Cách một DBMS thực thi những truy vấn và cập nhật thông thường là thước đo cuối cùng để đánh giá phần thiết kế cơ sở dữ liệu. DBA có thể cải thiện khả năng thực thi bằng cách xác định những nút cổ chai trong quá trình thực hiện và điều chỉnh một vài tham số của DBMS (ví dụ, kích thước của buffer pool hoặc tần số của checkpointing) hoặc thêm phần cứng để loại bỏ những nút cổ chai. Tuy nhiên, bước đầu tiên để đạt được hiệu quả trong thực thi là lựa chọn được thiết kế cơ sở dữ liệu tốt, đây là nội dung chính của chương này.
Sau khi chúng ta thiết kế lược đồ khái niệm và lược đồ ngoài, tức là, tạo ra một tập các quan hệ và các khung nhìn cùng với một tập các ràng buộc tham chiếu, chúng ta sẽ tiến hành thiết kế cơ sở dữ liệu vật lý qua việc thiết kế lược đồ vật lý. Vì những yêu cầu của người dùng thường thay đổi nên phần thiết kế này cũng phải điều chỉnh thường xuyên.
Chương này được tổ chức như sau. Phần 1 cung cấp tổng quan về thiết kế cơ sở dữ liệu vật lý và các điều chỉnh. Phần quan trọng nhất trong thiết kế cơ sở dữ liệu vật lý là lựa chọn các chỉ mục. Chúng tôi trình bày phần hướng dẫn lựa chọn chỉ mục trong Phần 2. Những hướng dẫn này được minh hoạ thông qua một số ví dụ và phát triển thêm trong Phần 3. Phần 4 xem xét xem vấn đề phân cụm quan trọng như thế nào một cách cẩn thận; tiếp đến chúng tôi trình bày cách chọn các chỉ mục phân cụm và trả lời câu hỏi có nên lưu trữ các bộ giá trị trong các quan hệ khác nhau nằm cạnh nhau hay không (lựa chọn này được một số DBMS hỗ trợ). Phần 5 tập trung vào giải thích việc lựa chọn chỉ mục tốt có thể thực hiện một số truy vấn mà không cần phải tìm kiếm trong phần dữ liệu thực. Phần 6 bàn về các công cụ có thể giúp DBA tự động lựa chọn chỉ mục.
Phần 7 nghiên cứu những vấn đề chính của việc điều chỉnh cơ sở dữ liệu. Để điều chỉnh các chỉ mục, chúng ta có lẽ phải điều chỉnh lược đồ khái niệm cũng như tần số sử dụng truy vấn và việc định nghĩa các khung nhìn. Chúng tôi trình bày cách điều chỉnh truy vấn và các định nghĩa khung nhìn trong Phần 9. Chúng tôi trình bày tóm tắt ảnh hưởng của truy cập tương tranh trong Phần 10. Phần 11 minh hoạ việc điều chỉnh trên ví dụ cửa hàng Internet. Chúng tôi tổng kết chương này bằng việc trình bày những tiêu chuẩn giúp đánh giá DBMS trong Phần 12; các tiêu chuẩn này hỗ trợ đánh giá khả năng thực thi của DBMS.
Giới thiệu về thiết kế cơ sở dữ liệu vật lý
Giống như tất cả các phần thiết kế cơ sở dữ liệu khác, thiết kế vật lý phải được định hướng bởi yếu tố tự nhiên của dữ liệu và những chức năng gì mà người dùng mong muốn sử dụng. Cụ thể, chúng ta phải hiểu về những luồng công việc điển hình mà cơ sở dữ liệu phải hỗ trợ, luồng công việc bao gồm cả các truy vấn và cập nhật dữ liệu. Người dùng cũng có một số yêu cầu về việc tốc độ thực hiện các truy vấn hoặc việc những cập nhật nào phải được thực thi hoặc có bao nhiêu giao dịch phải được xử lý mỗi giây. Biểu diễn luồng công việc và những yêu cầu thực thi của người dùng là cơ sở để tiến hành thiết kế cơ sở dữ liệu vật lý.
Để tạo ra một thiết kế cơ sở dữ liệu vật lý tốt và điều chỉnh sao cho hệ thống này thực hiện phù hợp với những yêu cầu nảy sinh mới của người dùng, người thiết kế phải hiểu được những công việc của một DBMS, đặc biệt là những công nghệ xử lý truy vấn và chỉ mục mà nó hỗ trợ. Nếu cơ sở dữ liệu này có nhiều người sử dụng đồng thời, hoặc nó là cơ sở dữ liệu phân tán, thì các công việc trở nên phức tạp hơn.
Chúng tôi trình bày những ảnh hưởng của tương tranh đối với việc thiết kế cơ sở dữ liệu trong Phần 10 và cơ sở dữ liệu phân tán trong Chương 22.
Luồng công việc của cơ sở dữ liệu
Chìa khoá để thiết kế vật lý tốt là phải có được một biểu diễn chính xác của các luồng công việc mong muốn. Biểu diễn luồng công việc bao gồm:
- Danh sách các truy vấn (cùng với tần suất của chúng).
- Danh cách các cập nhật và tần suất của chúng.
- Những đích cần đạt đến của mỗi kiểu truy vấn và cập nhật.
Với mỗi truy vấn trong một luồng công việc, chúng ta phải xác định:
- Các quan hệ nào cần phải truy cập.
- Những thuộc tính nào phải giữ lại (trong mệnh đề SELECT).
- Những thuộc tính nào phải lấy hoặc các điều kiện kết nối (trong mệnh đề WHERE).
Tương tự, với mỗi cập nhật trong luồng công việc, chúng ta phải xác định:
- Lựa chọn những thuộc tính nào và các điều kiện nối (trong mệnh đề WHERE).
- Kiểu cập nhật (INSERT, DELETE, hoặc UPDATE) và các quan hệ được cập nhật.
- Với các lệnh cập nhật, những trường (cột) nào sẽ thay đổi.
Ghi nhớ rằng các truy vấn và các cập nhật có thể có các tham số, ví dụ một thao tác ghi nợ hoặc thanh toán sẽ có tham số là số tài khoản cụ thể của một người nào đó.
Việc cập nhật bao giờ cũng chứa thành phần truy vấn để tìm ra các bộ giá trị cần được cập nhật. Thành phần này có thể được thực hiện tốt nếu chúng ta thiết kế vật lý tốt và có sự hiện diện của các chỉ mục.
Mặt khác, cập nhật luôn kéo theo một công việc khác đó là cập nhật các chỉ mục chứa các thuộc tính tính đã bị thay đổi. Vì thế, trong khi các truy vấn có thể được hưởng lợi từ sự hiện diện của chỉ mục thì các chỉ mục lại có thể làm tăng hoặc giảm tốc độ cập nhật. Người thiết kế luôn phải lưu ý đến điều này khi tạo ra các chỉ mục.
Các quyết định khi thiết kế vật lý và điều chỉnh
Những quyết định quan trong trong quá trình thiết kế cơ sở dữ liệu vật lý và điều chỉnh cơ sở dữ liệu bao gồm:
1. Lựa chọn những chỉ mục nào được tạo:
- Những quan hệ nào được chỉ mục và trường nào hoặc kết hợp một số trường để tạo ra chỉ mục khoá tìm kiếm.
- Với mỗi chỉ mục, xác định xem nó nên được phân cụm hay không phân cụm?
2. Điều chỉnh lược đồ khái niệm:
- Lựa chọn lược đồ chuẩn hoá: Chúng ta có nhiều hơn một cách để phân rã một lược đồ thành các quan hệ con ở dạng chuẩn mong muốn (BCNF hoặc 3NF). Quyết định chọn lược đồ nào sẽ dựa vào các điều kiện trong quá trình thực thi.
- Phi chuẩn hoá: Để cải thiện tốc độ thực thi các truy vấn, chúng ta sẽ xem xét lại các lược đồ phân rã đưa ra do việc chuẩn hoá khi thiết kế lược đồ khái niệm.
- Phân tách theo chiều dọc: Tuỳ theo tình trạng hiện tại, chúng ta có thể muốn quan hệ được phân rã sâu hơn nữa nhằm cải thiện tốc độ thực hiện các truy vấn chỉ bao gồm một vài thuộc tính.
- Khung nhìn: Chúng ta có lẽ muốn thêm một vài khung nhìn để che giấu những thay đổi trong lược đồ khái niệm.
3. Điều chỉnh truy vấn và giao dịch: Các truy vấn được thực hiện một cách liên tục và các giao dịch có lẽ cần được viết lại để chạy nhanh hơn.
Trong cơ sở dữ liệu phân tán và song song chúng ta sẽ bàn đến trong Chương 22, có một số lựa chọn để xem xét như phân chia một quan hệ ra các site khác nhau hay là lưu trữ bản sao của nó ở nhiều site.
Sự cần thiết phải điều chỉnh cơ sở dữ liệu
Những thông tin chi tiết về luồng thực thi có lẽ khó có được ngay từ khi bắt đầu thiết kế. Do đó, điều chỉnh một cơ sở dữ liệu sau khi nó đã được thiết kế và phát triển là một việc làm quan trọng- chúng ta phải cải tiến thiết kế ban đầu để đạt được hiệu quả thực thi tốt nhất.
Sự khác nhau giữa thiết kế cơ sở dữ liệu và điều chỉnh cơ sở dữ liệu đôi khi mang tính chất chủ quan. Chúng ta có thể coi kết quả của quá trình thiết kế là lược đồ khái niệm ban đầu, tập các chỉ mục và các phân cụm sẽ được tạo. Bất kể sự thay đổi nào tới lược đồ khái niệm và các lựa chọn chỉ mục và phân cụm trên đều được coi là chỉnh sửa. Chúng ta có thể coi một vài điều chỉnh của lược đồ khái niệm (và các quyết định thiết kế vật lý tạo ra do những điều chỉnh này) là một phần của quá trình thiết kế vật lý. Việc đánh giấu giữa thiết kế và hiệu chỉnh là không quan trọng, và khi chúng ta trình bày về những lựa chọn chỉ mục và điều chỉnh cơ sở dữ liệu không cần đề cập tới những điều chỉnh này đã thực hiện khi nào.
Các chỉ dẫn để lựa chọn chỉ mục
Khi xem xét những chỉ mục nào nên được tạo, chúng ta bắt đầu từ danh sách các truy vấn (bao gồm cả các truy vấn là một phần của thao tác cập nhật). Trước hết, chỉ những quan hệ được một vài truy vấn truy cập đến mới được xem là các ứng cử viên để đánh chỉ mục, và việc lựa chọn thuộc tính nào làm chỉ mục tuỳ thuộc vào các điều kiện xuất hiện trong các mệnh đề WHERE. Sự hiện diện của các chỉ mục thích hợp có thể cải thiện đáng kể khả năng thực thi truy vấn, như đã trình bày trong Chương 8 và 12.
Một cách tiếp cận để lựa chọn chỉ mục là xem xét những truy vấn quan trọng nhất và với mỗi truy vấn chúng ta sẽ chỉ định sử dụng các chỉ mục nào trong kế hoạch thực hiện của nó. Sau đó chúng ta cân nhắc xem liệu có thể có được một kế hoạch thực hiện tốt hơn không nếu chúng ta bổ sung thêm một số chỉ mục nữa; nếu có, những chỉ mục bổ sung này sẽ là ứng cử viên trong danh sách chỉ mục của chúng ta. Nói chung, những truy cập phạm vi hưởng lợi từ chỉ mục B+tree, và những truy cập so-sánh-chính-xác hưởng lợi từ chỉ mục băm. Việc phân cụm có lợi cho những truy vấn phạm vi, và nó có lợi cho những truy vấn so-sánh-chính-xác nếu một vài cổng vào dữ liệu chứa cùng giá trị khoá.
Tuy nhiên, trước khi thêm một chỉ mục vào danh sách chúng ta phải xem xét tác động của nó đối với thao tác cập nhật. Như chúng ta đã lưu ý ở phía trên, mặc dù chỉ mục có thể làm tăng tốc độ của thành phần truy vấn trong câu lệnh cập nhật, nhưng tất cả các chỉ mục có liên quan đến thuộc tính đã thay đổi phải được cập nhật theo. Vì thế, chúng ta phải cân nhắc khả năng một số phép toán cập nhật chịu tốc độ chậm để tăng tốc độ của những truy vấn khác.
Rõ ràng, để lựa chọn các chỉ mục tốt cho một luồng công việc nào đó yêu cầu chúng ta phải có những hiểu biết về các công nghệ chỉ mục và những gì bộ tối ưu hoá truy vấn làm. Những hướng dẫn sau về lựa chọn chỉ mục tổng kết những tranh luận của chúng ta:
Có nên chỉ mục (Hướng dẫn 1): Không nên xây dựng một chỉ mục nào đó nếu nó không phục vụ cho một vài truy vấn – bao gồm cả các truy vấn là thành phần của lệnh cập nhật - hưởng lợi từ nó. Bất cứ khi nào có thể, hãy lựa chọn các chỉ mục làm tăng tốc độ của nhiều hơn một truy vấn.
Lựa chọn Khoá tìm kiếm (Hướng dẫn 2): Các thuộc tính có trong một mệnh đề WHERE nào đó là các ứng cử viên được đánh chỉ mục.
- Điều kiện lọc so-sánh-chính-xác khuyên chúng ta xem xét một chỉ mục trên các thuộc tính được lọc, lý tưởng là một chỉ mục băm.
- Điều kiện lọc phạm vi khuyên chúng ta xem xét một chỉ mục B+tree (hoặc ISAM) trên các thuộc tính được lọc. Một chỉ mục B+tree thường tốt hơn một chỉ mục ISAM. Lựa chọn một chỉ mục ISAM nếu quan hệ này thường xuyên được cập nhật, nhưng để đơn giản chúng ta thừa nhận rằng một chỉ mục B+tree luôn được ưu tiên lựa chọn trước chỉ mục ISAM.
Các khoá tìm kiếm là đa-thuộc-tính (Hướng dẫn 3): Các chỉ mục với khoá tìm kiếm là đa-thuộc-tính nên được xem xét trong hai trường hợp sau:
- Mệnh đề WHERE chứa các điều kiện gồm nhiều hơn một thuộc tính của một quan hệ.
- Hệ thống cung cấp các chiến lược đánh giá chỉ-chỉ-số (tức là, việc truy cập các quan hệ có thể được tránh) đối với những truy vấn quan trọng. (Trường hợp này có thể dẫn đến một số thuộc tính nằm trong khoá tìm kiếm mặc dù chúng không xuất hiện trong mệnh đề WHERE.)
Khi khoá tìm kiếm là đa-thuộc-tính, các truy vấn phạm vi phải thận trọng với thứ tự các thuộc tính trong khoá tìm kiếm để tương ứng với các truy vấn.
Cân nhắc khi phân cụm (Hướng dẫn 4): Có nhiều nhất một chỉ mục phân cụm trên một quan hệ, và việc phân cụm ảnh hưởng rất lớn đến quá trình thực thi; vì thế lựa chọn chỉ mục nào được phân cụm là rất quan trọng.
- Các truy vấn phạm vi dường như được hưởng lợi nhiều nhất từ việc phân cụm. Nếu một số truy vấn phạm vi được đưa ra trên một quan hệ nào đó, lấy ra các tập thuộc tính khác nhau, hãy xem xét điều kiện lọc trong các truy vấn và tần suất thực hiện của chúng trong luồng công việc để đi đến quyết định chỉ mục nào được phân cụm.
- Nếu một chỉ mục nào đó được dùng trong một chiến lược đánh giá chỉ-chỉ-số, thì chỉ mục này không cần phân cụm. (Chỉ phân cụm khi chỉ mục này được sử dụng để truy cập các bộ giá trị ở các quan hệ nằm phía dưới).
Chỉ mục băm hay chỉ mục cây (Hướng dẫn 5): Chỉ mục B+tree thường tốt hơn cho các truy vấn miền và truy vấn bằng. Chỉ mục băm là tốt hơn trong những trường hợp sau:
- Chỉ mục được hy vọng sẽ hỗ trợ nối lặp lồng nhau chỉ mục; quan hệ chỉ mục là quan hệ phía trong, và khoá tìm kiếm chứa các cột có tính năng kết nối.
- Luồng công việc có một truy vấn bằng rất quan trọng chứa các thuộc tính khoá tìm kiếm, và không có các truy vấn phạm vi.
Cân đối với giá phải trả để duy trì chỉ mục (Hướng dẫn 6): Khi đưa ra quyết định tạo chỉ mục, chúng ta phải cân nhắc ảnh hưởng của mỗi chỉ mục đối với việc cập nhật trong các luồng công việc.
- Nếu việc duy trì một chỉ mục nào đó làm chậm đi các phép toán cập nhật thường xuyên thì chúng ta phải xem xét để xoá chỉ mục này.
- Tuy nhiên, việc thêm một chỉ mục nào đó có thể làm tăng tốc độ thực hiện của một phép cập nhật. Ví dụ, một chỉ mục trên Emloyee IDs có thể làm tăng tốc độ của việc tăng lương cho một nhân viên nào đó (được xác định bằng ID).
