Event */
FOR EACH ROW
BEGIN CALL UpdateShipDate(new); END /* Action */Trigger to Update the Shipping Date of New Orders
Câu hỏi ôn tập
Những câu trả lời của các câu hỏi sau có thể tìm thấy trong mục kèm theo.
- Vì sao không dễ dàng để kết hợp các truy vấn SQL với một ngôn ngữ lập trình nào đó? (Phần 1.1)
- Chúng ta khai báo các biến trong Embedded SQL thế nào? (Phần 1.1)
- Chúng ta sử dụng các câu lệnh SQL trong ngôn ngữ lập trình như thế nào? Như thế nào để kiểm tra lỗi khi thực thi các câu lệnh này? (Phần 1.1)
- Các tính chất của con trỏ? (Phần 1.2)
- Dynamic SQL là gì và nó khác với Embedded SQL như thế nào? (Phần 1.3)
- JDBC là gì và những ưu điểm của nó? (Phần 2)
- Những thành phần của kiến trúc JDBC? (Phần 2.1)
- Làm thế nào để tải các JDBC drivers trong một chương trình viết bằng Java? (Phần 3.1)
- Chúng ta quản lý các kết nối tới nguồn dữ liệu như thế nào? Những tính chất của các kết nối? (Phần 3.2)
- Những khả năng mà JDBC cung cấp để thực hiện các câu lệnh SQL DML và DDL? (Phần 3.3)
- Chúng ta quản lý các exceptions và warnings trong JDBC như thế nào? (Phần 3.5)
- Những tính năng mà lớpDatabaseMetaData là gì? (Phần 3.6)
- SQLJ là gì và nó khác với JDBC thế nào? (Phần 4)
- Vì sao stored procedures quan trọng? Khai báo stored procedures như thế nào và gọi thế nào trong chương trình ứng dụng? (Phần 5)
Bài tập
Trả lời tóm tắt các câu hỏi sau.
1. Giải thích các khái niệm sau: Cursor, Embedded SQL, JDBC, SQLJ, stored procedure.
2. Sự khác nhau giữa JDBC và SQLJ? Vì sao cả hai cùng tồn tại?
3. Giải thích khái niệm stored procedure, và cung cấp một ví dụ để giải thích vì sao chúng hữu dụng?
Trả lời: Câu trả lời với mỗi câu hỏi như sau:
1. Một con trỏ có thể truy cập một dòng nào đó của quan hệ và đọc nội dung của nó. Embedded SQL được coi là các câu lệnh SQL trong ngôn ngữ lập trình trên máy trạm. JDBC viết tắt của Java DataBase Connectivity, là giao diện cho phép một chương trình Java kết nối dễ dàng với bất kỳ hệ thống cơ sở dữ liệu nào. SQLJ là công cụ cho phép SQL được nhúng trực tiếp vào một chương trình Java nào đó. Một stored procedure là chương trình chạy trên máy chủ cơ sở dữ liệu và có thể được gọi bằng một câu lệnh SQL.
2. SQLJ cung cấp các câu lệnh nhúng SQL. Những câu lệnh này là tĩnh và vì thế được tiền xử lý và tiền biên dịch. Với từng trường hợp, việc kiểm tra cú pháp và kiểm tra lược đồ được làm tại thời điểm biên dịch. JDBC cho phép các truy vấn động-những truy vấn được kiểm tra ở thời gian chạy. SQLJ dễ sử dụng hơn JDBS và thường là lựa chọn tốt hơn cho các truy vấn tĩnh. Với các truy vấn động, JDBC vẫn phải được sử dụng.
3. Stored procedures là các chương trình chạy trên máy chủ cơ sở dữ liệu và có thể được gọi bằng một câu lệnh SQL. Chúng hữu dụng trong một số trường hợp nơi mà việc xử lý nên được làm bên phía máy chủ tốt hơn là bên phía máy trạm. Cũng như vậy, vì những thủ tục được tập trung ở phía mãy chủ, nên việc viết chương trình và bảo trì rất đơn giản. Các Stored procedures có thể cũng được sử dụng để giảm kết nối mạng; kết quả của một stored procedure nào đó có thể được phân tích và lưu giữ trên máy chủ cơ sở dữ liệu.