Các ví dụ cơ bản của việc chọn chỉ mục
Các ví dụ sau minh hoạ cách lựa chọn chỉ mục trong quá trình thiết kế cơ sở dữ liệu, tiếp tục với những tranh luận trong Chương 8, nơi chúng ta đã tập trung bàn về lựa chọn chỉ mục đối với các truy vấn trên một bảng đơn. Lược đồ được sử dụng trong các ví dụ sau không được biểu diễn một cách chi tiết, chúng chỉ chứa tên các thuộc tính. Các thông tin bổ sung được biểu diễn khi cần thiết.
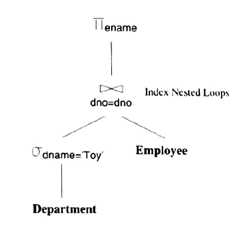
Hãy cùng chúng tôi bắt đầu với một ví dụ đơn giản:
SELECT E.ename, D.mgr
FROM Employees E, Departments D
WHERE D.dname= ‘Toy’ AND E.dno=D.dno
Các quan hệ được đề cập trong truy vấn này là Employees và Departments, và cả hai điều kiện trong mệnh đề WHERE đều là điều kiện bằng. Những hướng dẫn chúng ta đã nghiên cứu ở trên khuyên chúng ta nên xây dựng một chỉ mục băm trên thuộc tính dname của quan hệ Departments. Nhưng cân nhắc đến điều kiện bằng E.dno=D.dno, chúng ta nên xây dựng một chỉ mục (tất nhiên là chỉ mục băm) trên thuộc tính dno của Departments hoặc Employees (hoặc cả hai)? Thực chất chúng ta muốn truy cập các bộ giá trị trong Departments sử dụng chỉ mục trên dname vì chỉ có một vài bộ giá trị thoả mãn điều kiện D.dname=‘Toy’. Với mỗi bộ giá trị Departments thoả mãn, chúng ta tìm các bộ giá trị tương ứng trong Employees bằng việc sử dụng một chỉ mục trên thuộc tính dno của Employees. Vì thế, chúng ta nên xây dựng một chỉ mục trên trường dno của Employees. (Ghi nhớ rằng chẳng có ích lợi gì khi xây dựng một chỉ mục nữa trên trường dno của Departments vì các bộ giá trị Departments được truy cập sử dụng chỉ mục dname).
Việc lựa chọn chỉ mục được định hướng bởi kế hoạch đánh giá truy vấn mà chúng ta muốn sử dụng. Quá trình lựa chọn kế hoạch đánh giá truy vấn sẽ được thực hiện cùng với lựa chọn thiết kế vật lý vì tối ưu hoá truy vấn thực sự rất hữu ích cho thiết kế vật lý. Chúng tôi chỉ ra một kế hoạch tốt đối với truy vấn này trong Hình 1.
Xem xét một thay đổi của truy vấn này, giả sử rằng mệnh đề WHERE được sửa thành WHERE D.dname = ‘Toy’ AND E.dno=D.dno AND E.age=25. Hãy cùng chúng tôi xem xét một số kế hoạch khác. Một kế hoạch tốt ở đây là truy cập các bộ giá tri trong Departments thoả mãn điều kiện chọn của dname, sau đó truy cập các bộ giá trị tương ứng trong Employees bằng cách sử dụng một chỉ mục trên trường dno; phép chọn trên age sau đó được áp dụng theo kiểu on-the-fly. Tuy nhiên, không như những thay đổi trước của truy vấn này, chúng ta không thực sự cần có một chỉ mục trên trường dno của Employees nếu chúng ta có một chỉ mục nào đó trên trường age. Trong trường hợp này chúng ta có thể truy cập các bộ giá trị của Departments thoả mãn điều kiện chọn trên dname (bằng việc sử dụng chỉ mục trên dname, như phần trước), truy cập các bộ giá trị của Employees thoả mãn điều kiện chọn trên age sử dụng chỉ mục trên age, và kết nối những tập giá trị này lại. Vì các tập giá trị chúng ta nối lại là nhỏ, nên chúng có thể nằm vừa trong bộ nhớ và việc xem xét cách thức kết nối không còn quan trọng nữa. Kế hoạch này dường như không tốt như kế hoạch sử dụng một chỉ mục trên dno, nhưng nó cũng là một lựa chọn hợp lý. Vì thế, nếu chúng ta đã có một chỉ mục trên age (đã được sử dụng trong một truy vấn nào đó trong luồng công việc), thì chúng ta nên sử dụng chỉ mục này.
Truy vấn tiếp theo của chúng ta có chứa một điều kiện chọn phạm vi:
SELECT E.ename, D.dname
FROM Employees E, Departments D
WHERE E.sal BETWEEN 10000 AND 20000 AND E.hobby='Stamps'
AND E.dno=D.dno
10000 < E.sal AND E.sal < 20000
Người ta khuyến khích sử dụng phép toán BETWEEN để biểu diễn các điều kiện phạm vi vì nó dễ dàng cho cả người dùng và cả bộ tối ưu hoá.
Trở lại với ví dụ truy vấn này, cả hai điều kiện chọn đều ở trên quan hệ Employees. Vì thế, dễ dành nhận ra rằng kế hoạch tốt nhất trong trường hợp này là Employees sẽ đóng vai trò là quan hệ phía ngoài và Departments là quan hệ phía trong giống như trong truy vấn trước, và chúng ta nên xây dựng một chỉ mục băm trên thuộc tính dno của Departments. Nhưng chỉ mục nào trên Employees là tốt nhất? Một chỉ mục B+tree trên thuộc tính sal sẽ phù hợp với phép chọn phạm vi, đặc biệt nếu nó là một chỉ mục được phân cụm. Một chỉ mục băm trên thuộc tính hobby sẽ phù hợp với điều kiện chọn bằng. Nếu một trong những chỉ mục này đang sẵn sàng, thì chúng ta có thể truy cập các bộ giá trị trong Employees bằng cách sử dụng chỉ mục này, truy cập các bộ giá trị tương ứng trong Departments sử dụng chỉ mục trên dno, và thực hiện tất cả các điều kiện chọn còn lại và các phép chiếu theo kiểu on-the-fly. Nếu cả hai chỉ mục này đang sẵn sàng, bộ tối ưu hoá sẽ lựa chọn chỉ mục thích hợp hơn để thực hiện truy vấn, tức là nó sẽ xem xét điều kiện chọn nào (điều kiện chọn phạm vi trên salary hoặc điều kiện chọn bằng trên hobby) có ít bộ giá trị thoả mãn hơn. Nói chung, chỉ mục nào thích hợp hơn tuỳ thuộc vào dữ liệu. Nếu có rất ít người có salary nằm trong phạm vi đã cho và có rất nhiều người có sở thích là stamps thì chỉ mục B+tree là lựa chọn tốt nhất. Ngược lại, chỉ mục băm trên hobby là tốt nhất.
Chỉ mục hoá và phân cụm
Các chỉ mục phân cụm có thể trở nên đặc biệt quan trọng trong khi truy cập các quan hệ phía trong của một nối lặp lồng nhau chỉ mục nào đó. Để hiểu được mối quan hệ giữa các chỉ mục phân cụm và các liên kết, hãy cùng chúng tôi xem lại ví dụ đầu tiên của chúng ta:
SELECT E.ename, D.mgr
FROM Employees E, Departments D
WHERE D.dname= ‘Toy’ AND E.dno=D.dno
Chúng ta đã kết luận rằng một kế hoạch tốt để thực hiện truy vấn này là sử dụng một chỉ mục trên dname để truy cập các bộ giá trị trong Departments thoả mãn điều kiện trên dname và tìm những bộ giá trị tương ứng của Employees sử dụng chỉ mục trên dno.
Các chỉ mục này có nên được phân cụm?
Giả sử số lượng các bộ giá trị thoả mãn điều kiện D.dname= ‘Toy’ nhỏ, thì chúng ta nên xây dựng một chỉ mục phân cụm trên dname. Mặc khác, Employees là bảng phía trong của nối lặp lồng nhau chỉ mục và dno không phải là khoá dự tuyển. Trường hợp này rất nên sử dụng chỉ mục phân cụm trên trường dno của Employees. Thực tế vì liên kết này chứa các phép chọn bằng lặp đi lặp lại trên trường dno của quan hệ phía trong, truy vấn kiểu này được khuyến khích là tạo ra một chỉ phân cụm trên trường dno hơn là kiểu truy vấn đơn giản trên trường hobby như trong ví dụ trước. (Tất nhiên, hai yếu tố là dữ liệu nào cần được lấy ra (phép lọc) và tần số của truy vấn cũng phải được đưa vào xem xét.)
Ví dụ tiếp theo cũng tự như ví dụ trước, minh hoạ các chỉ mục phân cụm được sử dụng như thế nào trong các liên kết sắp-xếp-trộn (sort-merge joins):
SELECT E.ename, D.mgr
FROM Employees E, Departments D
WHERE E.hobby='Stamps' AND E.dno=D.dno
Truy vấn này khác với truy vấn trước ở chỗ điều kiện E.hobby = ‘Stamps’ thay thế D.dname ='Toy'. Dựa trên giả thiết rằng chỉ có một vài nhân viên trong phòng ‘Toy’, chúng ta đã lựa chọn các chỉ mục phù hợp với phép nối lặp lồng nhau chỉ mục cùng với Departments là quan hệ phía ngoài. Bây giờ, hãy cùng chúng tôi giả sử rằng có rất nhiều nhân viên có sở thích là stamps. Trong trường hợp này, một phép lặp lồng nhau trên khối hoặc nối sắp-xếp-trộn có lẽ hiệu quả hơn. Nối sắp-xếp-trộn có thể sử dụng các lợi thế của chỉ mục phân cụm B+tree trên thuộc tính dno của Departments để truy cập các bộ giá trị và do đó tránh phải sắp xếp bảng Departments. Lưu ý rằng nếu sử dụng chỉ mục không phân cụm sẽ không hiệu quả - vì tất cả các bộ giá trị sẽ được truy cập, việc thực hiện một thao tác I/O đối với mỗi bộ giá trị dường như phải trả giá quá đắt. Nếu không có chỉ mục trên trường dno của Employees, chúng ta có thể truy cập các bộ giá trị của Employees (có thể sử dụng một chỉ mục trên trường hobby, đặc biệt khi chỉ mục này được phân cụm), áp dụng phép lọc E.hobby='Stamps' theo kiểu on-the-fly, và sắp xếp những bộ giá trị thoả mãn theo trường dno.
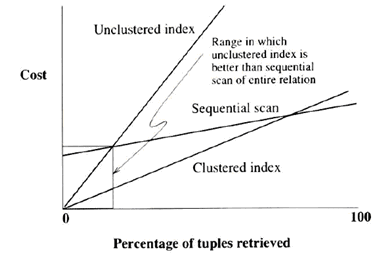
Những tranh luận của chúng ta chỉ ra rằng khi chúng ta truy cập các bộ giá trị sử dụng một chỉ mục nào đó, ảnh hưởng của việc phân cụm phụ thuộc vào số lượng các bộ giá trị được truy cập, tức là, số lượng các bộ giá trị thoả mãn các điều kiên chọn thích hợp với chỉ mục đó. Một chỉ mục không phân cụm chỉ tốt bằng một chỉ mục phân cụm khi phép chọn chỉ truy cập đến một bộ giá trị duy nhất (ví dụ, một phép chọn bằng trên một khoá dự tuyển). Khi số lượng các bộ giá trị được truy cập tăng lên, sử dụng chỉ mục không phân cụm phải trả giá đắt hơn vượt xa so với việc quét tuần tự toàn bộ quan hệ. Việc quét tuần tự truy cập toàn bộ các bộ giá trị, nhưng mỗi trang được truy cập chính xác một lần, trong khi đó mỗi trang có thể được truy cập nhiều lần bằng số lượng các bản ghi bên trong nó nếu chúng ta sử dụng một chỉ mục không phân cụm. Nếu blocked I/O được thực hiện (như phổ biến), những ưu điểm của quét tuần tự so với sử dụng chỉ mục không phân cụm tăng dần lên.
Chúng ta minh hoạ mối quan hệ giữa số lượng các bộ giá trị truy cập biểu diễn bằng tỷ lệ so với tổng số bộ giá trị có trong quan hệ, và giá của các phương pháp truy cập khác nhau trong Hình 2. Để đơn giản, chúng ta giả sử rằng truy vấn này là một phép chọn trên chỉ một quan hệ. (Hình này phản ánh giá của việc viết ra kết quả; và đường của quét tuần tự là một mặt phẳng.)
Đồng-phân-cụm hai quan hệ
Trong phần trình bày về kiến trúc hệ thống cơ sở dữ liệu ở Chương 9, chúng ta đã giải thích về một quan hệ được lưu trữ trong một file như thế nào. Mặc dù một file thường chỉ chứa các bản ghi của một quan hệ, nhưng một vài hệ thống cho phép các bản ghi của nhiều hơn một quan hệ được lưu trong một file. Với cách này, người dùng cơ sở dữ liệu có thể yêu cầu các bản ghi của hai quan hệ có thể được đặt cạnh nhau theo một quy luật tự nhiên. Cách sắp đặt dữ liệu như thế này đôi khi được nói tới như là đồng-phân-cụm của hai quan hệ. Bây giờ chúng ta bàn về vấn đề khi nào đồng-phân-cụm có thể mang lại lợi ích.
Ví dụ, xem xét hai quan hệ với lược đồ như sau:
Parts(pid: integer, pname: string, cost: integer, supplierid: integer)
Assembly(partid: integer, componentid: integer, quantity: integer)
Trong lược đồ này, trường componentid của Assembly (Sản phẩm kết hợp) tham chiếu tới pid của một Parts (Sản phẩm) nào đó. Vì thế, bảng Assembly biểu diễn mối liên kết 1:N giữa Parts và Subparts (Sản phẩm con) của nó; một sản phẩm có thể có nhiều sản phẩm con, nhưng mỗi sản phẩm là một sản phẩm con của nhiều nhất một sản phẩm. Trong bảng Parts, pid là khoá. Với các sản phẩm kết hợp (những sản phẩm được lắp giáp từ các sản phẩm khác, như nội dung của bảng Assembly chỉ ra), trường cost được tính từ giá của các sản phẩm con của nó.
Giả sử rằng có một truy vấn thường xuyên xảy ra là tìm ra (ngay lập tức) các sản phẩm con của tất cả các sản phẩm do một nhà sản xuất nào đó cung cấp:
SELECT P.pid, A.componentid
FROM Parts P, Assembly A
WHERE P.pid = A.partid AND P.supplierid = ‘Acme’
Một kế hoạch tốt để thực hiện truy vấn này là áp điều kiện chọn trên bảng Parts và sau đó truy cập các bản ghi phù hợp của Assembly thông qua một chỉ mục nào đó trên trường partid. Chỉ mục này trên partid nên được phân cụm là tốt nhất. Chúng tôi khẳng định kế hoạch này là tốt. Tuy nhiên, nếu chúng ta muốn tối ưu hoá chúng thêm nữa, thì chúng ta có thể đồng-phân-cụm trên hai bảng này. Với cách tiếp cận này, chúng ta sẽ lưu các bản ghi của hai bảng cùng với nhau, với mỗi bản ghi Part(P) sẽ có tất cả các bản ghi của Assembly(A) thoả mãn P.pid = A.partid theo sau. Cách tiếp cận này cải thiện được việc lưu trữ hai quan hệ tách rời nhau và việc có một chỉ mục phân cụm trên partid bởi vì nó không cần một chỉ mục giúp tìm ra các bản ghi ở Assembly tương ứng với một bản ghi nào đó của Parts. Vì thế, với mỗi truy vấn, chúng ta ghi lại một vài (điển hình là hai hoặc ba) trang chỉ mục I/Os.
Nếu chúng ta quan tâm đến việc tìm ra các sản phẩm con của tất cả các sản phẩm ngay lập tức (tức là, truy vấn trước không có điều kiện chọn trên supplierid),việc tạo ra một chỉ mục phân cụm trên partid và thực hiện một nối lặp lồng nhau chỉ mục trong đó Assembly là quan hệ phía trong được coi là một kế hoạch tốt. Thậm chí có một chiến lược tốt hơn nữa là tạo ra một chỉ mục phân cụm trên trường partid của Assembly và trường pid của Parts, sau đó thực hiện một sắp-xếp-trộn, sử dụng các chỉ mục để truy cập các bộ giá trị theo thứ tự được sắp. Chiến lược này có thể so sánh được với việc sử dụng đồng-phân-cụm, cách mà chỉ việc quét trên tập các bản ghi (của Parts và Assembly, nơi lưu trữ cùng nhau theo cơ chế xen lẫn).
Lợi ích thực sự của đồng-phân-cụm được minh hoạ trong truy vấn sau:
SELECT P.pid, A.componentid
FROM Parts P, Assembly A
WHERE P.pid = A.partid AND P.cost=10
Giả sử rằng có rất nhiều Part có cost=10. Truy vấn này về bản chất sẽ đưa ra một tập các bản ghi của Parts và các bản ghi tương ứng của Assembly. Nếu chúng ta có một chỉ mục nào đó trên trường cost của Parts, chúng ta có thể truy cập các bộ giá trị thoả mãn của Parts. Với mỗi bộ giá trị, chúng ta phải sử dụng chỉ mục này trên Assembly để xác định vị trí các bản ghi có pid đã biết. Nếu chúng ta sử dụng tổ chức đồng-phân-cụm chúng ta có thể tránh được chỉ mục này trên Assembly. (Tất nhiên, vẫn cần một chỉ mục trên thuộc tính cost của Parts).