Giải thích cách các bước sau được thực hiện trong JDBC:
1. Kết nối tới một nguồn dữ liệu.
2. Khởi động, hoàn thành, và huỷ bỏ các giao dịch.
3. Gọi một stored procedure.
Các bước này được thực hiện trong SQLJ thế nào?
Trả lời: Dành cho độc giả
So sánh việc quản lý các exception và warning trong embedded SQL, dynamic SQL, JDBC, và SQLJ.
Trả lời: Câu trả lời với mỗi câu hỏi như sau:
Embedded SQL: Biến SQLSTATE được sử dụng để kiểm tra các lỗi sau khi từng câu lệnh Embedded SQL được thực hiện. Nếu một lỗi nào đó xảy ra, bộ điều khiển sẽ đưa ra một thông báo lỗi. Điều này được làm trong suốt quá trình tiền biên dịch của mỗi truy vấn tĩnh.
Dynamic SQL: Với dynamic SQL, câu lệnh SQL có thể thay đổi ở thời gian chạy và vì thế việc quản lý lỗi cũng phải xảy ra ở thời điểm này.
JDBC: Trong JDBC, người lập trình có thể sử dụng cú pháp try ... catchđể quản lý các ngoại lệ của kiểu SQLException. Lớp SQLWarningđược sử dụng cho những vấn đề khắt khe như là các lỗi chương trình. Chúng không nắm bắt được bằng câu lệnh try ... catch và phải được kiểm tra độc lập bằng cách gọi hàm getWarnings().
SQLJ: SQLJ sử dụng các cơ chế như JDBC để nắm bắt lỗi (errors) và lời nhắc (warnings).
Trả lời những câu hỏi sau.
- Vì sao chúng ta cần tiền biên dịch Embedded SQL và SQLJ? Vì sao lại không cần nó trong JDBC?
- SQLJ và Embedded SQL sử dụng các biến trong ngôn ngữ lập trình để gán cho các tham số trong các truy vấn SQL, trong khi JDBC sử dụng những ký tự đại diện ‘?’. Giải thích sự khác nhau này, và vì sao lại cần như vậy?
Trả lời: Dành cho độc giả
Một trang Web động đưa ra những trang HTML lấy thông tin từ cơ sở dữ liệu. Bất cứ khi nào một trang được yêu cầu, nó linh động tập hợp dữ liệu từ những dữ liệu tĩnh và những dữ liệu trong cơ sở dữ liệu. Việc kết nối tới một cơ sở dữ liệu thường tốn nhiều thời gian, vì cần phải định vị những tài nguyên, và cần phải xác định quyền truy cập của những người dùng. Vì thế, connection pooling- thiết lập một bể của các kết nối đang tồn tại và sau đó sử dụng lại chúng cho những yêu cầu khác nhau nhằm cải thiện hiệu năng thực hiện của hệ thống. Vì thế, các máy chủ có thể lưu giữ thông tin của các kết nối, chúng ta có thể tạo ra một bể kết nối, và định vị nguồn tài nguyên khi có một yêu cầu mới.
Viết một lớp bể kết nối cung cấp các phương thức sau:
- Tạo ra một bể (pool) với một số lượng xác định các kết nối tới một hệ thống cơ sở dữ liệu.
- Nhận được một kết nối mở từ bể.
- Huỷ bỏ một kết nối trong bể.
- Huỷ bỏ bể và đóng tất cả các kết nối.
Trả lời: Câu trả lời cho bài tập này được hỗ trợ trực tiếp cho các giáo viên. Cách thức để truy cập đến các tài nguyên của giáo viên được nêu trong trang chủ của cuốn sách này:
http://www.cs.wisc.edu/~dbbook.
Bài tập lớn
Trong những bài tập sau, bạn sẽ tạo ra những ứng dụng có liên quan đến cơ sở dữ liệu. Trong chương này, bạn sẽ tạo ra các phần khác nhau của một ứng dụng có truy cập tới cơ sở dữ liệu. Trong chương tiếp theo, bạn sẽ lập trình thêm những chức năng khác của ứng dụng. Chi tiết thông tin về những bài tập và những tài liệu khác có thể tìm thấy tại địa chỉ:
http://www.cs.wisc.edu/ dbbook
Bài 6.6 Nhớ lại thiết kế cơ sở dữ liệu bạn đã làm trong Bài 2.5 và 3.15. Bây giờ bạn sẽ bắt đầu việc thiết kế website cho Notown. Những tính năng sau nên được hỗ trợ:
- Người dùng có thể tìm kiếm các đĩa nhạc thông qua tên nhạc sỹ, tiêu đề của album, và tên của bài hát.