Như vậy tối ưu hoá đặc biệt quan trọng khi chúng ta muốn duyệt qua một vài mức của phân cấp sản phẩm-sản phẩm con (part-subpart). Ví dụ, một truy vấn phổ biến là tìm tổng giá thành của một sản phẩm nào đó, truy vấn này yêu cầu chúng ta thực hiện lặp đi lặp lại kết nối giữa Parts và Assembly. Thêm nữa, chúng ta có thể không biết số lượng các mức trong phân cấp, số lượng các kết nối khác nhau và truy vấn này không thể được biểu diễn trong SQL. Truy vấn này có thể được thực hiện bằng cách kết hợp sử dụng ngôn ngữ lập trình. Như vậy, đồng-phân-cụm mang lại những lợi ích đặc biệt trong trường hợp một kết nối nào đó thường xuyên được thực hiện.
Tổng kết về đồng-phân-cụm:
- Nó có thể làm tăng tốc độ các kết nối, cụ thể là các kết nối khoá-khoá ngoại tương ứng với mối liên kết 1:N:
- Việc quét tuần tự một trong hai quan hệ trở nên chậm hơn. (Trong ví dụ của chúng ta, vì một số bộ giá trị của Assembly được lưu trữ giữa các bộ giá trị Parts kề nhau, nên việc quét tất cả các bộ giá trị của Parts trong trường hợp này chậm hơn khi nó được lưu trữ tách rời. Tương tự, việc quét tuần tự tất cả các bộ giá trị của Assembly cũng chậm hơn).
- Tất cả các thao tác thêm, xoá, và cập nhật làm biến đổi chiều dài bản ghi cũng chậm hơn do phải duy trì việc phân cụm. (Chúng ta không bàn về các vần đề thực thi của đồng-phân-cụm ở đây).
Các chỉ mục có thể sử dụng trong kế hoạch chỉ-chỉ-số
Phần này xem xét một số truy vấn mà chúng ta có thể tìm ra được các kế hoạch thực hiện chúng hiệu quả hơn bằng cách tránh truy cập các bộ giá trị trong các quan hệ tham chiếu; kế hoạch này sẽ quét một chỉ mục liên quan nào đó (chỉ mục này dường như nhỏ hơn nhiều). Chỉ mục được sử dụng chỉ trong việc quét chỉ-chỉ-số không phải phân cụm vì các bộ giá trị trong quan hệ chỉ mục này không cần được truy cập.
Truy vấn này đưa ra các người quản lý của các phòng/ban có ít nhất một nhân viên:
SELECT D.mgr
FROM Departments D, Employees E
WHERE D.dno=E.dno
Quan sát thấy rằng không có thuộc tính nào của Employees được giữ lại. Nếu chúng ta có một chỉ mục nào đó trên trường dno của Employees, chúng ta nên thực hiện một nối lặp lồng nhau chỉ mục sử dụng quét chỉ-chỉ-số cho quan hệ phía bên trong. Trong trường hợp này, xây dựng một chỉ mục không phân cụm trên trường dno của Employees sẽ tốt hơn một chỉ mục phân cụm.
Truy vấn tiếp theo thực hiện ý tưởng này ở mức cao hơn:
SELECT D.mgr, E.eid
FROM Departments D, Employees E
WHERE D.dno=E.dno
Nếu chúng ta có một chỉ mục nào đó trên trường dno của Employees, chúng ta có thể sử dụng nó để truy cập các bộ giá trị của Employees trong quá trình kết nối (cùng với Departments là quan hệ phía bên ngoài), nhưng nếu chỉ mục này không được phân cụm thì cách tiếp cận này sẽ không hiệu quả. Mặc khác, giả sử chúng ta có một chỉ mục B+tree trên (dno, eid). Bây giờ tất cả thông tin chúng ta cần về một bộ giá trị nào đó của Employees đều chứa trong cổng vào dữ liệu của bộ giá trị đó trong chỉ mục này. Chúng ta có thể sử dụng chỉ mục này để tìm ra cổng vào dữ liệu đầu tiên có dno đã cho; tất cả các cổng vào dữ liệu có cùng giá trị dno được lưu trữ cùng nhau trong chỉ mục này. (Ghi nhớ rằng một chỉ mục băm trên khoá (dno, eid) không thể được sử dụng để xác định vị trí của một entry có dno nào đó). Vì thế, chúng ta có thể thực hiện được truy vấn này sử dụng nối lặp lồng nhau chỉ mục với Departments là quan hệ phía ngoài và quét chỉ-chỉ mục của quan hệ phía trong.
Các công cụ hỗ trợ việc lựa chọn chỉ mục
Số lượng các chỉ mục tiềm năng rất lớn: Với mỗi quan hệ, chúng ta có thể xem xét tất cả các tập con các thuộc tính như là một chỉ mục khoá; chúng ta phải quyết định thứ tự của các thuộc tính trong chỉ mục này; và chúng ta cũng phải quyết định xem chỉ mục này có nên phân cụm hay không phân cụm. Rất nhiều các ứng dụng lớn- việc tạo ra hàng chục ngàn các quan hệ khác nhau và việc lựa chọn thủ công các chỉ mục là việc làm không khả thi.
Sự quan trọng của chỉ mục và những khó khăn trong lựa chọn chỉ mục đã dẫn đến việc phải phát triển các công cụ để hỗ trợ người quản trị cơ sở dữ liệu lựa chọn được chỉ mục thích hợp cho từng luồng công việc. Đầu tiên là công cụ hỗ trợ lựa chọn chỉ mục - index tuning wizards, hay còn gọi là cố vấn chỉ mục - index advisors, là các công cụ tách biệt bên ngoài database engine; chúng đề nghị các chỉ mục nào nên được xây dựng cho từng luồng công việc với các truy vấn SQL khác nhau. Hạn chế chính của những hệ thống này là phải sao chép lại mô hình lượng giá tối ưu hoá truy vấn để đảm bảo rằng bộ tối ưu hoá sẽ chọn các kế hoạch đánh giá truy vấn giống với công cụ thiết kế. Vì bộ tối ưu hoá truy vấn luôn thay đổi trong từng phiên bản của hệ thống cơ sở dữ liệu thương mại, nên rất cần tích hợp công cụ hỗ trợ lựa chọn chỉ mục với bộ tối ưu hoá cơ sở dữ liệu. Sự ra đời gần đây nhất của công cụ này đã được tích hợp với database engine và sử dụng sử dụng bộ tối ưu hoá truy vấn để ước lượng giá của một luồng công việc cùng với tập các chỉ mục của nó, tránh được việc phải sao chép lại như ở trên.
Lựa chọn chỉ mục tự động
Chúng ta gọi tập các chỉ mục của một lược đồ cơ sở dữ liệu là một cấu hình chỉ mục. Giả sử rằng một luồng truy vấn là một tập các truy vấn trên một lược đồ cơ sở dữ liệu. Cho một lược đồ cơ sở dữ liệu và một luồng công việc, giá của một cấu hình chỉ mục là giá phải trả để thực thi những truy vấn này. Cho một lược đồ cơ sở dữ liệu và một luồng truy vấn, bây giờ chúng ta có thể định nghĩa vấn đề lựa chọn chỉ mục tự động chính là việc tìm ra một cấu hình chỉ mục có giá thành thực thi nhỏ nhất.
Vì sao lựa chọn chỉ mục tự động là một vấn đề khó? Hãy cùng chúng tôi tính toán số lượng các chỉ mục khác nhau cùng với c thuộc tính, giả sử rằng bảng này có n thuộc tính. Với thuộc tính đầu tiên trong chỉ mục này, có n lựa chọn, với thuộc tính thứ hai có n-1 thuộc tính, vì thế với thuộc tính thức ta sẽ có lựa chọn. Tổng số các chỉ mục khác nhau với c thuộc tính là:
Với một bảng có 10 thuộc tính sẽ có 10 chỉ mục khác nhau có 1 thuộc tính, 90 chỉ mục khác nhau có hai thuộc tính, và 30240 chỉ mục khác nhau có 5 thuộc tính. Với các luồng công việc phức tạp bao gồm hàng trăm bảng, số lượng các cấu hình chỉ mục rõ ràng sẽ rất lớn.
Hiệu quả của các công cụ lựa chọn chỉ mục tự động có thể được đánh giá bởi hai yếu tố: (1) số lượng các cấu hình chỉ mục dự tuyển được xem xét, và (2) số lượng các bộ tối ưu cần gọi đến để ước lượng giá của một cấu hình. Ghi nhớ rằng việc giảm không gian tìm kiếm của các chỉ mục dự tuyển tương ứng với việc giới hạn không gian tìm kiếm của bộ tối ưu hoá truy vấn với các kế hoạch sâu-trái (deep-left). Trong rất nhiều trường hợp, kế hoạch tốt nhất không phải là kế hoạch sâu-trái, nhưng trong tất cả các kế hoạch sâu-trái thường có một kế hoạch có giá gần bằng kế hoạch tốt nhất.
Chúng ta có thể dễ dàng giảm thời gian lựa chọn chỉ mục tự động bằng cách giảm số lượng các cấu hình chỉ mục dự tuyển, hoặc chỉ xem xét các chỉ mục có một hoặc hai thuộc tính.
Lựa chọn chỉ mục tự động làm việc như thế nào?
Lựa chọn chỉ mục tự động tìm ra một tập các chỉ mục là ứng cử viên cho một cấu hình chỉ mục có chi phí thấp nhất. Chúng tôi trình bày một thuật toán tiêu biểu; những công cụ thực thi đang tồn tại là biến thể của thuật toán này, nhưng sự thực hiện của chúng có cùng cấu trúc cơ bản.
Trước khi trình bày thuật toán lựa chọn chỉ mục, chúng ta sẽ cùng xem xét vấn đề ước lượng giá của một cấu hình chỉ mục nào đó. Ghi nhớ rằng sẽ không khả thi nếu tạo ra một tập các chỉ mục cho một cấu hình ứng cử viên và sau đó tối ưu truy vấn dựa vào các cấu hình này. Việc tạo ra dù chỉ một cấu hình ứng cử viên có một vài chỉ mục cũng có thể mất hàng giờ đối với các cơ sở dữ liệu lớn. Vì thế, kiểm tra một số lượng lớn các cấu hình ứng cử viên có khả năng là cách tiếp cận không khả thi.
Bây giờ chúng tôi trình bày một thuật toán lựa chọn chỉ mục điển hình. Thuật toán này có hai bước, lựa chọn chỉ mục ứng cử viên và liệt kê cấu hình. Trong bước đầu tiên, chúng ta lựa chọn một tập các chỉ mục ứng cử viên để xem xét trong toàn bộ bước hai, sau đó bước hai sẽ xây dựng các khối của các cấu hình chỉ mục. Hãy cùng chúng tôi trình bày hai bước này chi tiết hơn.
Cố vấn chỉ mục của DB2. Cố vấn chỉ mục của DB2 là một công cụ giúp đề cử các chỉ mục một cách tự động cho một luồng công việc. Luồng công việc này được lưu trữ trong một bảng gọi là ADVISE_WORKLOAD của hệ thống cơ sở dữ liệu. Cố vấn chỉ mục của DB2 cho phép người dùng chỉ định dung lượng tối đa của khoảng trống đĩa cho các chỉ mục mới và khoảng thời gian tối đa cho việc tính toán một cấu hình chỉ mục.
Cố vấn chỉ mục của DB2 có một chương trình giúp tìm kiếm tập con của các cấu hình chỉ mục một cách thông minh. Cho một cấu hình chỉ mục ứng cử viên, nó gọi tới bộ tối ưu hoá truy vấn ứng với mỗi truy vấn trong bảng ADVISE_WORKLOAD ở chế độ RECOMMEND_INDEXES, ở chế độ này bộ tối ưu hoá đề cử một tập các chỉ mục và lưu chúng trong bảng ADVISE_INDEXES (các chỉ mục khuyên dùng). Trong chế độ EVALUATE_INDEXES, bộ tối ưu hoá đánh giá lợi ích của các cấu hình chỉ mục này ứng với mỗi truy vấn trong bảng ADVISE-WORKLOAD. Đầu ra của bước lựa chọn chỉ mục là các câu lệnh SQL DDL cho phép tạo ra các chỉ mục đề cử.
Chọn chỉ mục tự động của Microsoft SQL Server 2000. Microsoft là hãng đi tiên phong trong việc tích hợp chọn chỉ mục tự động với bộ tối ưu hoá truy vấn. Công cụ này có ba chế độ cho phép người dùng thoả thuận giữa thời gian phân tích và số lượng các cấu hình chỉ mục ứng cử viên được kiểm tra: nhanh, trung bình và trọn vẹn, trong đó cấu hình nhanh có thời gian phân tích ít nhất và cấu hình trọn vẹn có số lượng các cấu hình nhiều nhất. Các tham số khác bao gồm khoảng không tối đa cấp cho các chỉ mục đề cử, số lượng tối đa các thuộc tính của mỗi chỉ mục, và các bảng có thể sử dụng các chỉ mục này. Công cụ này cho phép co giãn bảng, người dùng có thể xác định số lượng các bản ghi của bảng sẽ cần trong luồng công việc. Điều này cho phép người dùng lập kế hoạch phát triển các bảng trong tương lai.
Lựa chọn chỉ mục ứng cử viên
Chúng ta đã nhìn thấy trong phần trước là không thể xem xét tất cả các chỉ mục có khả năng, do có một số lượng quá lớn các ứng cử viên chỉ mục trong một lược đồ cơ sở dữ liệu lớn. Một cách làm ở đây là tỉa không gian rất lớn các chỉ mục có khả năng của mỗi truy vấn trong luồng công việc một cách độc lập, sau đó phép hợp của các chỉ mục được chọn trong bước đầu tiên này sẽ là đầu vào của bước thứ hai.
Với một truy vấn, hãy cùng chúng tôi tìm hiểu về khái niệm của một thuộc tính có khả năng làm chỉ mục, đó là thuộc tính mà sự xuất hiện của nó trong một chỉ mục có thể làm thay đổi giá của truy vấn. Thuộc tính có khả năng làm chỉ mục là thuộc tính nằm trong mệnh đề WHERE của truy vấn có điều kiện hoặc trong mệnh đề GROUP BY hoặc ORDER BY của truy vấn SQL. Một chỉ mục có thể được chấp nhận cho một truy vấn nào đó là một chỉ mục chứa các thuộc tính có khả năng làm chỉ mục trong truy vấn đó.
Chúng ta chọn các chỉ mục ứng cử viên cho một truy vấn cụ thể nào đó như thế nào? Một cách tiếp cận là liệt kê tất cả các chỉ mục của k thuộc tính. Chúng ta bắt đầu với việc chọn tất cả các thuộc tính đơn đều là chỉ mục ứng cử viên, sau đó là sự kết hợp của hai chỉ mục, và lặp cho đến khi đạt đến kích thước k do người dùng định nghĩa. Thủ tục này rất tốn kém vì chúng ta sẽ có chỉ mục ứng cử viên. Những tài liệu tham khảo ở cuối chương này trình bày về các thuật toán tìm kiếm heuristical nhanh hơn (nhưng không trọn vẹn bằng).
Liệt kê các cấu hình chỉ mục
Trong bước thứ hai, chúng ta sử dụng các chỉ mục ứng cử viên để liệt kê các cấu hình chỉ mục. Như ở bước thứ nhất, chúng ta có thể liệt kê toàn bộ tất cả các cấu hình chỉ mục có kích thước k. Như trình bày ở phía trước, các chiến lược tìm kiếm phức tạp có thể làm giảm số lượng các cấu hình trong khi vẫn đưa ra được một cấu hình cuối cùng có chất lượng cao.
Tổng quan về điều chỉnh cơ sở dữ liệu
Sau khi thiết kế cơ sở dữ liệu được đưa vào sử dụng, quá trình sử dụng thực tế này cung cấp nhiều thông tin chi tiết đáng giá giúp chúng ta điều chỉnh thiết kế ban đầu sao cho nó trở nên hiệu quả hơn. Rất nhiều giả định ban đầu về các luồng công việc có trong ứng dụng có thể đúng, và một số có thể sai. Những ước lượng ban đầu của chúng ta về kích thước dữ liệu có thể được thay thế bằng các thống kê thực tế từ các danh mục hệ thống. Việc kiểm tra cẩn thận các truy vấn có thể giải quyết được những vấn đề không mong muốn; ví dụ, khi thực hiện các kế hoạch của truy vấn, bộ tối ưu hoá có lẽ không sử dụng một vài chỉ mục như ta mong đợi.
Tiếp tục điều chỉnh cơ sở dữ liệu là việc làm quan trọng để đạt được hiệu quả trong thực thi. Trong phần này, chúng tôi giới thiệu ba kiểu điều chỉnh: điều chỉnh các chỉ mục, điều chỉnh lược đồ khái niệm và điều chỉnh các truy vấn. Những tranh luận của chúng ta về lựa chọn chỉ mục cũng được áp dụng để đưa ra những quyết định điều chỉnh chỉ mục. Điều chỉnh lược đồ khái niệm và truy vấn được trình bày kỹ hơn trong Phần 8 và 9.
Điều chỉnh chỉ mục
Những lựa chọn chỉ mục ban đầu có thể phải điều chỉnh vì một số lý do. Lý do đơn giản nhất là luồng công việc chứa một số truy vấn và các cập nhật được coi là quan trọng trong thiết kế ban đầu nhưng trên thực tế nó lại không xuất hiện thường xuyên. Luồng công việc thực tế quan sát được bây giờ cũng có thể chứa một số truy vấn mới và các cập nhật quan trọng. Những lựa chọn chỉ mục ban đầu phải được điều chỉnh lại dựa vào những thông tin mới này. Một số chỉ mục ban đầu có thể phải xoá đi và thêm vào đó một số chỉ mục mới.
Chúng ta cũng khám phá ra rằng bộ tối ưu hoá trong một hệ thống nào đó không tìm ra được các kế hoạch như ta mong muốn. Ví dụ, xem xét truy vấn sau, truy vấn này chúng ta đã bàn luận ở trên:
SELECT D.mgr
FROM Employees E, Departments D
WHERE D.dname= ‘Toy’ AND E.dno=D.dno
Một kế hoạch tốt ở đây là sử dụng một chỉ mục trên dname để truy cập các bộ giá trị của Departments có dname ='Toy' và thực hiện quét chỉ-chỉ-số trên chỉ mục của trường dno của Employees. Chúng ta nhận thấy rằng bộ tối ưu hoá sẽ tìm ra được một kế hoạch như vậy, nên chúng ta có thể tạo ra một chỉ mục không phân cụm trên trường dno của Employees.
Bây giờ giả sử thực hiện các truy vấn dạng này mất một thời gian rất lâu. Chúng ta có thể yêu cầu hệ thống cho xem các kế hoạch mà bộ tối ưu hoá đã chọn. (Hầu hết các hệ thống thương mại cung cấp một lệnh đơn giản để làm điều này). Nếu các kế hoạch không sử dụng quét chỉ-chỉ-số (do những hạn chế của hệ thống gây ra), thì trừ phi những bộ giá trị của Employees đang được truy cập, còn không chúng ta phải xem xét lại việc lựa chọn chỉ mục ban đầu. Trong trường hợp này, chúng ta phải xoá chỉ mục không phân cụm trên trường dno của Employees và thay thế nó bằng một chỉ mục được phân cụm.
Một vài hạn chế phổ biến của các bộ tối ưu hoá là nó không thực hiện tốt các phép chọn có chứa các biểu thức xâu ký tự, số học, và các giá trị rỗng. Chúng ta sẽ bàn luận sâu hơn về vấn đề này trong nội dung điều chỉnh truy vấn ở Phần 9. Hơn nữa, việc kiểm tra lại các lựa chọn chỉ mục có thể giúp chúng ta tổ chức lại một số chỉ mục trước. Ví dụ, một chỉ mục tĩnh, như chỉ mục ISAM có thể sinh ra các chuỗi tràn dài. Việc xoá các chỉ mục này và xây dựng lại nó- nếu khả thi, cung cấp các truy cập ngắt quãng tới quan hệ được chỉ mục- do đó có thể cải thiện được thời gian truy cập thông qua chỉ mục này. Đối với cấu trúc động như là B+tree, nếu quá trình thực thi không tiến hành trộn các trang đã bị xoá, không gian bị chiếm có thể tăng lên đáng kể trong một số trường hợp. Điều này làm kích thước của chỉ mục này (trong các trang) lớn hơn cần thiết, và có thể làm tăng thời gian truy cập. Việc xây dựng lại chỉ mục này nên được xem xét. Các phép cập nhật phạm vi tới một chỉ mục phân cụm nào đó có lẽ cùng dẫn đến phải sử dụng các trang tràn, vì thế chúng ta nên cố gắng giảm bậc của phân cụm. Khẳng định thêm một lần nữa, việc xây dựng lại chỉ mục là việc nên làm.
Cuối cùng, ghi nhớ rằng tối ưu hoá truy vấn được cân nhắc dựa vào các thống kê thực tế trong các danh mục hệ thống. Những thống kê này được cập nhật chỉ khi một chương trình tiện ích đặc biệt đang chạy; vì thế phải đảm bảo rằng các tiện ích này được chạy một cách thường xuyên đủ để duy trì những thống kê này một cách hợp lý.
Điều chỉnh lược đồ khái niệm
Trong các khoá học về thiết kế cơ sở dữ liệu, chúng ta đã được biết rằng lược đồ quan hệ được xây dựng ban đầu có thể không phù hợp với các mục đích thực thi của các luồng công việc. Vì thế, chúng ta có thể phải thiết kế lại lược đồ khái niệm (và những quyết định liên quan đến thiết kế vật lý cũng phải kiểm tra lại).
Chúng ta cũng biết rằng việc thiết kế lại là cần thiết trong suốt quá trình thiết kế ban đầu hoặc sau đó, khi mà hệ thống đã đi vào sử dụng. Khi một cơ sở dữ liệu đã được thiết kế và đã có chứa dữ liệu, việc thay đổi lược đồ khái niệm dẫn đến việc phải thay đổi nội dung của các quan hệ có liên quan. Bây giờ chúng ta xem xét các vấn đề của thiết kế lại lược đồ đứng trên quan điểm thực thi.
Một điểm quan trọng cần hiểu là việc lựa chọn lược đồ khái niệm nên dựa vào việc xem xét các truy vấn và các cập nhật nào có trong luồng công việc của chúng ta, và các vấn đề liên quan đến dư thừa dữ liệu (chúng ta đã bàn đến trong Chương 19). Có một số công việc phải được xem xét trong khi tiến hành điều chỉnh lược đồ khái niệm:
- Chúng ta cân nhắc xem các quan hệ nên ở 3NF thay vì BCNF không.
- Nếu có hai cách để phân rã một lược đồ quan hệ về 3NF hoặc BCNF, lựa chọn cách nào sẽ phụ thuộc vào các luồng công việc.
- Đôi khi chúng ta có lẽ muốn tiếp tục phân rã một quan hệ đã ở BCNF.
- Trong những trường hợp khác, chúng ta có lẽ muốn thực hiện phi chuẩn. Tức là, chúng ta thay thế một tập các quan hệ đã được phân rã từ một quan hệ lớn hơn bằng chính quan hệ ban đầu (khi chưa phân rã), mặc dù như vậy có thể phải chấp nhận các vấn đề dư thừa. Thêm nữa, chúng ta có lẽ lựa chọn việc thêm một số trường vào quan hệ hiện tại để tăng tốc độ một số truy vấn quan trọng, mặc dù điều này sẽ dẫn đến việc lưu trữ dư thừa thông tin (và cuối cùng là lược đồ này không ở 3NF cũng không ở BCNF).
- Những trình bày về chuẩn hoá này đã được nói đến như là công nghệ phân rã, tức là phân chia một quan hệ theo chiều dọc. Công nghệ khác cũng đã được đề cập là phân rã quan hệ theo chiều ngang, công nghệ này sẽ tạo ra hai quan hệ có cùng lược đồ. Lưu ý rằng ở đây chúng ta không nói về việc phân chia vật lý một quan hệ nào đó; mà là chúng ta muốn tạo ra hai quan hệ riêng biệt (có thể chứa các ràng buộc và các chỉ mục khác nhau trên mỗi quan hệ).
Thêm nữa, khi chúng ta thiết kế lại lược đồ khái niệm, đặc biệt nếu chúng ta điều chỉnh một lược đồ cơ sở dữ liệu đang tồn tại, việc xem xét xem chúng ta có nên tạo lại các khung nhìn cho người dùng là nên làm. Chúng tôi trình bày những lựa chọn của điều chỉnh lược đồ khái niệm trong Phần 8.
Điều chỉnh truy vấn và khung nhìn
Nếu thấy truy vấn đang chạy chậm hơn mong muốn, thì chúng ta nên kiểm tra lại truy vấn một cách cẩn thận để tìm ra nguyên nhân. Đôi khi viết lại truy vấn cùng với việc thực hiện một số điều chỉnh chỉ mục có thể giải quyết được vấn đề này. Tương tự, điều chỉnh có thể được thực hiện nếu các truy vấn trên một số khung nhìn chạy chậm hơn mong muốn. Chúng tôi không bàn về điều chỉnh khung nhìn một cách tách biệt mà xem xét các truy vấn trong các khung nhìn đó và tìm cách điều chỉnh chúng.
Khi điều chỉnh một truy vấn, điều đầu tiên là kiểm tra xem hệ thống có sử dụng các kế hoạch thực hiện nó như bạn mong muốn không. Có thể vì nhiều lý do mà hệ thống không tìm được kế hoạch tốt nhất. Một vài trường hợp sau đây không được nhiều bộ tối ưu hoá quản lý hiệu quả:
- Truy vấn có một điều kiện chọn bao gồm các giá trị rỗng.
- Các điều kiện chọn bao gồm các biểu thức số học, xâu ký tự hoặc các điều kiện chọn sử dụng phép OR. Ví dụ, nếu chúng ta có một điều kiện chọn là E.age = 2*D.age trong mệnh đề WHERE, bộ tối ưu hoá có thể sử dụng một cách đúng đắn chỉ mục trên E.age nhưng sử dụng không đúng chỉ mục trên D.age. Thay thế điều kiện này bằng điều kiện E.age/2 = D.age sẽ giải quyết được vấn đề này.
- Không có khả năng nhận ra một kế hoạch phức tạp như quét chỉ-chỉ-số trên một truy vấn có mệnh đề GROUP BY. Tất nhiên, hầu như không có bộ tối ưu nào tìm kiếm các kế hoạch bên ngoài các kế hoạch đã trình bày trong Chương 12 và 15, như là các cây liên kết sâu-không-trái (nonleft-deep join trees). Vì thế, việc quan trọng là phải hiểu được các bộ tối ưu hoá điển hình sẽ thực hiện những gì. Thêm nữa, tốt hơn nữa là bạn cũng nên tìm hiểu về những ưu điểm và hạn chế của hệ thống mà bạn sử dụng.
Nếu bộ tối ưu hoá không đủ thông minh để tìm ra được kế hoạch tốt nhất (sử dụng các phương thức truy cập và các chiến lược đánh giá do DBMS hỗ trợ), một vài hệ thống cho phép người dùng hướng dẫn việc chọn kế hoạch bằng việc cung cấp các lời gợi ý cho bộ tối ưu hoá; ví dụ, người dùng có thể yêu cầu sử dụng một chỉ mục cụ thể nào đó hoặc chọn thứ thự kết nối và phương thức kết nối. Tất nhiên, người dùng cung cấp các hướng dẫn cho bộ tối ưu phải là người có hiểu biết về cả tối ưu hoá và khả năng của DBMS mà mình sử dụng. Chúng ta sẽ bàn thêm về tối ưu hoá truy vấn trong Phần 9.
Các lựa chọn trong điều chỉnh lược đồ khái niệm
Bây giờ chúng ta minh hoạ các lựa chọn có thể có trong điều chỉnh lược đồ khái niệm thông qua một vài ví dụ sử dụng lược đồ sau:
Contracts(cid: integer, supplierid: integer, projectid: integer, deptid: integer, partid: integer, qty: integer, value: real)
Departments(did: integer, budget: real, annualreport: varchar)
Parts(pid: integer, cost: integer)
Projects(jid: integer, mgr: char(20))
Suppliers(sid: integer, address: char(50))
Để ngắn gọn, chúng ta chỉ viết tắt một thuộc tính nào đó bằng một ký tự. Xem xét lược đồ của quan hệ Contracts, lược đồ này được gọi tắt bằng CSJDPQV. Ý nghĩa của một bộ giá trị trong quan hệ này là: một hợp đồng (C) cùng với cid là sự thoả thuận của nhà cung cấp S (với sid bằng supplierid) sẽ cung cấp Q sản phẩm của mặt hàng P (với pid bằng partid) cho dự án J (với jid bằng projectid) quản lý bởi phòng D (với deptid bằng did), và giá trị V bằng value.
Có hai ràng buộc toàn vẹn đối với Contracts. Một dự án mua một mặt hàng nào đó sử dụng chỉ một hợp đồng; vì thế sẽ không có hai hợp đồng cho cùng một dự án mua cùng một mặt hàng. Ràng buộc này được biểu diễn bằng FD JP → C. Tương tự, một phòng nào đó mua nhiều nhất là một mặt hàng từ một nhà cung cấp. Ràng buộc này được biểu diễn bằng FD SD→P. Thêm nữa, tất nhiên là contract ID C là một khoá. Ý nghĩa của những quan hệ khác nên được làm rõ, và chúng ta không trình bày chi tiết ở đây vì chúng ta chỉ tập trung vào quan hệ Contracts.
Cân nhắc lựa chọn dạng chuẩn thấp hơn
Xem xét quan hệ Contracts. Có nên phân rã nó thành các quan hệ nhỏ hơn? Hãy cùng chúng tôi xem xem nó đang ở dạng chuẩn nào. Các khoá dự tuyển của quan hệ này là C và JP. (C là một khoá, và JP là phụ thuộc hàm xác định C). Chỉ có một phụ thuộc hàm không-khóa là SD→P, và P là thuộc tính prime vì nó là một phần của khoá dự tuyển JP. Vì thế, quan hệ này không ở BCNF- vì có một phụ thuộc hàm không-khóa, nhưng nó ở 3NF.
Bằng việc sử dụng phụ thuộc hàm SD→P để định hướng việc phân rã, chúng ta có hai lược đồ SDP và CSJDQV. Phân rã này không mất mát thông tin, nhưng nó không bảo toàn phụ thuộc hàm. Tuy nhiên, bằng cách thêm một lược đồ quan hệ là CJP, chúng ta sẽ có được phép phân rã thành BCNF không mất mát thông tin và bảo toàn phụ thuộc hàm. Sử dụng cách phân rã này là hiệu quả, chúng ta thay thế Contracts bằng ba lược đồ quan hệ là CJP, SDP, và CSJDQV.
Tuy nhiên, giả sử rằng truy vấn sau được yêu cầu thực hiện thường xuyên: Tìm số lượng các sản phẩm Q của mặt hàng P trong hợp đồng C. Truy vấn này yêu cầu kết nối hai quan hệ đã phân rã là CJP và CSJDQV (hoặc SDP và CSJDQV), ngược lại nó có thể được trả lời một cách trực tiếp sử dụng quan hệ Contracts. Giá phải trả cho truy vấn này sử dụng lược đồ quan hệ ở 3NF tốt hơn nhiều so với sử dụng các lược đồ ở BCNF.
Phi chuẩn hoá
Các lý do chính thúc đẩy lựa chọn dạng chuẩn thấp hơn dẫn chúng ta đến việc tìm hiểu mục này: một số dạng phi chuẩn. Như ví dụ trên, xem xét quan hệ Contracts- ở 3NF. Bây giờ, giả sử rằng có một truy vấn thường xuyên được yêu cầu là kiểm tra giá trị của một hợp đồng xem có thấp hơn số tiền mà Phòng đặt hàng đang có trong ngân quỹ không. Chúng ta có thể quyết định để thêm một trường là ngân sách (bugget) B cho quan hệ Contracst. Vì did là một khóa của Departments, bây giờ chúng ta có một phụ thuộc hàm là D → B trong Contracts, như vậy là Contracts không còn ở 3NF nữa. Tuy nhiên, chúng ta có thể quyết định thiết kế ở dạng này nếu mục đích về hiệu quả thực thi được đặt cao hơn. Như vậy quyết định này mang tính chủ quan và nó làm cho dư thừa dữ liệu tăng lên đáng kể.
Lựa chọn của việc phân rã
Xem xét lại quan hệ Contracts. Có một số lựa chọn có thể được sử dụng để giải quyết dư thừa trong quan hệ này:
- Chúng ta có thể cho phép quan hệ Contracts ở dạng chuẩn ba và chấp nhận dư thừa sẽ tốt hơn là đưa quan hệ về BCNF.
- Chúng ta có thể quyết định rằng chúng ta không muốn có những dị thường dữ liệu sinh ra do dư thừa, vì thế chúng ta phân rã Contracts thành các quan hệ ở BCNF sử dụng một trong những cách sau:
- Thực hiện một phân rã không mất kết nối chia quan hệ Contracts thành hai quan hệ PartInfo có các thuộc tính SDP và quan hệ Contractlnfo có các thuộc tính CSJDQV. Như đã nói ở trên, phân rã này không bảo toàn phụ thuộc hàm, và để có được điều này chúng ta sẽ phải thêm vào một quan hệ thứ ba là CJP, mục đích duy nhất của việc thêm quan hệ này là để bảo toàn phụ thuộc hàm JP→ C.
- Chúng ta có thể chọn cách thay thế quan hệ Contracts bằng hai quan hệ PartInfo và ContractInfo ngay cả khi việc phân rã này không bảo toàn phụ thuộc hàm.