- Người dùng có thể đăng ký làm thành viên của website này, và những người dùng đã đăng ký có thể đăng nhập được. Khi người dùng đã đăng nhập, họ không nên phải đăng nhập lại trừ khi họ không hoạt động trong một thời gian dài.
- Người dùng đã đăng nhập vào website có thể thêm những mặt hàng vào giỏ hàng của họ.
- Người dùng có thể thanh toán giỏ hàng họ đã mua.
Notown muốn sử dụng JDBC để truy cập cơ sở dữ liệu. Viết chương trình bằng để thực hiện truy cập và thao tác dữ liệu cần. Bạn sẽ tích hợp đoạn chương trình này với chương trình ứng dụng và trình bày trong chương kế tiếp. Nếu Notown đã được lựa chọn SQLJ thay vì JDBC, chương trình của bạn sẽ thay đổi như thế nào?
Bài 6.7 Nhớ lại lược đồ cơ sở dữ liệu của Prescriptions-R-X mà bạn tạo ra ở Bài 2.7. Prescriptions-R-X yêu cầu bạn thiết kế trang web mới cho họ. Website này có hai lớp người dùng khác nhau: bác sĩ và bệnh nhân. Bác sĩ sẽ có thể nhập những đơn thuốc mới cho bệnh nhân của mình và sửa đổi những đơn thuốc đang tồn tại. Bệnh nhân có thể trình báo mình là bệnh nhân của bác sĩ nào; họ có thể kiểm tra trạng thái những đơn thuốc một cách trực tuyến, và có thể đặt mua những đơn thuốc đó để các nhà cung cấp có thể mang đến tận nhà của họ. Làm theo các bước tương tự như Bài 6.6 để viết chương trình bằng JDBC thực hiện truy cập và thao tác trên những dữ liệu cần thiết. Bạn sẽ tích hợp đoạn chương trình này với ứng dụng và trình bày trong chương kế tiếp.
Bài 6.8 Nhớ lại lược đồ cơ sở dữ liệu bạn đã làm trong bài 5.1. Trường đại học này đã quyết định chuyển việc đăng ký học tới một hệ thống trực tuyến. Website này có hai lớp người dùng khác nhau: khoa và sinh viên. Khoa sẽ có thể tạo mới và xóa các khóa học hiện có, và sinh viên sẽ có thể đăng ký vào các khóa học này.
Làm theo các bước tương tự như Bài 6.6 để viết chương trình bằng JDBC thực hiện truy cập và thao tác trên những dữ liệu cần thiết. Bạn sẽ tích hợp đoạn chương trình này với ứng dụng và trình bày trong chương kế tiếp.
Bài 6.9 Nhớ lại lược đồ cơ sở dữ liệu Đặt vé máy bay bạn đã làm trong bài 5.3. Hệ thống này có hai lớp người dùng khác nhau: nhân viên hãng hàng không và khách hàng. Nhân viên có thể lập lịch cho những chuyến bay mới và có thể huỷ bỏ các chuyến bay. Khách hàng có thể đặt vé máy bay trên các chuyến bay đang tồn tại.
Làm theo các bước tương tự như Bài 6.6 để viết chương trình bằng JDBC thực hiện truy cập và thao tác trên những dữ liệu cần thiết. Bạn sẽ tích hợp đoạn chương trình này với ứng dụng và trình bày trong chương kế tiếp.
Tài liệu tham khảo
Thông tin về ODBC có thể được tìm thấy trên trang web của Microsoft (www.microsoft.com/data/ODBC), và các thông tin về JDBC có thể được tìm thấy trên trang web của Java (Java.sun.com/products/jdbc). Hiện tồn tại nhiều sách về ODBC, ví dụ, Sanders' ODBC Developer's Guide [652] và Microsoft ODBC SDK [533]. Những quyển sách về JDBC của Hamilton et al. [359], Reese [621], và White et al. [773].