Việc thay thế Contracts chỉ bằng PartInfo và ContractInfo không ngăn cản chúng ta thiết lập được ràng buộc JP → C. Chúng ta có thể tạo ra một xác nhận bằng SQL-92 để kiểm tra ràng buộc này như sau:
CREATE ASSERTION checkDep
CHECK ( NOT EXISTS
( SELECT *
FROM PartInfo PI, ContractInfo CI
WHERE PI.supplierid=CI.supplierid
AND CI.deptid=Cl.deptid
GROUP BY CI.projectid, PI.partid
HAVING COUNT (cid) > 1 ) )
Xác nhận này có hiệu quả cao vì nó bao gồm một liên kết đằng sau một sắp xếp. Hệ thống có thể kiểm tra JP là một khoá chính của quan hệ CJP bằng cách duy trì một chỉ mục trên JP. Giá để xác nhận ràng buộc này rẻ hơn so với giá duy trì phụ thuộc hàm. Mặt khác, nếu các phép cập nhật thường xuyên xảy ra, giá phải trả cho việc thực hiện nó có thể chấp nhận được; vì thế, chúng ta có lẽ không nên duy trì bảng CJP (và tất nhiên là cả chỉ mục trên nó).
Một ví dụ khác minh hoạ các lựa chọn khi phân rã, xem xét lại quan hệ Contracts, và giả sử chúng ta có một ràng buộc toàn vẹn là SPQ→ V.
Tiếp tục phía trên, chúng ta có một phân rã không mất kết nối của quan hệ Contracts thành SDP và CSJDQV. Chúng ta có thể bắt đầu bằng việc sử dụng phụ thuộc hàm SPQ → V để định hướng phân rã, và thay thế Contracts bằng SPQV và CSJDPQ. Sau đó chúng ta có thể phân rã CSJDPQ thành SDP và CSJDQ do có phụ thuộc hàm SD → P.
Bây giờ chúng ta có hai lựa chọn phân rã không mất kết nối thành BCNF cho quan hệ Contracts, không có cách nào trong hai lựa chọn trên bảo toàn phụ thuộc hàm. Lựa chọn đầu tiên là thay thế Contracts bằng hai quan hệ SDP và CSJDQV. Lựa chọn thứ hai là thay thế bằng SPQV, SDP, và CSJDQ. Thêm một quan hệ là CJP sẽ làm cho phân rã thứ hai (không phải là phân rã đầu tiên) bảo toàn phụ thuộc hàm. Giá của việc duy trì ba quan hệ CJP, SPQV, và CSJDQ (ngược lại với chỉ CSJDQV) có thể dẫn chúng ta đến việc lựa chọn phân rã đầu tiên. Trong trường hợp này, thiết lập các FDs trở nên cần thiết. Chúng ta có thể không làm điều này, nhưng nếu vậy chúng ta sẽ gặp những vi phạm ràng buộc trên dữ liệu.
Phân rã theo chiều dọc các quan hệ BCNF
Giả sử rằng chúng ta đã quyết định phân rã Contracts thành SDP và CSJDQV. Các lược đồ này đều ở BCNF, và không có lý do gì để tiếp tục phân rã chúng đứng trên quan điểm chuẩn hoá. Tuy nhiên, giả sử rằng các truy vấn sau đây thường xuyên được yêu cầu:
- Tìm các hợp đồng có nhà cung cấp là S.
- Tìm các hợp đồng do phòng D đặt.
Những truy vấn này có lẽ dẫn chúng ta đến việc phân rã CSJDQV thành CS, CD, và CJQV. Phân rã này không mất mát thông tin và hai truy vấn quan trọng này có thể được thực hiện bằng cách kiểm tra các quan hệ nhỏ hơn. Lý do khác để xem xét phân rã này là điều khiển tương tranh các hot spots. Nếu những truy vấn này phổ biến, và các cập nhật phổ biến nhất bao gồm thao tác thay đổi số lượng của các mặt hàng (và giá trị) trong các hợp đồng, phân rã này sẽ cải thiện được khả năng thực thi của hệ thống bằng cách giảm sự cạnh tranh khoá. Bây giờ, các khoá loại trừ được thiết đặt trên bảng CJQV là chủ yếu, và việc đọc trên CS và CD không xung đột với những khoá này.
Bất cứ khi nào chúng ta phân rã một quan hệ, chúng ta phải xem xét các truy vấn bị ảnh hưởng do việc phân rã này gây ra, đặc biệt là khi phân rã chỉ nhằm mục đích cải thiện khả năng thực thi của hệ thống. Ví dụ, nếu một truy vấn quan trọng khác là tìm tổng giá trị của các hợp đồng liên quan đến một nhà cung cấp nào đó, truy vấn này yêu cầu phải kết nối các quan hệ phân rã là CS và CJQV. Trong trường hợp này, chúng ta nên quyết định là không phân rã.
Phân rã theo chiều ngang
Phần trước chúng ta xem xét cách thay thế một quan hệ bằng một tập các quan hệ được phân rã theo chiều dọc. Đôi khi, chúng ta nên phân rã một quan hệ theo chiều ngang, tức là chia một quan hệ thành hai quan hệ có cùng thuộc tính như quan hệ gốc, mỗi quan hệ chứa một tập con các bộ giá trị của quan hệ gốc. Công nghệ này hữu ích khi các tập con này được truy vấn theo những cách rất khác nhau.
Ví dụ, có những luật khác nhau áp dụng cho các hợp đồng lớn, những hợp đồng mà giá trị của nó lớn hơn 10,000. (Có thể những hợp đồng này phải được nhận thông qua đấu giá). Ràng buộc này có thể đưa đến một số truy vấn trên Contracts sử dụng điều kiện value > 10,000. Một cách tiếp cận tình trạng này là xây dựng một chỉ mục B+tree phân cụm trên trường value của Contracts. Một lựa chọn nữa là chúng ta thay thế Contracts bằng hai quan hệ gọi là LargeContracts và SmallContracts, với ý nghĩa như trên.
Nếu chúng ta thay thế Contracts bằng hai quan hệ LargeContracts và SmallContracts, chúng ta có thể tạo mặt nạ cho những thay đổi này bằng cách định nghĩa một khung nhìn gọi là Contracts:
CREATE VIEW Contracts (cid, supplierid, projectid, deptid, partid, qty, value)
AS ((SELECT * FROM LargeContracts)
UNION
(SELECT * FROM SmallContracts))
Tuy nhiên, với các truy vấn có thể thực hiện được chỉ cần LargeContracts thì chỉ cần truy cập trực tiếp trên LargeContracts mà không phải trên khung nhìn. Thực hiện các truy vấn này trên khung nhìn Contracts với điều kiện chọn là value > 10,000 sẽ có kết quả tương đương với việc thực hiện nó trên LargeContracts nhưng không hiệu quả bằng.
Một ví dụ khác, nếu Contracts có một trường year (năm) và các truy vấn thường phải đối mặt với các hợp đồng trong một năm nào đó, chúng ta có thể lựa chọn phân vùng Contracts theo năm. Tất nhiên, các truy vấn liên quan đến các hợp đồng của nhiều hơn một năm, chúng ta sẽ phải thực hiện truy vấn liên quan đến năm đó trên từng quan hệ đã được phân rã.
Các lựa chọn cho điều chỉnh chỉ mục và khung nhìn
Bước đầu tiên trong điều chỉnh một khung nhìn nào đó là hiểu được các kế hoạch mà DBMS đã sử dụng để đánh giá truy vấn. Các hệ thống thường cung cấp một số khả năng để xác định các kế hoạch đã được sử dụng để đánh giá truy vấn. Khi chúng ta hiểu được các kế hoạch nào mà hệ thống đã lựa chọn, chúng ta có thể cân nhắc các cách thức để cải thiện khả năng thực thi. Chúng ta có thể xem xét các lựa chọn khác nhau của chỉ mục hoặc có thể đồng-phân-cụm hai quan hệ cho các truy vấn có sự liên kết, việc này sẽ được định hướng bằng những hiểu biết của chúng ta về các kế hoạch cũ và một kế hoạch tốt hơn nào đó mà chúng ta muốn DBMS sử dụng. Chi tiết tương tự như quá trình thiết kế ban đầu.
Một điều nên làm là trước khi tạo các chỉ mục mới, chúng ta nên cân nhắc xem có nên viết lại các truy vấn này mà vẫn sử dụng các chỉ mục đã tồn tại. Ví dụ, xem xét truy vấn sau có từ nối OR.
SELECT E.dno
FROM Employees E
WHERE E.hobby= ‘Stamps’ OR E.age=10
Nếu chúng ta có hai chỉ mục trên cả hobby và age, chúng ta có thể sử dụng các chỉ mục này để truy cập các bộ giá trị cần thiết, nhưng bộ tối ưu có lẽ không nhận ra được điều này. Bộ tối ưu có lẽ xem xét các điều kiện trong mệnh đề WHERE tuần tự, quét Employees, và áp các điều kiện chọn theo kiểu on-the-fly. Giả sử chúng ta viết lại truy vấn này dùng phép hợp của hai truy vấn, một truy vấn có mệnh đề WHERE E.hobby ='Stamps' và truy vấn khác có mệnh đề WHERE E.age=10. Khi đó mỗi truy vấn được thực hiện một cách hiệu quả với việc hỗ trợ của cả hai chỉ mục trên hobby và age.
Chúng ta cũng nên xem xét việc viết lại các truy vấn để tránh một số phép toán phải trả giá đắt. Ví dụ, truy vấn có mệnh đề DISTINCT để loại đi các giá trị trùng nhau, truy vấn dạng này sẽ phải trả giá đắt. Vì thế, chúng ta nên loại mệnh đề DISTINCT bất cứ khi nào có thể. Ví dụ, với một truy vấn trên một quan hệ đơn, chúng ta có thể loại bỏ mệnh đề DISTINCT bất cứ khi nào có cả hai tình huống sau:
- Chúng ta không quan tâm đến sự hiện diện của các bộ giá trị trùng nhau.
- Các thuộc tính được nhắc đến trong mệnh đề SELECT bao gồm một khoá dự tuyển của quan hệ này.
Đôi khi một truy vấn có mệnh đề GROUP BY và HAVING có thể được thay thế bằng một truy vấn mà không có hai mệnh đề này, do vậy loại bỏ được một thao tác sắp xếp. Ví dụ, xem xét:
SELECT MIN (E.age)
FROM Employees E
GROUP BY E.dno
HAVING E.dno=102
Truy vấn này tương đương với truy vấn:
SELECT MIN (E.age)
FROM Employees E
WHERE E.dno=102
Các truy vấn phức tạp thường được viết lại trong một số bước sử dụng một quan hệ tạm. Chúng ta có thể viết lại những truy vấn này mà không có quan hệ tạm để nó chạy nhanh hơn. Xem xét truy vấn để tính lương trung bình của các phòng có người quản lý là Robinson:
SELECT *
INTO Temp
FROM Employees E, Departments D
WHERE E.dno=D.dno AND D.mgrname= ‘Robinson’
SELECT T.dno, AVG (T.sal)
FROM Temp T
GROUP BY T.dno
Truy vấn này có thể được viết lại như sau:
SELECT E.dno, AVG (E.sal)
FROM Employees E, Departments D
WHERE E.dno=D.dno AND D.mgrname= ‘Robinson’
GROUP BY E.dno
Việc viết lại truy vấn này mà không cần sử dụng quan hệ trung gian Temp làm nó thực hiện nhanh hơn. Thực tế, bộ tối ưu có thể tìm được một kế hoạch chỉ-chỉ-số rất hiệu quả, kế hoạch này không bao giờ truy cập các bộ giá trị Employees nếu ở đó có một chỉ mục B+tree tổ hợp trên (dno, sal). Ví dụ này còn minh hoạ cho nhận xét sau: Bằng việc viết lại các truy vấn để tránh những bảng tạm không cần thiết, chúng ta không chỉ tránh được việc tạo ra các quan hệ tạm, chúng ta còn mở ra nhiều khả năng tối ưu cho các bộ tối ưu hóa khám phá.
Tuy nhiên, trong một số trường hợp, nếu bộ tối ưu hoá không thể tìm ra được kế hoạch tốt cho các truy vấn phức tạp (như các truy vấn lồng nhau có nhiều quan hệ liên quan), thì việc nên làm là viết lại truy vấn để nó sử dụng các bảng tạm và định hướng cho bộ tối ưu hoá lựa chọn một kế hoạch tốt.
Thực tế, các truy vấn lồng nhau thường không hiệu quả vì rất nhiều bộ tối ưu không giải quyết tốt chúng, như đã trình bày trong Phần 5. Vì thế, chúng ta nên viết lại các truy vấn lồng nhau và các truy vấn liên kết. Như đã lưu ý ở trên, chúng ta có thể viết lại những truy vấn này bằng cách sử dụng các bảng tạm và các công nghệ khác (được làm bằng các bộ tối ưu hoá là tốt nhất) đã được nghiên cứu rộng rãi.
Khả năng viết lại các truy vấn lồng nhau thành không lồng nhau sử dụng các bảng tạm được minh họa trong Phần 5.
Ảnh hưởng của tương tranh
Trong một hệ thống có nhiều người sử dụng đồng thời, chúng ta phải xem xét thêm một số điểm. Các giao dịch thực hiện khoá trên một số trang mà chúng đang truy cập, vì thế các giao dịch khác bị ngăn không được truy cập những trang này.
Như những trình bày trong Phần 16.5, để thực thi đạt hiệu quả cao thì thời gian ngăn chặn phải được tối thiểu hoá và chúng ta đã chỉ ra hai cách để giảm thời gian này.
- Giảm thời gian nắm giữ các khoá của các giao dịch.
- Giảm các hot spots.
Bây giờ chúng ta bàn đến các công nghệ được sử dụng để đạt đến hai đích này.
Giảm khoảng thời gian khoá
Làm trễ các yêu cầu khoá: Điều chỉnh các giao dịch bằng cách viết lại một số biến chương trình địa phương và trì hoãn các thay đổi đối với cơ sở dữ liệu cho đến khi kết thúc giao dịch. Điều này làm giảm được thời gian khoá của giao dịch.
Làm các giao dịch trở nên nhanh hơn: Các giao dịch càng hoàn thành sớm thì các khoá của nó càng được giải phóng sớm. Chúng ta đã bàn về một số cách để tăng tốc độ của truy vấn và các lệnh cập nhật (ví dụ, điều chỉnh các chỉ mục, viết lại các truy vấn). Thêm nữa, việc phân vùng cẩn thận các bộ giá trị trong một quan hệ và những chỉ mục liên quan của nó trên một tập hợp các đĩa có thể cải thiện đáng kể truy cập tương tranh. Ví dụ, nếu chúng ta có một quan hệ trên một đĩa và một chỉ mục trên một đĩa khác, việc truy cập tới các chỉ mục có thể được thực hiện mà không ảnh hưởng đến việc truy cập tới các quan hệ, ít nhất là ở mức đọc đĩa.
Thay thế các giao dịch dài bằng các giao dịch ngắn: Đôi khi, quá nhiều công việc được làm trong một giao dịch, và nó phải mất một khoảng thời gian dài để thực hiện và thời gian nắm giữ các khoá cùng dài. Trong trường hợp này, chúng ta nên cân nhắc để thay thế giao dịch này bằng hai hoặc nhiều giao dịch nhỏ hơn: holdable cursors (xem phần 6.1.2) có thể hữu ích để làm điều này. Ưu điểm của việc làm này là các giao dịch nhỏ hơn có thể hoàn thành nhanh hơn và giải phóng khoá sớm hơn. Nhược điểm là một loạt các thao tác không còn được thực hiện một cách nguyên tử, và các ứng dụng phải giải quyết tình trạng này khi một trong số những giao dịch này không hoàn thành được.
Xây dựng một Warehouse: Các giao dịch phức tạp có thể nắm giữ các khoá chia sẻ trong một thời gian dài. Tuy nhiên, thường thì những truy vấn này bao gồm các phân tích thống kê của các khuynh hướng và nó có thể cho phép chạy trên các bản sao của dữ liệu. Điều này dẫn đến sự phổ biến của data warehouses, nó là bản sao của những dữ liệu được sử dụng trong những truy vấn phức tạp (Chương 25). Việc chạy các truy vấn này trên warehouse sẽ làm giảm gánh nặng cho cơ sở dữ liệu hiện tại.
Đề nghị một mức cô lập thấp hơn: Trong nhiều trường hợp, ví dụ khi các truy vấn đưa ra thông tin nhóm hoặc các thống kê, chúng ta có thể sử dụng một mức cô lập thấp hơn như REPEATABLE READ hoặc READ COMMITTED (Phần 16.6). Các mức cô lập thấp hơn có chi phí khoá thấp hơn và những người lập trình ứng dụng phải cân nhắc để có một bản thiết kế tốt.
Giảm Hot Spots
Trễ các thao tác Hot Spots: Chúng ta đã bàn về giá trị của việc trễ các yêu cầu có khóa. Rõ ràng, điều này đặc biệt quan trọng đối với các yêu cầu có chứa các đối tượng được sử dụng thường xuyên.
Tối ưu hoá các mô hình truy cập: Xây dựng các mô hình cho các thao tác cập nhật một quan hệ có thể cũng mang lại hiệu quả. Ví dụ, nếu các bộ giá trị được thêm vào quan hệ Employees theo thứ tự của eid và chúng ta có một chỉ mục B+tree trên eid, mỗi bộ giá trị được thêm sẽ ở trang lá cuối cùng của B+tree. Điều này dẫn đến có các hot spots dọc theo đường từ gốc đến trang lá bên phải nhất. Vì thế, chúng ta nên chọn một chỉ mục băm trên B+tree hoặc chỉ mục một trường khác. Ghi nhớ rằng việc mô hình hoá các truy cập như thế này sẽ dẫn đến khả năng thực thi của các chỉ mục ISAM kém đi, vì trang lá cuối cùng trở thành một hot spot. Đây là một khó khăn cho các chỉ mục băm vì quá trình băm sẽ chọn ngẫu nhiên một bucket mà bản ghi được thêm vào.
Phân chia các thực thi trên Hot spots: Xem xét một giao dịch thêm các bản ghi mới vào một file nào đó (ví dụ, thêm vào một bảng được lưu như một heap file). Thay vì thêm một bản ghi ứng với một giao dịch và thực hiện một khoá trên trang cuối cùng của mỗi bản ghi, chúng ta có thể thay thế các giao dịch này bằng một vài giao dịch khác, nó sẽ viết các bản ghi lên một file địa phương và sau đó định kỳ thực hiện thêm một bó các bản ghi này lên file chính.
Minh hoạ thêm về việc phân vùng, giả sử chúng ta lưu lại số lượng các bản ghi được thêm vào một biến đếm. Thay vì phải cập nhật biến này một lần ứng với mỗi bản ghi được thêm, chúng ta sẽ sử dụng cách tiếp cận trước và chỉ định kỳ cập nhật biến này. Ý tưởng này có thể được sử dụng trong rất nhiều các yêu cầu đếm và nó mang lại hiệu quả cao.
Lựa chọn chỉ mục: Nếu một quan hệ nào đó được cập nhật thường xuyên, các chỉ mục B+tree trên có thể trở thành các nút cổ chai, bởi vì tất cả các truy cập thông qua chỉ mục này đều phải đi qua gốc. Vì thế, gốc và các trang chỉ mục phía dưới có thể trở thành các hot spots. Nếu các DBMS sử dụng các giao thức khoá đặc biệt cho các chỉ mục cây, thì vấn đề này sẽ bớt nghiêm trọng hơn. Rất nhiều hệ thống hiện nay sử dụng công nghệ này.
Tuy nhiên, xem xét này có thể dẫn chúng ta đến việc lựa chọn một chỉ mục ISAM trong một số tình huống. Vì các mức chỉ mục của một chỉ mục ISAM nào đó là tĩnh nên chúng ta không cần thực hiện khoá trên những trang này; chỉ những trang lá là cần phải khoá. Một chỉ mục ISAM có lẽ phù hợp hơn một chỉ mục B+tree, ví dụ, nếu việc cập nhật xảy ra thường xuyên nhưng chúng ta hy vọng sự phân bố của các bản ghi , số lượng (và kích thước) của các bản ghi trong một miền nào đó của giá trị khoá tìm kiếm là xấp xỉ bằng nhau. Trong trường hợp này chỉ mục ISAM sẽ cần chi phí khoá thấp hơn (và giảm được sự cạnh tranh của các khoá), và việc phân bố các bản ghi này sẽ tạo ra không nhiều các trang tràn.
Các chỉ mục băm không tạo ra các nút cổ chai tương tranh, trừ khi việc phân bố dữ liệu được thực hiện rất kém và rất nhiều mục dữ liệu được lưu tập trung trong một vài bucket nào đó. Trong trường hợp này, các cổng vào thư mục của các buckets này có thể trở thành các hot spots.
Trường hợp nghiên cứu: Cửa hàng Internet
Xem lại ví dụ của chúng ta, DBDudes Dudes xem xét các luồng công việc cho cửa hàng B&N. Người chủ của cửa hàng mong muốn những khách hàng của anh ấy được tìm kiếm sách theo mã ISBN trước khi đặt hàng. Quá trình đặt hàng thông qua hóa đơn bao gồm việc thêm một bản ghi vào bảng Orders và thêm một hoặc nhiều bản ghi vào quan hệ Orderlists. Nếu số lượng hàng đặt của khách hàng đã có sẵn, thì người ta sẽ chuẩn bị đưa hàng và ngày giao hàng (ship_date) trong quan hệ Orderlists được thiết đặt. Thêm nữa, số lượng sách trong kho thay đổi theo thời gian, vì các hóa đơn đặt hàng đến thì hàng được chuyển đi, số lượng trong kho sẽ giảm. Còn khi nhà cung cấp mang sách đến thì số lượng này sẽ tăng lên.
Nhóm DBDudes bắt đầu bằng việc xem xét tìm kiếm sách theo ISBN. Vì isbn là một khóa, một truy vấn bằng theo mã isbn sẽ trả về nhiều nhất một bản ghi. Vì thế, để tăng tốc độ các truy vấn của khách hàng tìm kiếm sách theo isbn, DBDudes quyết định xây dựng một chỉ mục không phân cụm trên isbn.
Tiếp theo, ta xem xét việc cập nhật số lượng một cuốn sách nào đó. Để cập nhật giá trị qty_in_stock cho một quyển sách, đầu tiên chúng ta phải tìm kiếm quyển sách này; sử dụng chỉ mục trên isbn sẽ tăng tốc độ công việc này. Vì giá trị của trường qty_in_stock được cập nhật rất thường xuyên, DBDudes cũng xem xét việc phân vùng quan hệ Books theo chiều dọc thành hai quan hệ sau:
BooksQty(isbn, qty)
BookRest(isbn, title, author, price, year_published)
Nhưng không may là việc phân vùng theo chiều dọc này làm chậm đi rất nhiều các truy vấn thường xuyên khác: Bây giờ, việc tìm kiếm theo ISBN để truy cập tất cả thông tin về một quyển sách nào đó yêu cầu một kết nối giữa BooksQty và BooksRest. Vì thế DBDudes quyết định không phân vùng quan hệ Books nữa.
DBDudes nghĩ rằng có thể khách hàng cũng muốn tìm kiếm sách theo tiêu đề (title) và tác giả (author), và từ đó họ quyết định thêm một chỉ mục không phân cụm trên title và author- duy trì các chỉ mục này không đắt vì số đầu sách hiếm khi thay đổi.
Tiếp theo, DBDudes xem xét quan hệ Customers. Một khách hàng nào đó đầu tiên được xác định đầu tiên bằng mã số của họ. Vì thế, truy vấn thường gặp nhất trên quan hệ Customers là truy vấn bằng theo mã khách hàng, và DBDudes quyết định xây dựng một chỉ mục phân cụm trên cid để tối ưu được thời gian thực hiện truy vấn này.
Chuyển đến quan hệ Orders, DBDudes nhìn thấy rằng sẽ có hai truy vấn: thêm các hóa đơn mới và truy cập các hóa đơn đang tồn tại. Cả hai truy vấn này sẽ có thuộc tính ordernum là khóa tìm kiếm và vì thế DBDudes quyết định xây dựng một chỉ mục trên nó. Kiểu chỉ mục nên là gì: B+tree hay chỉ mục băm?
Vì mã số hóa đơn (order numbers) được thêm vào một cách tuần tự và tương ứng với ngày lập hóa đơn (order date) nên việc sắp xếp theo order numbers hiệu quả thì sắp xếp theo order date cũng hiệu quả. Vì thế DBDudes quyết định xây dựng một chỉ mục B+tree phân cụm trên ordernum. Mặc dù các thao tác được đề cập từ đầu đến bây giờ đều không thích cả chỉ mục B+tree và chỉ mục băm, nhưng B&N muốn kiểm soát tốt những thao tác hàng ngày xảy ra và chỉ mục phân cụm B+tree là lựa chọn tốt hơn cho những truy vấn phạm vi. Tất nhiên, điều này có nghĩa là việc truy cập tất cả các hóa đơn ứng với một khách hàng nào đó sẽ phải trả giá đắt đối với những khách hàng có nhiều hóa đơn, vì việc phân cụm theo ordernum sẽ không cho phép phân cụm theo các thuộc tính khác, ví dụ như là cid.
Các thao tác trong quan hệ Orderlists hầu như là các thao tác thêm bản ghi, và đôi khi có thêm thao tác cập nhật ngày chuyển hàng (shipment date) hoặc một truy vấn liệt kê tất cả các thành phần của một hóa đơn nào đó. Nếu Orderlists được lưu theo thứ tự sắp xếp của ordernum, tất cả các thao tác thêm được chèn vào cuối của quan hệ và vì thế sẽ rất hiệu quả. Một chỉ mục phân cụm B+tree trên ordernum duy trì thứ tự sắp xếp này và cũng giúp tăng tốc độ của việc truy cập tất cả các thành phần của một hóa đơn nào đó. Để cập nhật một shipment date, chúng ta cần tìm kiếm bộ giá trị này theo ordernum và isbn. Chỉ mục trên ordernum hỗ trợ tốt điều này. Mặc dù một chỉ mục nào đó trên (ordernum, isbn) sẽ thực tốt hơn nhưng các thao tác thêm sẽ không được thực hiện hiệu quả như sử dụng chỉ mục chỉ trên ordernum; vì thế DBDudes quyết định chỉ mục trên quan hệ Orderlists chỉ bằng một thuộc tính ordernum.
Điều chỉnh cơ sở dữ liệu
Một vài tháng sau khi khai trương Website B&N, DBDudes được gọi đến và được nói rằng khách hàng thắc mắc rằng các hóa đơn đang trong quá trình chờ thực hiện được xử lý rất chậm. B&N đã rất thành công, bảng Orders và Orderlists đã có số lượng bản ghi rất lớn.
Suy nghĩ thêm về phần thiết kế, DBDudes nhận ra rằng có hai kiểu hóa đơn: một là các hóa đơn đã hoàn thành, đó là những hóa đơn mà tất cả các sách khách hàng đặt đã được giao hết; hai là các hóa đơn chưa hoàn thành, là những hóa đơn mà một số cuốn sách trong hóa đơn đó chưa được giao. Hầu hết khách hàng yêu cầu xem các hóa đơn chưa hoàn thành, những hóa đơn dạng này chỉ chiếm một phần rất nhỏ so với toàn bộ hóa đơn. Vì thế DBDudes quyết định phân vùng theo chiều ngang cả hai bảng Orders và Orderlists theo thuộc tính ordernum. Việc làm này dẫn đến có bốn quan hệ mới: NewOrders, OldOrders, NewOrderlists, và OldOrderlists.
Một hóa đơn và các thành phần của nó luôn đi đôi với nhau – và chúng ta có thể xác định những cặp này, cũ hoặc mới, bằng một kiểm tra đơn giản trên ordernum - và các truy vấn chứa các hóa đơn này có thể được thực hiện chỉ trên các quan hệ liên quan. Bây giờ, một số truy vấn lại thực hiện chậm hơn, như truy vấn lấy ra tất cả các hóa đơn của một khách hàng, vì truy vấn này sẽ yêu cầu chúng ta tìm kiếm trên cả bốn quan hệ trên. Tuy nhiên, các truy vấn dạng này không thường xuyên được yêu cầu và thực thi của nó có thể chấp nhận được.
Tiêu chuẩn đánh giá DBMS
Phía trên chúng ta đã xem xét cách cải thiện thiết kế cơ sở dữ liệu để đạt được kết quả thực thi tốt hơn. Tuy nhiên, khi cơ sở dữ liệu lớn lên, DBMS có thể không còn khả năng cung cấp các công cụ hỗ trợ thực thi tốt nữa, mặc dù thiết kế đã tốt nhất có thể, vì thế chúng ta phải xem xét cách nâng cấp hệ thống của chúng ta, cụ thể là mua các phần cứng nhanh hơn và bổ sung thêm bộ nhớ. Chúng ta cũng có thể cân nhắc khả năng chuyển cơ sở dữ liệu của chúng ta sang một DBMS mới.
Khi đánh giá các sản phẩm DBMS, khả năng thực thi là một vấn đề quan trọng. DBMS là một tập hợp của các phầm mềm phức tạp, và các nhà cung cấp khác nhau có thể có những chiến lược phát triển sản phẩm của họ khác nhau để nhắm vào các thị trường. Ví dụ, một số hệ thống được thiết kế để thực hiện hiệu quả các truy vấn phức tạp, trong khi các hệ thống khác lại được thiết kế để thực hiện tốt các giao dịch đơn giản. Để hỗ trợ người dùng lựa chọn một DBMS phù hợp với yêu cầu của họ, một vài tiêu chuẩn đã được phát triển. Nó bao gồm các tiêu chuẩn để đo khả năng thực thi một lớp hiện tại của các ứng dụng (ví dụ, tiêu chuẩn TPC) và các tiêu chuẩn để đo hiệu quả thực thi của một DBMS trên một dãy các thao tác (ví dụ, Wisconsin benchmark).
Tiêu chuẩn nên gọn nhẹ, dễ hiểu. Chúng cũng nên đo được các thực thi cực lớn (ví dụ, giao dịch trên một giây hay còn gọi là tps) cũng như tỷ lệ giá/thực thi (ví dụ $/tsp) cho các luồng dữ liệu điển hình trong một miền ứng dụng nào đó. Transaction Processing Council (TPC) được tạo ra để định nghĩa các tiêu chuẩn cho quá trình xử lý giao dịch và các hệ thống cơ sở dữ liệu. Các tiêu chuẩn nổi tiếng đã được các nhà nghiên cứu và các tổ chức công nghệ đề xuất. Các Tiêu chuẩn do các nhà phát triển hệ thống đưa ra sẽ không hữu ích đối với việc so sách các hệ thống khác nhau (mặc dù chúng có thể hữu ích trong việc xác định một hệ thống nào đó quản lý một luồng công việc cụ thể tốt như thế nào).
Các tiêu chuẩn đánh giá DBMS nổi tiếng
Online Transaction Processing Benchmarks: TPC-A và TPC-B tạo nên các định nghĩa chuẩn về các độ đo tps và $/tps. TPC-A đo khả năng thực thi và giá của một mạng máy tính cộng với DBMS, ngược lại TPC-B benchmark xem xét chỉ riêng DBMS. Các tiêu chuẩn này bao gồm một giao dịch đơn giản để cập nhật ba bản ghi từ ba bảng khác nhau, và thêm một bản ghi vào bảng thứ tư. Một số thông tin chi tiết (ví dụ, giao dịch phân tán, phương thức kết nối trong, các thuộc tính của hệ thống) được xác định một cách nghiêm khắc, đảm bảo rằng kết quả trong các hệ thống khác nhau có thể được so sánh đầy đủ. TPC-C benchmark là một tập các công việc phức tạp hơn TPC-A và TPC-B. Nó mô hình hóa một warehouse ghi lại các mặt hàng đã được cung cấp cho từng khách hàng và bao gồm năm kiểu giao dịch. Một giao dịch TPC-C đắt hơn một giao dịch TPC-A hoặc TPC-B, và TPC-C tận dụng được nhiều khả năng của hệ thống, như sử dụng các chỉ mục phụ và loại bỏ các giao dịch không còn sử dụng nữa. Nó có thể thay thế hoàn toàn được TPC-A và TPC-B như là một benchmark xử lý giao dịch chuẩn tắc.
Query Benchmarks: Wisconsin benchmark được sử dụng rộng rãi để đo sự thực thi của các truy vấn đơn giản. Set Query benchmark đo khả năng thực thi của một loạt các truy vấn phức tạp hơn, và AS3AP benchmark đo khả năng thực thi của luồng công việc giữa các giao dịch hỗn hợp, các truy vấn quan hệ và các hàm tiện ích. TPC-D benchmark hỗ trợ một dãy các truy vấn SQL phức tạp được dùng trong các ứng dụng. OLAP Council cũng phát triển một benchmark sử dụng cho các truy vấn hỗ-trợ-ra-quyết-định phức tạp, bao gồm một số truy vấn không thể được biểu diễn dễ dàng bằng SQL. Nó được sử dụng để đo các hệ thống OLAP, các hệ thống này được trình bày trong Chương 25. Sequoia 2000 benchmark được thiết kế để so sánh các DBMS hỗ trợ các hệ thống thông tin địa lý.
Object-Database Benchmarks: Benchmarks 001 và 007 đo khả năng thực thi của các hệ thống cơ sở dữ liệu hướng đối tượng. Bucky benchmark đo khả năng thực thi của các hệ thống cơ sở dữ liệu hướng quan hệ. (Chúng tôi sẽ trình bày về các hệ thống cơ sở dữ liệu hướng đối tượng trong Chương 23).
Sử dụng Tiêu chuẩn
Tiêu chuẩn nên được sử dụng cùng với những hiểu biết tốt về việc chúng được thiết kế để đánh giá cái gì và môi trường ứng dụng sử dụng DBMS này. Khi bạn sử dụng tiêu chuẩn để định hướng việc lựa chọn DBMS cho ứng dụng của mình, bạn nên luôn ghi nhớ những hướng dẫn sau:
Ý nghĩa của một Benchmark nào đó? Một DBMS là một phần mềm phức tạp được sử dụng trong hàng loạt các ứng dụng. Một benchmark nên có một dãy các công việc được lựa chọn cẩn thận để phủ lên một miền ứng dụng cụ thể và kiểm tra các tính năng DBMS quan trọng cho miền ứng dụng đó.
Benchmark phản chiếu luồng công việc của bạn tốt như thế nào? Xem xét luồng công việc của bạn và so sánh nó với benchmark này. Cung cấp nhiều trường hợp thử nghiệm cho benchmark này (tức là, các truy vấn và các yêu cầu cập nhật), những thao tác tương đương với những thao tác quan trọng trong luồng công việc của bạn. Đồng thời cũng xem xét ngữ cảnh mà benchmark này được đánh giá. Ví dụ, thời gian thực hiện của các truy vấn độc lập có lẽ khác với thời gian thực hiện nó trong chế độ đa người dùng: Một hệ thống nào đó có thể có thời gian thực hiện dài hơn vì các thao tác I/O được thực hiện chậm hơn. Trên luồng công việc đa người dùng, nếu được cung cấp các đĩa đủ cho thực hiện I/O song song, thì thời gian thực hiện một yêu cầu nào đó sẽ thấp hơn.
Tạo ra benchmark của chính bạn: Bạn có thể tạo ra benchmark do bạn làm chủ bằng cách thay đổi các benchmark chuẩn một cách tinh tế hoặc thay thế các công việc trong một benchmark chuẩn bằng các công việc tương đương trong luồng công việc của bạn.
Bài tập
Xem xét lược đồ BCNF sau, nó là một phần cơ sở dữ liệu của một công ty (những thông tin không liên quan đến câu hỏi đã bị lược bỏ):
Emp (eid, ename, addr, sal, age, yrs, deptid)
Dept (did, dname, floor, budget)
Giả sử bạn biết rằng sáu truy vấn sau là sáu truy vấn quan trọng nhất trong các lưu lượng công việc và chúng có tần xuất xuất hiện và tầm quan trọng ngang nhau.
- Liệt kê eid, ename, và addr của các nhân viên ở một độ tuổi nào đó do người dùng nhập vào.
- Liệt kê eid, ename, và addr của các nhân viên làm việc trong một phòng nào đó do người dùng nhập vào.
- Liệt kê eid và addr của các nhân viên có tên nào đó do người dùng nhập vào.
- Liệt kê lương trung bình của các nhân viên.
- Liệt kê lương trung bình của các nhân viên theo từng tuổi, tức là với mỗi giá trị của tuổi lưu trong cơ sở dữ liệu, liệt kê tuổi và lương trung bình tương ứng với tuổi đó.
- Liệt kê tất cả thông tin về các phòng, sắp xếp theo thứ tự tầng.
- Cho những thông tin trên và giả sử rằng sáu truy vấn này quan trọng hơn bất kỳ một lệnh cập nhật nào, thiết kế lược đồ vật lý cho cơ sở dữ liệu này để các lưu lượng công việc mong muốn được thực hiện hiệu quả. Cụ thể, bạn hãy quyết định những thuộc tính nào sẽ được chỉ mục và các chỉ mục này có phân cụm hay không phân cụm. Giả sử rằng chỉ có các chỉ mục B+tree là kiểu chỉ mục được hỗ trợ bởi các DBMS và khóa có thể là thuộc tính đơn hay đa-thuộc-tính. Chỉ rõ thiết kế vật lý của bạn bằng việc xác định các thuộc tính bạn đề nghị chỉ mục hóa qua B+tree phân cụm hay không phân cụm.
- Thiết kế lại lược đồ vật lý giả sử rằng tập các truy vấn quan trọng ở trên được thay bằng tập các truy vấn sau:
- Liệt kê eid và addr của các nhân viên nào đó do người dùng nhập vào.
- Liệt kê lương lớn nhất của nhân viên.
- Liệt kê lương trung bình của các nhân viên theo phòng; tức là với mỗi giá trị của deptid, liệt kê deptid và lương trung bình của các nhân viên trong phòng đó.
- Liệt kê tổng ngân sách (budget) của tất cả các phòng theo tầng; tức là với mỗi tầng, liệt kê tầng và tổng ngân sách tương ứng.
- Giả sử rằng lưu lượng công việc được điều chỉnh tự động bằng công cụ điều chỉnh chỉ mục tự động. Gạch đầu dòng những bước chính mà thuật tóan điều chỉnh chỉ mục thực hiện và tập các cấu hình ứng cử viên sẽ được xem xét.
Câu trả lời với mỗi câu hỏi như sau:
- Nếu chúng ta tạo ra một chỉ mục B+tree ‘rậm rạp’ trên <age, sal> của quan hệ Emp, chúng ta có thể thực hiện quét chỉ-chỉ-số để trả lời truy vấn thứ năm. Chỉ mục băm sẽ không phục vụ mục đích của chúng ta, vì các cổng vào dữ liệu sẽ không được sắp xếp trên age! Nếu việc quét chỉ-chỉ-số không cho phép tạo ra một chỉ mục phân cụm B+tree chỉ trên trường age của Emp.
- Chúng ta nên tạo ra một chỉ mục B+tree không phân cụm trên depid của quan hệ Emp và một chỉ mục không phân cụm khác trên <dname, did> của quan hệ Dept. Sau đó, chúng ta có thể thực hiện việc tìm kiếm chỉ-chỉ-số trên Dept và sau đó lấy các bản ghi của Emp với depid thích hợp cho truy vấn thứ hai.
- Chúng ta nên tạo ra một chỉ mục không phân cụm trên ename của quan hệ Emp cho truy vấn thứ ba.
- Chúng ta muốn một chỉ mục phân cụm B+tree ‘thưa thớt’ trên trường floor của chỉ mục Dept để chúng ta có thể có phòng ứng với mỗi tầng theo thứ tự của các tầng cho truy vấn thứ sáu.
- Cuối cùng, chỉ mục không phân cụm ‘rậm rạp’ trên sal sẽ cho phép chúng ta tính trung bình lương của tất cả các nhân viên sử dụng việc quét chỉ-chỉ-số. Tuy nhiên, chỉ mục B+tree không phân cụm ‘rậm rạp’ trên <age, sal> được tạo ra để hỗ trợ Truy vấn (5) cũng có thể sử dụng để tính lương trung bình của tất cả các nhân viên, và nó cũng tốt cho truy vấn này giống như khi chúng ta sử dụng một chỉ mục nào đó chỉ trên trường sal. Vì thế chúng ta không nên tạo ra một chỉ mục riêng rẽ chỉ trên sal.
2.
- Chúng ta nên tạo ra một chỉ mục B+tree không phân cụm trên ename cho quan hệ Emp để chúng ta có thể tìm các nhân viên cùng với một tên cụ thể nào đó cho truy vấn đầu tiên một cách hiệu quả. Đây không phải là kế hoạch chỉ-chỉ-số.
- Một chỉ mục B+tree không phân cụm trên sal cho quan hệ Emp sẽ giúp tìm ra lương cao nhất cho truy vấn thứ hai. (Nó thực hiện tốt hơn chỉ mục băm vì hàm nhóm là MAX-chúng ta có thể đơn giản đi xuống trang lá phía phải nhất trong chỉ mục B+tree). Đây không phải là kế hoạch chỉ-chỉ-số.
- Chúng ta nên tạo ra một chỉ mục B+tree không phân cụm trên <deptid, sal> của quan hệ Emp để chúng ta có thể thực hiện việc quét chỉ-chỉ-số trên tất cả các nhân viên của một phòng nào đó. Nếu các kế hoạch chỉ-chỉ-số không được hỗ trợ, thì chỉ mục B+tree phân cụm ‘thưa thớt’ trên deptid sẽ là tốt nhất. Nó sẽ cho phép chúng ta truy cập các bộ giá trị theo deptid.
- Chúng ta nên tạo ra một chỉ mục không phân cụm ‘rậm rạp’ trên <floor, budget> cho Dept. Điều này sẽ cho phép chúng ta tính tổng các ngân sách theo tầng sử dụng một kế hoạch chỉ-chỉ-số. Nếu các kế hoạch chỉ-chỉ-số không được hỗ trợ, chúng ta nên tạo ra một chỉ mục B+tree phân cụm ‘thưa thớt’ trên trường floor cho quan hệ Dept để chúng ta có thể tìm ra các phòng trên mỗi tầng theo thứ tự của tầng.
Xem xét lược đồ quan hệ BCNF sau, nó là một phần của cơ sở dữ liệu của một trường đại học (những thông tin không liên quan đến câu hỏi đã bị lược bỏ):
Prof(ssno, pname, office, age, sex, specialty, dept_did)
Dept( did , dname, budget, num_majors, chair_ssno)
Giả sử bạn biết rằng năm truy vấn sau đây là các truy vấn thường gặp nhất trong lưu lượng công việc của trường đại học này và cả năm truy vấn có tần suất xuất hiện và tầm quan trọng ngang nhau.
- Liệt kê pname, age, và office của các giáo sư (professors) theo giới tính (sex) người dùng nhập vào (male hoặc female) và có lĩnh vực nghiên cứu đặc biệt (specialty) do người dùng nhập vào (ví dụ, “recursive query processing”).Giả sử rằng trường đại học này có nhiều nhóm nghiên cứu khác nhau, ít xảy ra khả năng có nhiều giáo sư có cùng lĩnh vực nghiên cứu đặc biệt.
- Liệt kê tất cả thông tin về các bộ môn và các giáo sư ở một độ tuổi nào đó do người dùng nhập vào.
- Liệt kê did, dname, và chairperson name của các bộ môn có giá trị num_majors nào đó do người dùng nhập vào.
- Liệt kê ngân quỹ thấp nhất của một bộ môn nào đó
- Liệt kê tất cả các thông tin về các giáo sư là người lãnh đạo bộ môn.
Những truy vấn này xảy ra thường xuyên hơn nhiều so với các lệnh cập nhật, vì thế bạn nên xây dựng bất cứ chỉ mục nào có thể làm tăng tốc độ các truy vấn này. Tuy nhiên, bạn không nên xây dựng các chỉ mục không cần thiết, vì các lệnh cập nhật sẽ xảy ra (và sẽ bị chậm vì các chỉ mục không cần thiết này). Bạn hãy thiết kế một lược đồ vật lý cho trường đại học này để nó thực hiện tốt những lưu lượng công việc mong muốn. Cụ thể, bạn hãy quyết định những thuộc tính nào sẽ được chỉ mục và có phân cụm hay không phân cụm. Giả sử rằng các chỉ mục B+tree và chỉ mục băm là kiểu chỉ mục được hỗ trợ bởi các DBMS và khóa có thể là thuộc tính đơn hay đa-thuộc-tính.
1. Chỉ rõ thiết kế vật lý của bạn bằng việc xác định các thuộc tính nên chỉ mục hóa, với mỗi chỉ mục bạn chỉ rõ nó được phân cụm hay không phân cụm và nó nên là B+tree hay là chỉ mục băm.
2. Giả sử rằng lưu lượng công việc này được điều chỉnh bằng công cụ điều chỉnh chỉ mục tự động. Gạch đầu dòng những bước chính mà thuật toán điều chỉnh chỉ mục thực hiện và tập các cấu hình ứng cử viên sẽ được xem xét.
3. Thiết kế lại lược đồ vật lý, giả sử rằng năm truy vấn quan trọng trên được thay bằng các truy vấn khác:
- Liệt kê từng bộ môn và các lĩnh vực nghiên cứu đặc biệt do các giáo sư của bộ môn đó thực hiện.
- Tìm bộ môn có num_majors thấp nhất.
- Tìm giáo sư trẻ nhất là người lãnh đạo bộ môn.
Dành cho độc giả
Xem xét lược đồ BCNF sau, đây là một phần cơ sở dữ liệu của một công ty (những thông tin không liên quan đến câu hỏi đã bị lược bỏ):
Project(pno, proj_name, proj_base_dept, proj_mgr, topic, budget)
Manager(mid, mgr_name, mgr_dept, salary, age, sex)
Ghi nhớ rằng mỗi dự án được thực hiện bằng một vài phòng, mỗi người quản lý là nhân viên trong một vài phòng, và người quản lý của một dự án nào đó không nhất thiết phải là nhân viên của phòng thực hiện dự án đó. Giả sử bạn biết rằng năm truy vấn sau đây là năm truy vấn quan trọng nhất và cả năm truy vấn đều có tần xuất xuất hiện và tầm quan trọng ngang nhau:
- Liệt kê mgr_name, age, và salary của người quản lý có giới tính nào đó do người dùng nhập vào (male hoặc female) đang làm việc tại một phòng nào đó. Bạn có thể giả sử rằng, có rất nhiều phòng và mỗi phòng có rất ít người quản lý dự án.
- Liệt kê tên của tất cả dự án cùng với người quản lý ở độ tuổi nào đó do người dùng nhập vào (ví dụ, tuổi nhỏ hơn 30).
- Liệt kê tên của tất cả các phòng mà người quản lý trong phòng này quản lý dự án do chính phòng này thực hiện.
- Liệt kê tên của các dự án có ngân sách thấp nhất.
- Liệt kê tên của tất cả người quản lý trong cùng một phòng.
Những truy vấn này xảy ra thường xuyên hơn nhiều so với các lệnh cập nhật, vì thế bạn nên xây dựng bất cứ chỉ mục nào có thể làm tăng tốc độ các truy vấn này. Tuy nhiên, bạn không nên xây dựng các chỉ mục không cần thiết, vì các lệnh cập nhật sẽ xảy ra (và sẽ bị chậm vì các chỉ mục không cần thiết này). Bạn hãy thiết kế một lược đồ vật lý để nó thực hiện tốt những lưu lượng công việc mong muốn. Cụ thể, bạn hãy quyết định những thuộc tính nào sẽ được chỉ mục và các chỉ mục này có phân cụm hay không phân cụm. Giả sử rằng các chỉ mục B+tree và chỉ mục băm là kiểu chỉ mục được hỗ trợ bởi các DBMS và khóa có thể là thuộc tính đơn hay đa-thuộc-tính.
- Chỉ rõ thiết kế vật lý của bạn bằng việc xác định các thuộc tính bạn đề nghị chỉ mục hóa, với mỗi chỉ mục bạn chỉ rõ nó được phân cụm hay không phân cụm và nó nên là B+tree hay là chỉ mục băm.
- Giả sử rằng lưu lượng công việc này được điều chỉnh bằng công cụ điều chỉnh chỉ mục tự động. Gạch đầu dòng những bước chính mà thuật toán điều chỉnh chỉ mục thực hiện và tập các cấu hình ứng cử viên sẽ được xem xét.
- Thiết kế lại lược đồ vật lý, giả sử rằng năm truy vấn quan trọng trên được thay bằng các truy vấn khác:
- Tìm tổng số ngân quỹ của các dự án được quản lý bằng mỗi người quản lý; tức là, liệt kê tất cả proj_mgr và tổng số ngân quỹ của các dự án được người quản lý này quản lý tương ứng.
- Tìm tổng số ngân quỹ của các dự án được quản lý bằng mỗi người quản lý nhưng chỉ với những người quản lý nằm trong độ tuổi nào đó do người dùng nhập vào.
- Tìm số lượng các người quản lý là nam giới (male).
- Tìm tuổi trung bình của tất cả người quản lý.
Câu trả lời với mỗi câu hỏi như sau:
1.
- Với truy vấn đầu tiên, chúng ta nên tạo ra một chỉ mục băm không phân cụm ‘rậm rạp’ trên mgr_dept cho quan hệ Manager. Chúng ta bỏ qua sex ra khỏi khóa trong chỉ mục này vì nó rất ít khi được chọn, tuy nhiên, việc có nó không phải trả chi phí đắt vì trường này dường như không được cập nhật thường xuyên.
- Chúng ta nên tạo ra một chỉ mục B+tree không phân cụm trên <age_mgr_dept,mid>cho quan hệ Manager, và chỉ mục băm không phân cụm trên <proj_base_dept, proj_mgr> cho quan hệ Project. Chúng ta có thể thực hiện việc quét chỉ-chỉ-số để tìm ra tất cả các nhà quản lý có tuổi nằm trong miền được xác định, và sau đó băm vào trong quan hệ Project để có được tên các dự án. Nếu việc quét chỉ-chỉ-số không được hỗ trợ, chỉ mục trên Manager nên là một chỉ mục phân cụm trên age.
- Với truy vấn thứ ba chúng ta không cần một chỉ mục mới. Chúng ta có thể quét tất cả managers và sử dụng chỉ mục băm trên <proj_base_dept, proj_mgr>trên quan hệ Project để kiểm tra mgr_dept = proj_base_dept.
- Chúng ta có thể tạo ra một chỉ mục không phân cụm B+tree trên budget trong quan hệ Project và sau đó đi xuống cây này để tìm ra budget thấp nhất cho truy vấn thứ tư.
- Với truy vấn thứ năm, chúng ta nên tạo ra một chỉ mục băm không phân cụm ‘rậm rạp’ trên pno của quan hệ Project. Chúng ta có thể có proj_base_dept của project bằng cách sử dụng chỉ mục này, và sau đó sử dụng chỉ mục băm trên mgr_dept để có được những người quản lý của phòng này. Ghi nhớ rằng một chỉ mục nào đó trên <pno, proj_base_dept> của Project sẽ cho phép chúng ta thực hiện việc quét chỉ-chỉ-số trên Project. Tuy nhiên, vì ở đây có chính xác một phòng với mỗi dự án (pno là khóa) nên nó dường như không nhanh hơn đáng kể. (Nó chỉ tiết kiệm được 1 I/O trên mỗi dự án.)
2.
- Với truy vấn đầu tiên, chúng ta nên tạo ra một chỉ mục B+tree không phân cụm trên <proj_mgr, budget> cho quan hệ Project. Việc quét chỉ-chỉ-số sau đó được sử dụng để thực hiện truy vấn này. Nếu việc quét chỉ-chỉ-số không được hỗ trợ, chỉ mục phân cụm trên proj_mgr sẽ là tốt nhất.
- Nếu chúng ta tạo ra một chỉ mục B+tree phân cụm ‘thưa thớt’ trên <age, mid> cho quan hệ Manager, chúng ta có thể thực hiện việc quét chỉ-chỉ-số trên chỉ mục này để tìm ra được các ids của người quản lý trong miền đã cho. Sau đó, chúng ta có thể sử dụng việc quét chỉ-chỉ-số của chỉ mục B+tree trên <proj_mgr, budget> để tính ra tổng ngân sách của các dự án do từng người quản lý phụ trách. Nếu việc quét chỉ-chỉ-số không được hỗ trợ, chỉ mục này trên Manager sẽ là chỉ mục B+tree phân cụm trên age.
- Một chỉ mục băm không phân cụm trên sex sẽ chỉ ra những người quản lý theo sex và cho phép chúng ta tính số lượng những người có giới tính là male sử dụng một thao tác quét chỉ-chỉ-số. Nếu các thao tác quét chỉ-chỉ-số không được hỗ trợ, thì không có chỉ mục nào giúp được chúng ta để thực hiện truy vấn thứ ba.
- Chúng ta nên tạo ra một chỉ mục băm không phân cụm trên age cho truy vấn thứ tư. Tất cả chúng ta cần để làm là tính trung bình của tuổi (age) sử dụng việc quét chỉ-chỉ-số. Nếu các kế hoạch chỉ-chỉ-số không được phép thì không có chỉ mục nào hỗ trợ được chúng ta.
Câu lạc bộ Globetrotters được tổ chức thành các Hội (Chapter). Người đứng đầu (President) của một hội nào đó không bao giờ đứng đầu một hội khác, và mỗi hội cung cấp cho người đứng đầu hội đó một khoản lương. Các hội có thể chuyển đến địa điểm mới, và người đứng đầu được bầu lại khi (và chỉ khi) hội được chuyển đi. Dữ liệu này được lưu trong quan hệ G(C,S,L,P), trong đó C là Chapter (Hội), S là Salary (Lương), L là Location (Địa điểm), và P là President (Người đứng đầu). Dạng truy vấn sau được yêu cầu thường xuyên, và bạn phải trả lời nó mà không cần thực hiện kết nối: "Ai là người đứng đầu của hội X khi nó ở địa điểm Y?"
1. Liệt kê danh sách các FDs có trên G.
2. Quan hệ G có những khóa dự tuyển nào?
3. Quan hệ G đang ở dạng chuẩn nào?
4. Thiết kế một lược đồ cơ sở dữ liệu tốt cho câu lạc bộ này. (Nhớ rằng thiết kế của bạn phải thực hiện được truy vấn trên!)
5. Thiết kế của bạn ở dạng chuẩn nào? Cung cấp một ví dụ truy vấn chạy chậm trên lược đồ này hơn là trên quan hệ G.
6. Có phân rã nào của G thành các quan hệ ở BCNF mà không mất kết nối và bảo toàn phụ thuộc hàm không?
7. Có lý do nào tốt để chấp nhận một quan hệ ở dạng chuẩn thấp hơn 3NF không? Sử dụng ví dụ này, thêm các ràng buộc nếu cần thiết để minh họa câu trả lời của bạn.
Dành cho độc giả
Xem xét quan hệ ở dạng BCNF sau, quan hệ này bao gồm mã sản phẩm, kiểu sản phẩm (ví dụ, quả hay là bó), giá, và số lượng có trong kho.
Parts (pid, pname, cost, num_avail)
Bạn được biết là hai truy vấn sau cực kỳ quan trọng:
- Tìm tổng số lượng có trong kho của từng kiểu sản phẩm, ứng với tất cả các kiểu.
- Liệt kê pids của các sản phẩm có giá cao nhất.
- Trình bày thiết kế vật lý bạn lựa chọn cho quan hệ này. Tức là, loại cấu trúc file dùng để lưu tập các bản ghi của Parts, và bạn sẽ tạo ra những chỉ mục nào?
- Giả sử sau này khách hàng của bạn vẫn phàn nàn về khả năng thực thi của hệ thống. Vì bạn không có khả năng mua thêm phần cứng và phần mềm mới, nên bạn phải cân nhắc để thiết kế lại lược đồ. Bạn sẽ thiết kế lại lược đồ quan hệ, tổ chức file và các chỉ mục trên các quan hệ này như thế nào.
- Câu trả lời đối với hai câu hỏi trên thay đổi như thế nào nếu hệ thống của bạn không hỗ trợ các chỉ mục có khóa tìm kiếm đa-thuộc-tính?
Câu trả lời với mỗi câu hỏi như sau:
1. Cấu trúc heap file có thể được sử dụng cho quan hệ Parts. Một chỉ mục B+tree không phân cụm ‘thưa thớt’ trên <pname, num_avail> và một chỉ mục không phân cụm ‘thưa thớt’ trên <cost, pid> có thể được tạo ra để thực hiện hiệu quả truy vấn này.
2. Vấn đề này có thể là do bộ tối ưu hóa có lẽ không xem xét các kế hoạch chỉ-chỉ-số, những kế hoạch này có thể được thực hiện sử dụng lược đồ được biểu diễn ở trên. Vì thế chúng ta có thể thay bằng việc tạo ra các chỉ mục phân cụm trên <pid, cost> và <pname, num_avail>. Để làm điều này chúng ta phải phân vùng dọc quan hệ này thành hai quan hệ là Parts1(pid, cost) và Parts2( pid, pname, num_avail). Nếu các chỉ mục này bản thân nó không được thực hiện, thì chúng ta có thể thay bằng sử dụng các tổ chức file được sắp cho hai quan hệ được chia tách này).
3. Nếu các khóa đa-thuộc-tính không được phép thì chúng ta có các chỉ mục B+tree phân cụm trên cost và trên pname trên cả hai quan hệ.
Xem xét các quan hệ ở BCNF sau, hai quan hệ này chứa thông tin về các nhân viên (Emp) và các phòng (Dept) nơi họ làm việc.
Emp(eid, sal, did)
Dept(did, location, budget)
Bạn được nói rằng hai truy vấn sau thực sự quan trọng:
- Tìm địa điểm (location) nơi mà một nhân viên nào đó làm việc.
- Kiểm tra xem ngân quỹ (budget) của một phòng nào đó có lớn hơn lương của từng nhân viên trong phòng đó không.
- Trình bày thiết kế vật lý bạn lựa chọn cho quan hệ này. Tức là, loại cấu trúc file bạn lựa chọn để lưu tập các bản ghi của những quan hệ này, và bạn sẽ tạo ra những chỉ mục nào?
- Giả sử sau này khách hàng của bạn vẫn phàn nàn về khả năng thực thi của hệ thống. Vì bạn không có khả năng mua thêm phần cứng và phần mềm mới, bạn phải cân nhắc để thiết kế lại lược đồ. Bạn sẽ thiết kế lại lược đồ quan hệ, tổ chức file và các chỉ mục trên các quan hệ này như thế nào.
- Giả sử rằng hệ thống cơ sở dữ liệu của bạn không thực hiện hiệu quả những cấu trúc chỉ mục này. Bạn sẽ làm gì trong trường hợp này.
Dành cho độc giả
Xem xét các quan hệ ở BCNF sau, hai quan hệ này chứa thông tin về các nhân viên (Emp) và các phòng (Dept) nơi họ làm việc.
Dept ( did , dname, location, managerid)
Emp ( eid , sal)
Bạn được nói rằng hai truy vấn sau thực sự quan trọng:
- Liệt kê tên (dname) và mã người quản lý (managerid) của từng phòng trong một địa điểm nào đó do người dùng nhập vào, kết quả được sắp xếp theo thứ tự của tên phòng.
- Tìm lương (sal) trung bình của các nhân viên làm quản lý phòng tại một địa điểm (location) nào đó do người dùng nhập vào. Bạn có thể giả sử rằng không có nhiều hơn một người quản lý trong một phòng.
- Trình bày các cấu trúc file và các chỉ mục bạn sẽ lựa chọn.
- Sau này bạn nhận ra rằng các quan hệ này thường xuyên được cập nhật. Vì các chỉ mục có thể làm chậm tốc độ của các lệnh cập nhật, bạn có nghĩ rằng để cải thiện khả năng thực thi của hệ thống này bạn sẽ không sử dụng các chỉ mục không?
Câu trả lời với mỗi câu hỏi như sau:
1. Tổ chức heap file cho hai quan hệ này là hiệu quả nếu chúng ta tạo ra các chỉ mục sau. Đầu tiên, chỉ mục B+tree phân cụm trên <location, dname> sẽ cải thiện được thực thi (chúng ta không thể liệt kê tên của các nhà quản lý vì ở đây không có biểu diễn thuộc tính name). Chúng ta cũng có thể có một chỉ mục băm trên eid của quan hệ Emp để tăng tốc độ truy vấn thứ hai: chúng ta tìm tất cả các manageridstừ chỉ mục B+tree này, sau đó sử dụng chỉ mục băm để tìm ra lương (sal) của họ.
2. Thiếu các chỉ mục, chúng ta có thể sử dụng phân rã ngang cho quan hệ Dept. Chúng ta cũng có thể thử với các tổ chức file được sắp, cùng với quan hệ Dept được sắp trên dname và Emp trên eid.
Với mỗi truy vấn sau, chỉ ra một nguyên nhân khiến bộ tối ưu hóa có thể không tìm được một kế hoạch tốt. Viết lại truy vấn này để nó có thể tìm được một kế hoạch thực hiện tốt. Các chỉ mục có thể và các ràng buộc được liệt kê trước mỗi truy vấn; giả sử rằng các lược đồ quan hệ phù hợp với các thuộc tính được đề cập đến trong các truy vấn này.
1. Một chỉ mục có trên thuộc tính age:
SELECT E.dno
FROM Employee E
WHERE E.age=20 OR E.age=10
2. Một chỉ mục B+tree trên thuộc tính age:
SELECT E.dno
FROM Employee E
WHERE E.age<20 AND E.agOlO
3. Một chỉ mục có trên thuộc tính age:
SELECT E.dno
FROM Employee E
WHERE 2*E.age<20
4. Không có chỉ mục nào:
SELECT DISTINCT *
FROM Employee E
5. Không có chỉ mục nào:
SELECT AVG (E.sal)
FROM Employee E
GROUP BY E.dno
HAVING E.dno=22
6. Thuộc tính sid của Reserves là khóa ngoại tham chiếu tới Sailors:
SELECT S.sid
FROM Sailors S, Reserves R
WHERE S.sid=R.sid
Dành cho độc giả
Xem xét hai cách để đưa ra tên của những người nhân viên kiếm được hơn $100000 và tuổi của họ bằng với tuổi của người quản lý họ. Đầu tiên, thực hiện một truy vấn lồng nhau:
SELECT E1. ename
FROM Emp E1
WHERE E1.sal > 100 AND E1.age = ( SELECT E2.age
FROM Emp E2, Dept D2
WHERE E1.dname = D2.dname AND D2.mgr = E2.ename )
Thứ hai, truy vấn chứa một định nghĩa khung nhìn:
SELECT E1.ename
FROM Emp E1, MgrAge A
WHERE E1.dname = A.dname AND E1.sal > 100 AND E1.age = A.age
CREATE VIEW MgrAge (dname, age)
AS SELECT D.dname, E.age
FROM Emp E, Dept D
WHERE D.mgr = E.ename
- Trình bày một trường hợp mà truy vấn đầu tiên thực hiện tốt hơn truy vấn thứ hai.
- Trình bày một trường hợp mà truy vấn thứ hai thực hiện tốt hơn truy vấn đầu tiên.
- Bạn có thể xây dựng một truy vấn bằng vượt trội cả hai truy vấn này khi tất cả nhân viên kiếm được hơn $100000 có tuổi là 35 hoặc 40? Giải thích ngắn gọn.
1. Xem xét trường hợp khi ở đây có rất ít hoặc không có nhân viên nào có lương lớn hơn 100000. Thì trong truy vấn thứ nhất phần lồng nhau sẽ không được tính, ngược lại trong truy vấn thứ hai phép nối giữa Emp và MgrAge sẽ được tính không kể đến số lượng các nhân viên có lương lớn hơn 100000.
Cũng như vậy, nếu ở đây có một chỉ mục trên dname, thì phần lồng nhau của truy vấn thứ nhất sẽ hiệu quả. Tuy nhiên, chỉ mục này không ảnh hưởng tới khung nhìn này trong truy vấn thứ hai vì nó được sử dụng từ một khung nhìn nào đó.
2. Trong trường hợp khi ở đây có một số lượng lớn các nhân viên có sal>100000 và quan hệ Dept lớn, trong truy vấn đầu tiên phép nối giữa Dept và Emp sẽ được tính cho mỗi bộ giá trị trong Emp thỏa mãn điều kiện E1.sal > 100000, ngược lại phép nối được tính chỉ một lần.
3. Trong trường hợp này, phép chọn liên quan đến age sẽ có chi phí rất cao. Vì thế nếu chúng ta có một chỉ mục trên <age, sal> thì truy vấn sau có thể thực hiện tốt hơn.
SELECT E1.ename
FROM Emp E1
WHERE E1.age=35 AND E1.sal > 100 AND E1.age =
( SELECT E2.age
FROM Emp E2, Dept D2
WHERE E1.dname = D2.dname AND D2.mgr = E2.ename)
UNION
SELECT E1.ename
FROM Emp E1
WHERE E1.age = 40 AND E1.sal > 100 AND E1.age =
( SELECT E2.age
FROM Emp E2, Dept D2
WHERE E1.dname = D2.dname AND D2.mgr = E2.ename)
Các câu hỏi ôn tập
Trả lời những câu hỏi sau và câu trả lời có thể tìm trong phần được liệt kê bên cạnh.
- Nêu các thành phần của luồng công việc? (Phần 1.1)
- Những quyết định nào cần phải được đưa ra trong quá trình thiết kế vật lý? (Phần 1.2)
- Trình bày sáu hướng dẫn mức-cao cho việc lựa chọn chỉ mục. (Phần 2)
- Khi nào chúng ta nên tạo ra các chỉ mục phân cụm? (Phần 4)
- Đồng-phân-cụm là gì, và khi nào chúng ta nên sử dụng nó? (Phần 4.1)
- Kế hoạch chỉ-chỉ-số là gì, và chúng ta tạo ra các chỉ mục cho các kế hoạch chỉ-chỉ-số như thế nào? (Phần 5)
- Vì sao điều chỉnh chỉ mục tự động là một vấn đề khó? Cho ví dụ. (Phần 6.1)
- Cung cấp một ví dụ cho thuật toán điều chỉnh chỉ mục tự động. (Phần 6.2)
- Vì sao điều chỉnh cơ sở dữ liệu quan trọng? (Phần 7)
- Chúng ta điều chỉnh chỉ mục, lược đồ khái niệm, các truy vấn và các khung nhìn như thế nào? (Từ phần 7.1 tới 7.3)
- Những lựa chọn của chúng ta trong việc điều chỉnh lược đồ khái niệm là gì? Các công nghệ theo sau nó là gì và khi nào chúng ta áp dụng chúng: chọn các dạng chuẩn yếu hơn, phi chuẩn hóa, phân rã theo chiều dọc và chiều ngang. (Phần 8)
- Những lựa chọn nào chúng ta làm trong điều chỉnh chỉ mục và khung nhìn? (Phần 9)
- Ảnh hưởng của khóa đối với thực thi cơ sở dữ liệu? Chúng ta có thể giảm sự tương tranh của khóa và các hot spots như thế nào? (Phần 10)
- Vì sao chúng ta có các tiêu chuẩn? Bạn có thể trình bày một vài tiêu chuẩn phổ dụng? (Phần 12)
Tài liệu tham khảo
[658] là những bàn luận ban đầu về thiết kế cơ sở dữ liệu vật lý. [659] bàn về chuẩn hóa và những quan sát về phi chuẩn hóa có thể cải thiện được khả năng thực thi của một số truy vấn. Các công cụ thiết kế vật lý của IBM được trình bày trong [272]. Công cụ Microsoft Auto Admin thực hiện lựa chọn chỉ mục tự động dựa theo luồng công việc được trình bày trong một số tài liệu [163, 164]. DB2 Advisor được trình bày trong [750]. Các cách tiếp cận khác của thiết kế cơ sở dữ liệu vật lý được trình bày trong [146, 639]. [679] xem xét việc điều chỉnh giao dịch, phần mà chúng ta mới chỉ trình bày một cách tóm tắt.
Những quyển sách sau trình bày chi tiết về thiết kế vật lý: chúng được đề nghị đọc thêm. [779] trình bày về DB2. Shasha & Bonnet cung cấp thông tin chi tiết hơn về điều chỉnh cơ sở dữ liệu [104].
[334] gồm một số bài báo về benchmarking và có một số phần mềm kèm theo. Nó bao gồm các bài báo về AS3AP, Set Query, TPC-A, TPC-B, Wisconsin, và tiêu chuẩn 001 được viết bởi những người phát triển đầu tiên. Bucky benchmark được trình bày trong [132], tiêu chuẩn 007 được trình bày trong [131], và tiêu chuẩn TPC-D được trình bày trong [739]. Tiêu chuẩn Sequoia 2000 được trình bày trong [720].